Arm Unveils 2023 Mobile CPU Core Designs: Cortex-X4, A720, and A520 - the Armv9.2 Family
by Gavin Bonshor on May 28, 2023 8:30 PM ESTNew DSU-120: More L3 Cache, Doubling Down on Efficiency
For the launch of its Armv9.2 architecture, Arm has decided to opt for a new core complex design for its TCS23 CPU cores by building upon the foundations of its current DSU-110 block. Initially introduced in 2017 along with the Cortex A75 and A55 cores, DSU-110 represented a significant redesign and generational shift to integrate larger pools of shared L3 cache, bandwidth, and scalability. Along with the efficiency tweaking Arm has done to its new Cortex-X4, Cortex-A720, and A520 cores, the new DynamIQ Shared Unit-120 (DSU-120) also plays a significant role in these advancements.

Building a more refined DSU instead of another ground-up design, Arm has made plenty of inroads to improving overall scalability, efficiency, and performance with its DSU-120. Some of the most notable improvements include support for up to 14 CPU cores in a single cluster, which allows SoC vendors to pick and choose their core cluster configurations to suit the device going to market. Arm has also improved its Power and Performance Area (PPA) by implementing new power-saving modes, including RAM and Slicing power-downs, which work in stages depending on the type of workload and the intensity to reduce the overall power footprint of the cluster.
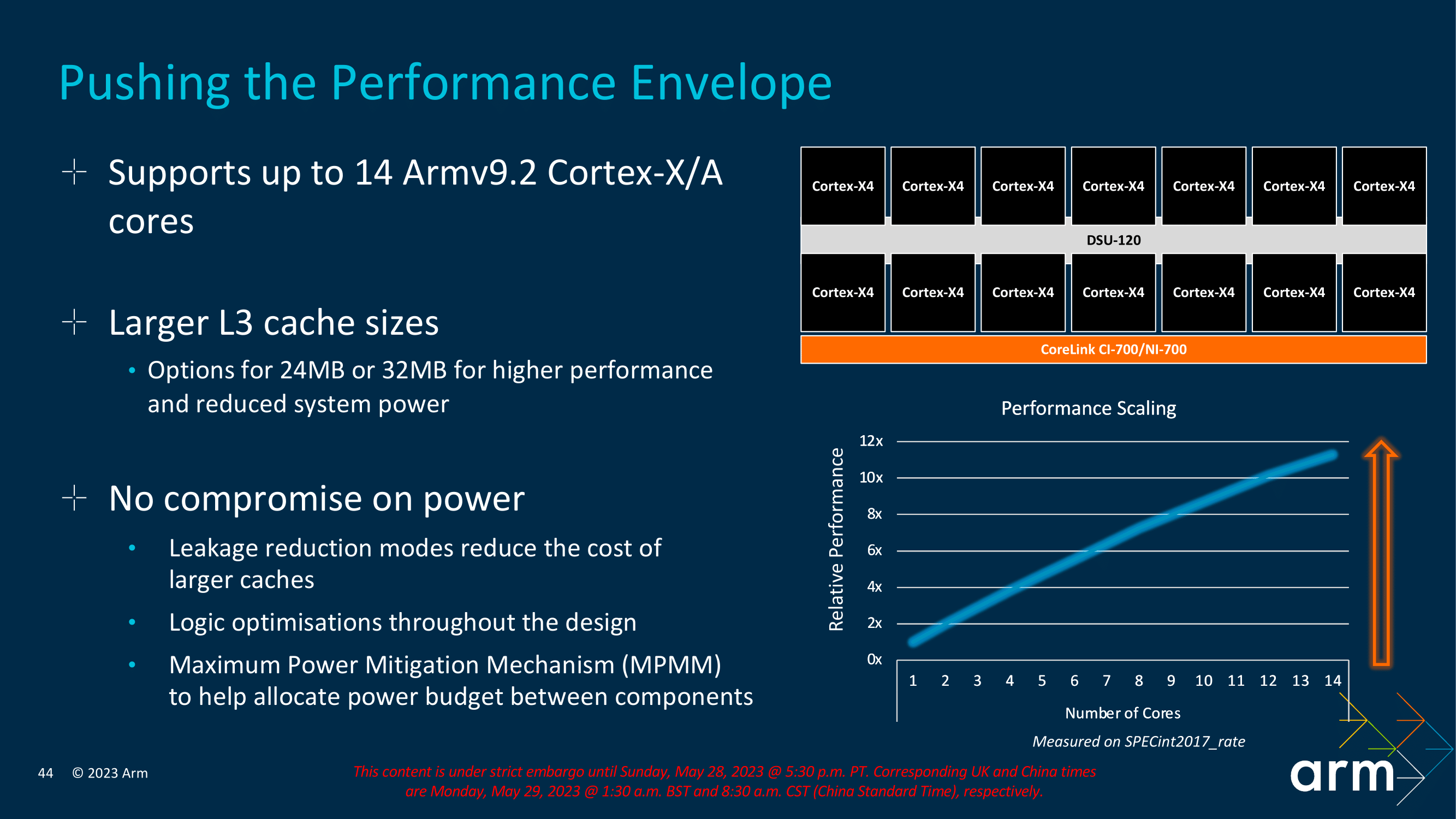
Perhaps the most significant change to DSU-120 from DSU-110 is that Arm has effectively doubled the total amount of shared L3 cache a cluster can implement. DSU-110 initially supported up to 16 MB, whereas DS-120 can now accommodate up to 32 MB of shared L3 cache across the entire complex, with other options also available, including 24 MB. While this isn't a direct implementation into the IP, the decision on the number of L3 cache implemented is entirely down to SoC vendors to decide the right levels of L3 cache based on performance and efficiency balancing depending on the device. The key focus is that DSU-120 and the new TCS23 cluster have the ability to support this if vendors wish to implement more L3 cache.
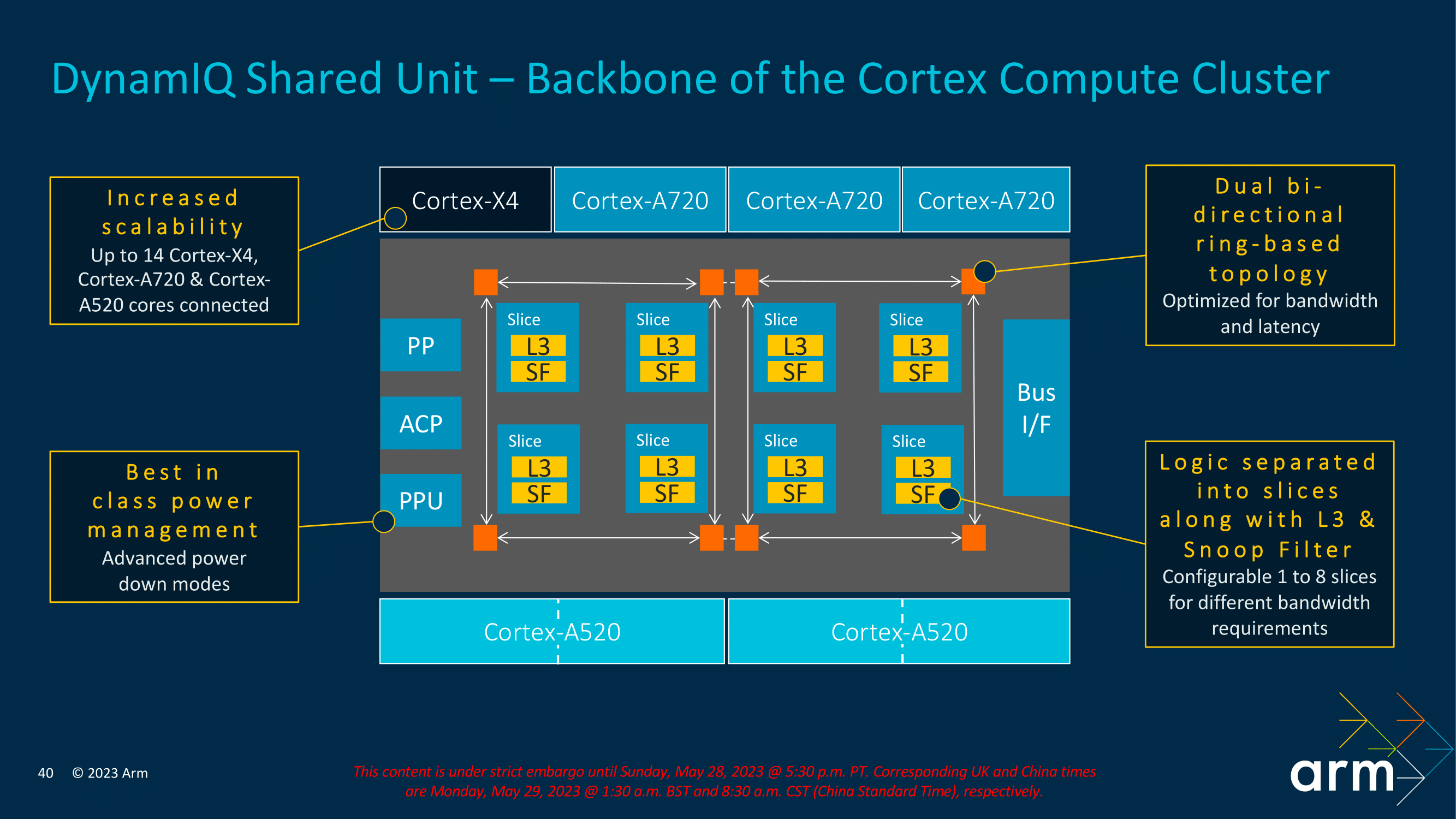
As with the current/previous DSU-110 interconnect, the new DSU-120 also uses a dual bi-directional ring-based topology, which allows data transmission in both directions within the cluster and reduces overall latency. The overall design of the DynamIQ Shared Unit is to optimize things for latency and increase bandwidth, which is precisely what Arm has done by slicing its logic L3 and snoop filters. As such, it is configurable based on specific customer bandwidth requirements. As previously mentioned, DSU-120 allows up to 14 Cortex-X/A cores to be implemented into a cluster, with plenty of benefits of opting for the latest Armv9.2 generation over the previous iterations.
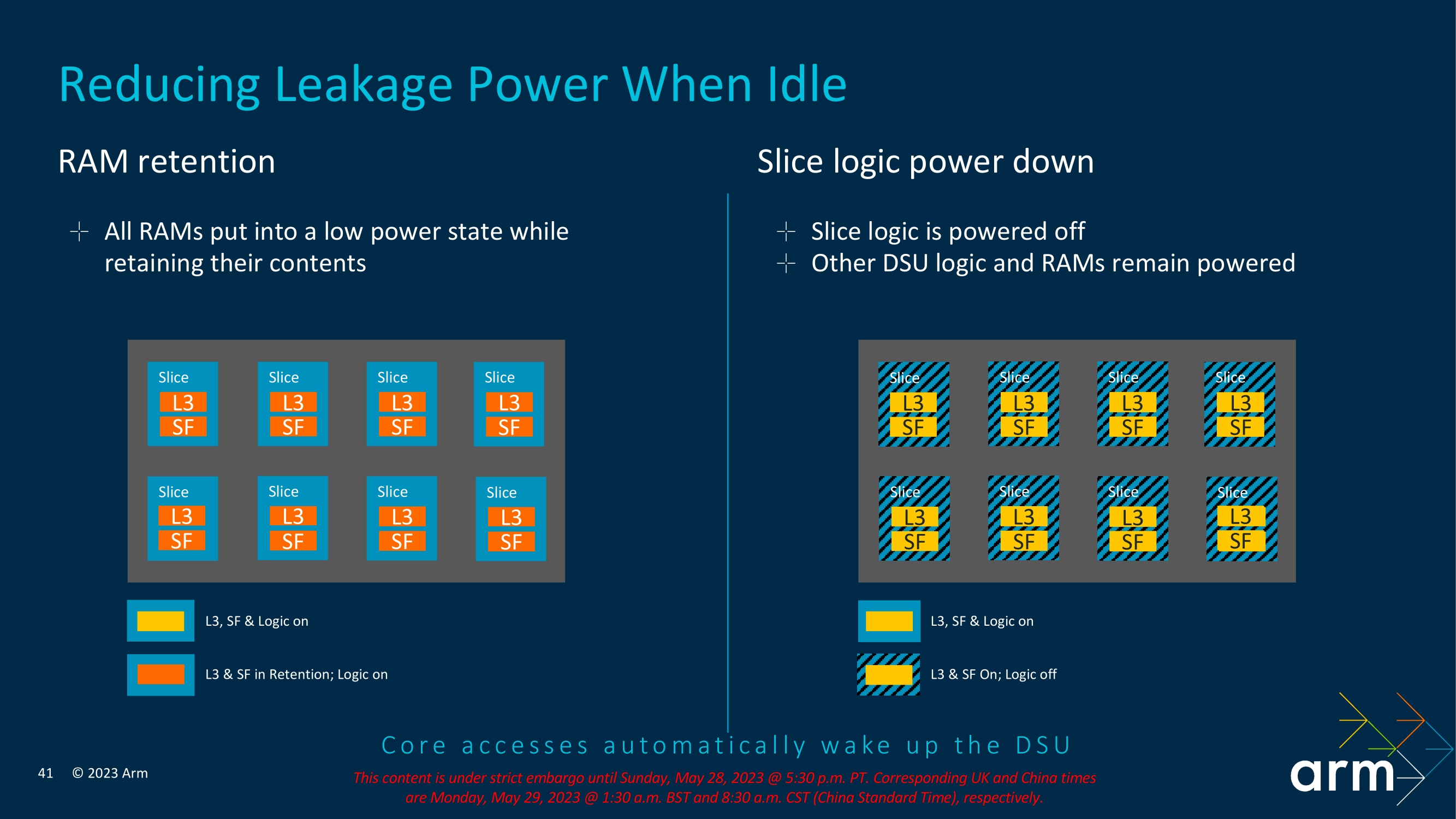
Focusing on the new power improvements to the TCS23 and DSU-120 complex, Arm has identified specific areas where it can save on power to maximize efficiency. One of these is through RAM and reducing any unnecessary power leakage associated with that. To combat this, Arm has opted for a mechanism that allows RAM to be placed into a low-powered state when not being actively used, but still with enough power to ensure the integrity of its contents. The Logic is split into slices with the L3 cache and a snoop filter designed to improve cache coherence within a multi-core complex.
Opting for a sliced approach with snoop filters enables a couple of things. Firstly as we've mentioned, it improves and enhances cache coherence. This means that the cores are fed consistently and up-to-date instructions, and the snoop filter itself is designed to filter out requests that are deemed unnecessary, which does give some efficiency benefits. Secondly, slicing allows Arm's IP to increase scalability, which with an increase in cores, means an increase in slices with dedicated cache slices, allowing for better distribution of data and lower data contention rates. Armv9.2 IP with the DSU-120 allows for between 1 and 8 slices to be used, designed to enable SoC vendors the flexibility to work within their bandwidth requirements.

Arm claims that RAM power-down enabled across half of the L3 RAMs on the complex is suitable for large L3 caches when all of the capacity isn't being used. By allowing RAM power-down, all of the unused RAM is put into a low power state, but with enough to keep the contents and withhold their integrity within the memory substructure. Even with RAM and Slice power-downs active, the cores can still be active and process relevant instructions and data. One slice will effectively remain active, which is ideal for smaller and light workloads on a single core, but when it comes to powering down features on the DSU-120 interconnect, accessing the cores will enact a wake-up of the DSU-120.
