Arm Unveils 2023 Mobile CPU Core Designs: Cortex-X4, A720, and A520 - the Armv9.2 Family
by Gavin Bonshor on May 28, 2023 8:30 PM ESTNew DSU-120: More L3 Cache, Doubling Down on Efficiency
For the launch of its Armv9.2 architecture, Arm has decided to opt for a new core complex design for its TCS23 CPU cores by building upon the foundations of its current DSU-110 block. Initially introduced in 2017 along with the Cortex A75 and A55 cores, DSU-110 represented a significant redesign and generational shift to integrate larger pools of shared L3 cache, bandwidth, and scalability. Along with the efficiency tweaking Arm has done to its new Cortex-X4, Cortex-A720, and A520 cores, the new DynamIQ Shared Unit-120 (DSU-120) also plays a significant role in these advancements.

Building a more refined DSU instead of another ground-up design, Arm has made plenty of inroads to improving overall scalability, efficiency, and performance with its DSU-120. Some of the most notable improvements include support for up to 14 CPU cores in a single cluster, which allows SoC vendors to pick and choose their core cluster configurations to suit the device going to market. Arm has also improved its Power and Performance Area (PPA) by implementing new power-saving modes, including RAM and Slicing power-downs, which work in stages depending on the type of workload and the intensity to reduce the overall power footprint of the cluster.
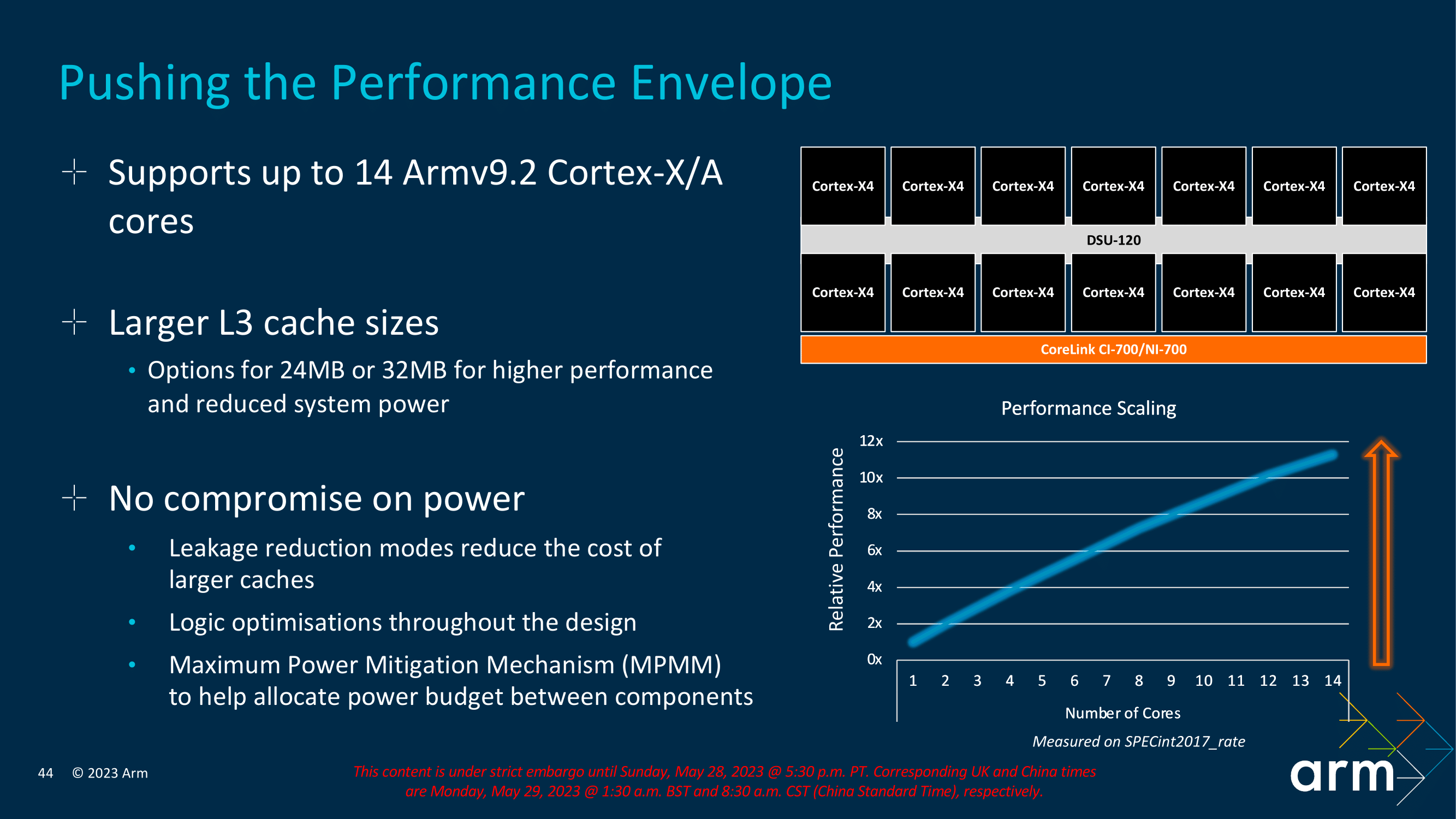
Perhaps the most significant change to DSU-120 from DSU-110 is that Arm has effectively doubled the total amount of shared L3 cache a cluster can implement. DSU-110 initially supported up to 16 MB, whereas DS-120 can now accommodate up to 32 MB of shared L3 cache across the entire complex, with other options also available, including 24 MB. While this isn't a direct implementation into the IP, the decision on the number of L3 cache implemented is entirely down to SoC vendors to decide the right levels of L3 cache based on performance and efficiency balancing depending on the device. The key focus is that DSU-120 and the new TCS23 cluster have the ability to support this if vendors wish to implement more L3 cache.
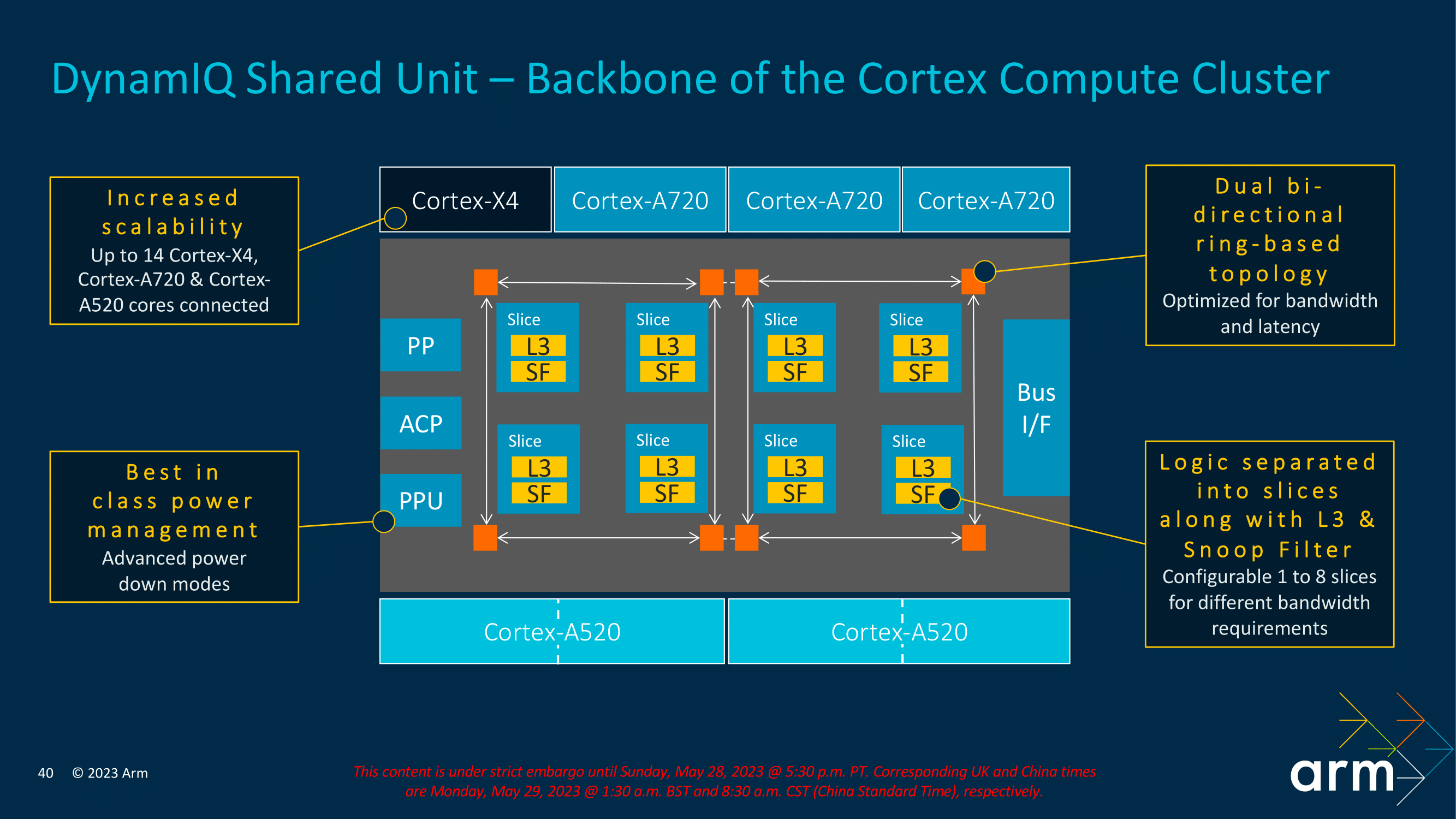
As with the current/previous DSU-110 interconnect, the new DSU-120 also uses a dual bi-directional ring-based topology, which allows data transmission in both directions within the cluster and reduces overall latency. The overall design of the DynamIQ Shared Unit is to optimize things for latency and increase bandwidth, which is precisely what Arm has done by slicing its logic L3 and snoop filters. As such, it is configurable based on specific customer bandwidth requirements. As previously mentioned, DSU-120 allows up to 14 Cortex-X/A cores to be implemented into a cluster, with plenty of benefits of opting for the latest Armv9.2 generation over the previous iterations.
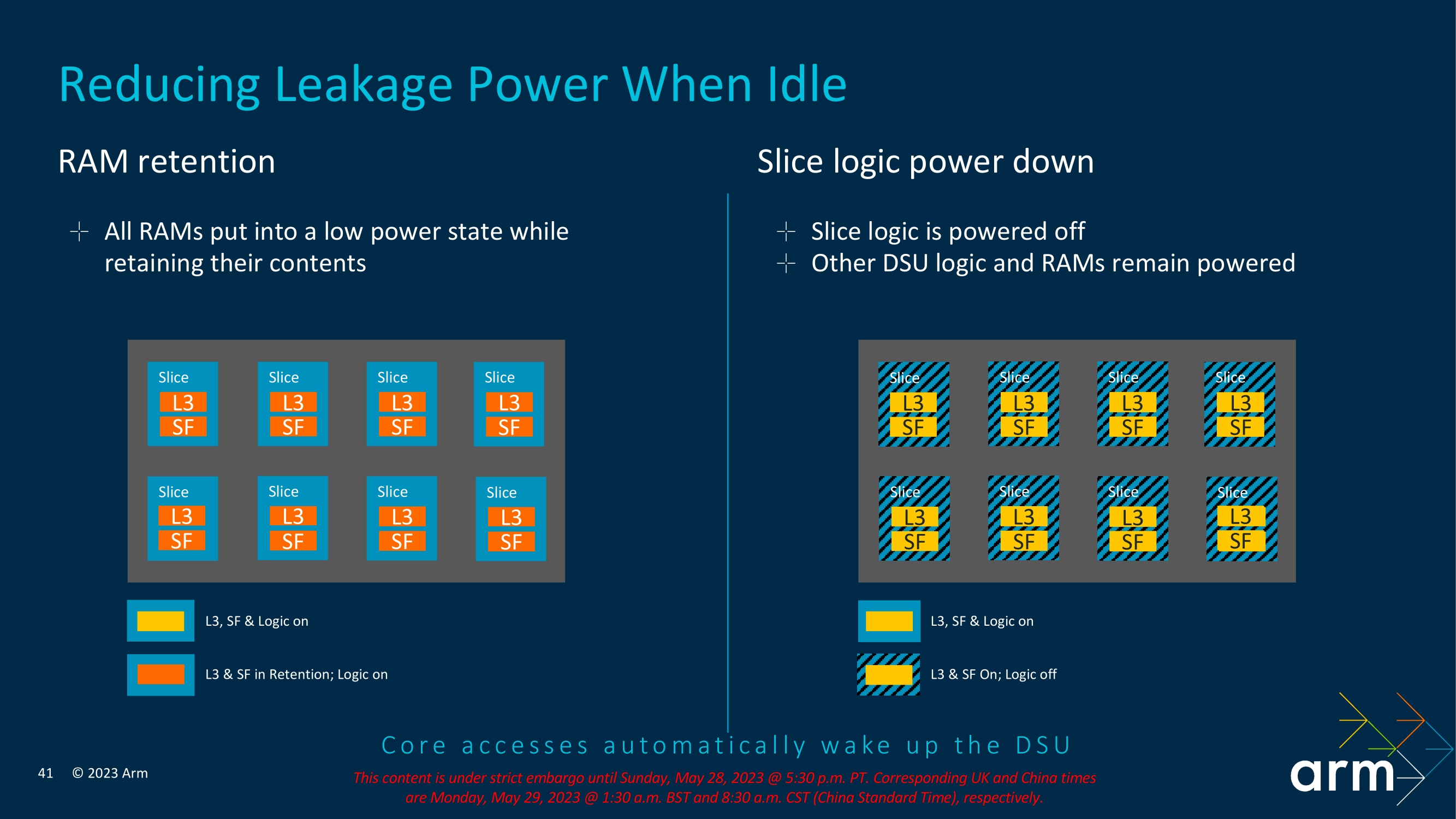
Focusing on the new power improvements to the TCS23 and DSU-120 complex, Arm has identified specific areas where it can save on power to maximize efficiency. One of these is through RAM and reducing any unnecessary power leakage associated with that. To combat this, Arm has opted for a mechanism that allows RAM to be placed into a low-powered state when not being actively used, but still with enough power to ensure the integrity of its contents. The Logic is split into slices with the L3 cache and a snoop filter designed to improve cache coherence within a multi-core complex.
Opting for a sliced approach with snoop filters enables a couple of things. Firstly as we've mentioned, it improves and enhances cache coherence. This means that the cores are fed consistently and up-to-date instructions, and the snoop filter itself is designed to filter out requests that are deemed unnecessary, which does give some efficiency benefits. Secondly, slicing allows Arm's IP to increase scalability, which with an increase in cores, means an increase in slices with dedicated cache slices, allowing for better distribution of data and lower data contention rates. Armv9.2 IP with the DSU-120 allows for between 1 and 8 slices to be used, designed to enable SoC vendors the flexibility to work within their bandwidth requirements.

Arm claims that RAM power-down enabled across half of the L3 RAMs on the complex is suitable for large L3 caches when all of the capacity isn't being used. By allowing RAM power-down, all of the unused RAM is put into a low power state, but with enough to keep the contents and withhold their integrity within the memory substructure. Even with RAM and Slice power-downs active, the cores can still be active and process relevant instructions and data. One slice will effectively remain active, which is ideal for smaller and light workloads on a single core, but when it comes to powering down features on the DSU-120 interconnect, accessing the cores will enact a wake-up of the DSU-120.