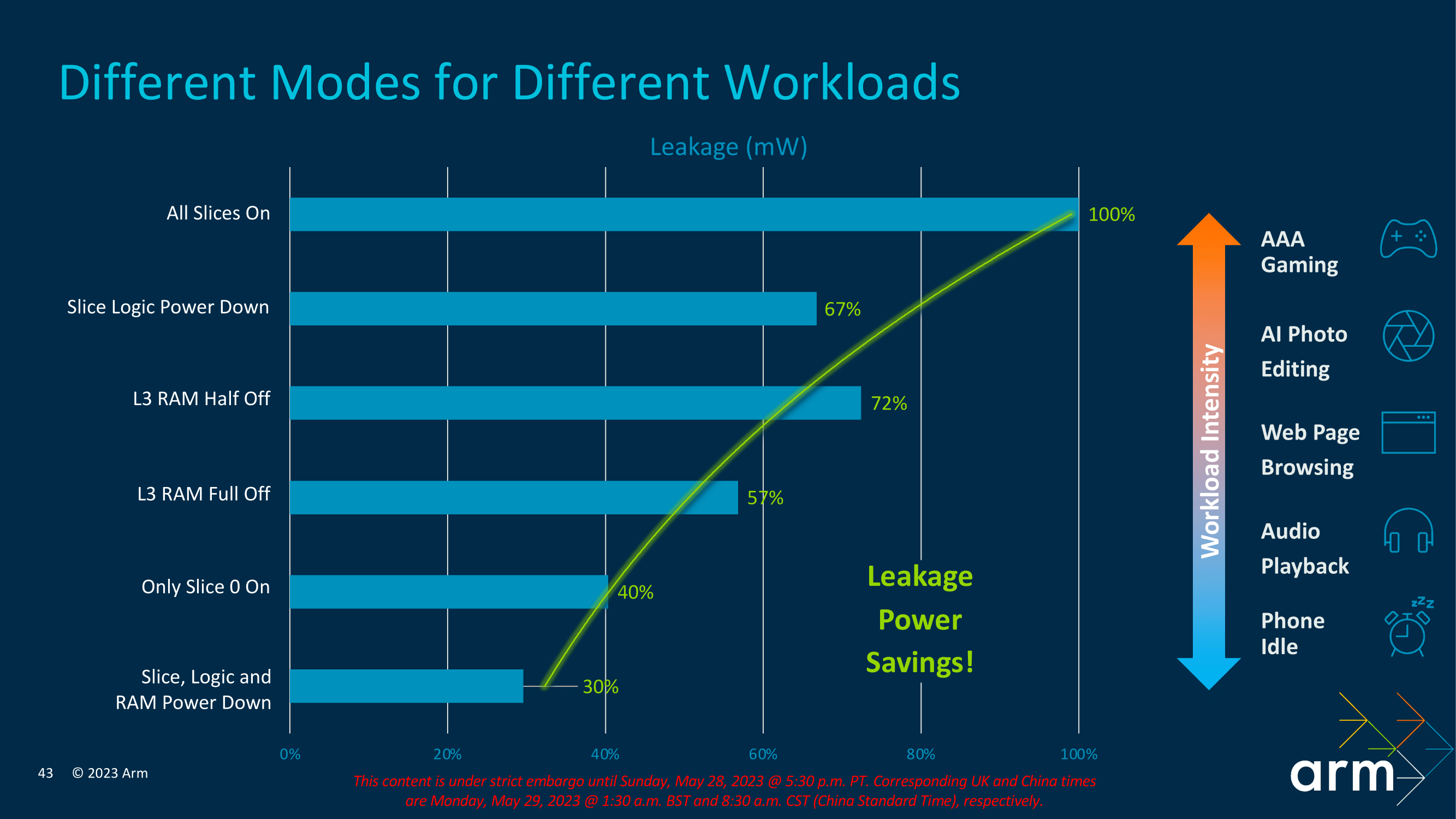
Looking at how this efficiency translates into data, Arm has provided a handy slide with estimates from its own testing. As we can see, with various levels of RAM and Slice Logic power-downs, we get varied potential power savings, which can then be budgeted back into the cores themselves for higher performance levels. Different workloads and tasks require different levels of core power, coherence, intensity, and L3 allocation, so different power-downs lead to varying levels of leakage and power efficiency savings. Arm's figures estimate between 30 and 72% at the other states of power-down, with 100% savings in leakage with all the slices enabled.