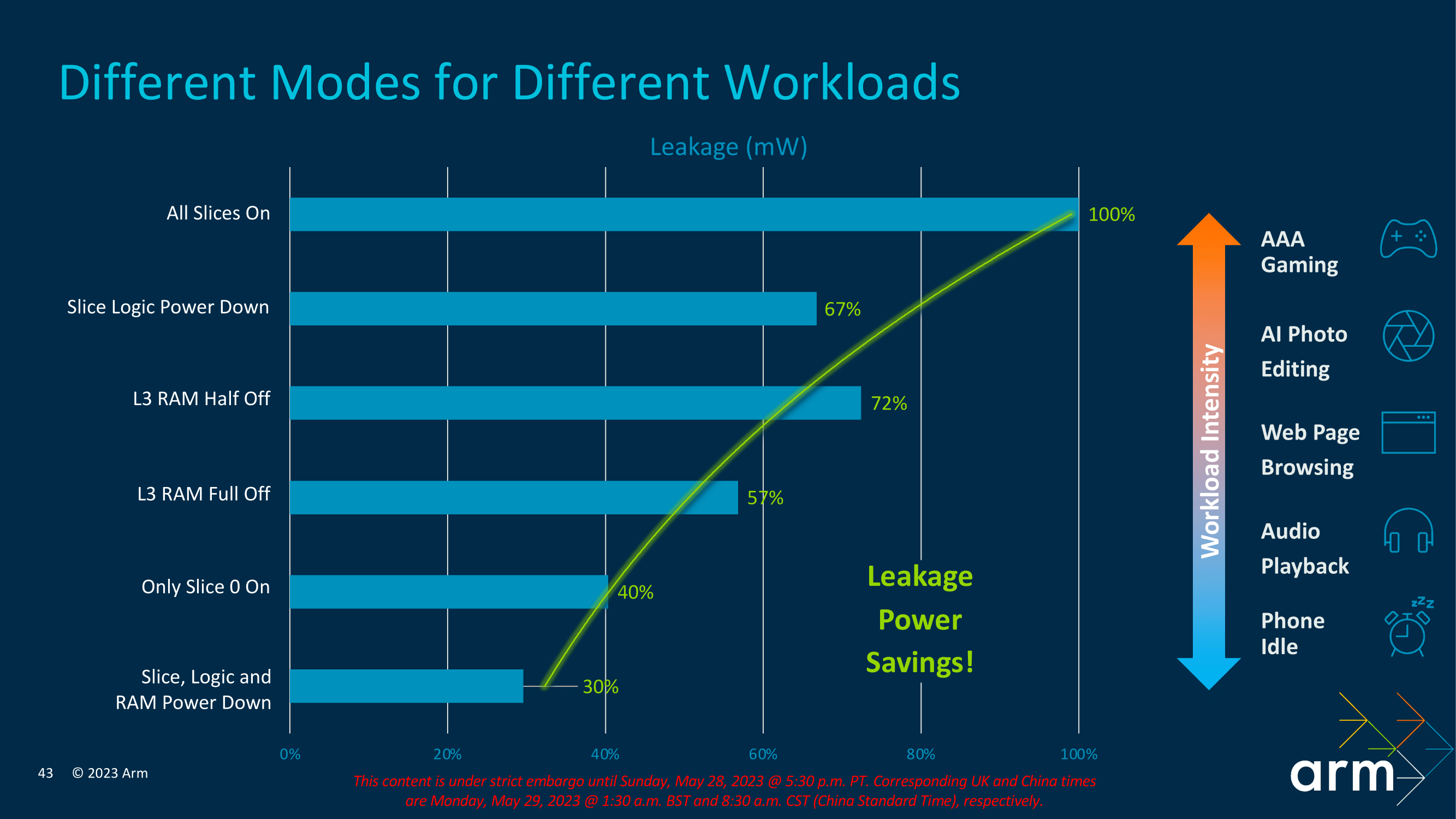
Looking at how this efficiency translates into data, Arm has provided a handy slide with estimates from its own testing. As we can see, with various levels of RAM and Slice Logic power-downs, we get varied potential power savings, which can then be budgeted back into the cores themselves for higher performance levels. Different workloads and tasks require different levels of core power, coherence, intensity, and L3 allocation, so different power-downs lead to varying levels of leakage and power efficiency savings. Arm's figures estimate between 30 and 72% at the other states of power-down, with 100% savings in leakage with all the slices enabled.








52 Comments
View All Comments
Ryan Smith - Thursday, June 1, 2023 - link
Yes, there will be. The embargo lining up with Computex stretched us a bit thin, so the GPU stuff has been punted to next week.ikjadoon - Saturday, June 3, 2023 - link
LOVE to read an in-depth article like this on AnandTech again!Give us more!!