52 Comments
View All Comments
Kangal - Monday, May 29, 2023 - link
I also forgot to mention, we've had leaks for more than a year about ARMv9 and their Second-Gen cores. They were promised with a sizeable performance improvement at a reduced power draw.Turns out the rumours were not correct. Well sort of. We assumed the advances came just from the architecture but that's not it. We're seeing a modest improvement in the architecture, and the benefits coming from a number of other factors. They're relying on a new DynamIQ setup, more cache, faster memory, all mixing together to have an overall notable improvement. Going 64bit-only in microcode will have unseen benefits too. And the elephant in the room is the jump to TSMC-3NM node shrink, which will likely have frequency increases.
So comparing the QC 8g1 (Samsung 5nm) to the (TSMC-5nm) QC 8g1+ and QC 8g2 (+5nm-TSMC) and (TSMC-3NM) QC 8g3 will be a mixed bag.
Kangal - Monday, May 29, 2023 - link
A TCS23 (X4+720+520) with 1+5+2 configuration, only yields a +27% performance uplift at the same power, compared to TCS22 (X3+715+510) in 1+3+4 cluster.Something is miscalculated there!!!
They either mean:
1) TCS23 vs TCS23, with only difference being different configuration
2) TCS22 vs TCS22, with only difference being different configuration
3) TCS22 vs TCS23, and they meant PLUS an extra +27% performance on top of the architectural improvements
4) It's not a typo, and they really did mean you ONLY get +27% uplift total. Which doesn't make sense since they claimed the X4 uses -40% less energy than X3, whilst the A720 uses -20% less energy than A715, and the A520 uses -22% less energy than A530. Logically speaking if you just multiply the efficiency gains by the core quantities you get an impressive figure. Unless you divide that by the total cores, that gives you an average drop by -23% energy, but that's not the total. Unless the engineers or the marketers are utterly incompetent there at ARM, and they meant this -23% figure gets increased to -27% figure (+4% efficiency gain) just based on the cluster configuration difference. That's not a great improvement, it's negligible, and not substantial enough to require a new silicon stamp (which explains MediaTek).
1x40% + 5x20% + 2x22% = 184% / 8 = 23%
Doug_S - Monday, May 29, 2023 - link
There are so many factors changing like more L2 cache, supporting more L3 cache, faster memory, better processes and they don't tell you anything about what the differences are.If they said X3 with x cache, y DRAM on process z was compared to X3 with x cache, y DRAM on process z then you could assume the performance uplift was due to their architecture. But they are turning all those knobs so who knows what improvement comes from the core versus what is around the core and what node it is on.
Doug_S - Monday, May 29, 2023 - link
Ugh I meant X3 compared to X4 of course.Kangal - Tuesday, May 30, 2023 - link
I got that, but the architecture has been rather since the Cortex-A78. Just like how there was a long period of time since the release of the Cortex-A57 compared to the Cortex-A72. That extra time let ARM make a lot of big architectural improvements. In fact, it was pretty lengthy that we got Custom Cores developed by the likes of Nvidia, Qualcomm, Samsung, all which were vastly superior to the Cortex-A57 and they matched the subsequent release of the Cortex-A72.My biggest concern is the mistakes in their slides.
If you have a 1+3+4 TCS22 design, and you do nothing but change the A510 to A520, you should see an upgrade of 22% per core. So 22% x4 should see a +88% uptick in performance. Now compare that to the mere 27% upgrade they said if you upgraded all the core types (X4 / A720 / A520) and you went with a larger chipset with the 1+5+2 design. Something is clearly amiss.
Another solution to the riddle is they are using the problematic silicon from Samsung-5nm. Making a comparison between the flawed QC 8g1, against a new chipset using the same node, but upgrading the Core-types and the Cluster-design. Even then it's a bad excuse, because that would mean its barely competing against the 6-month old QC 8g2 (on TSMC node), and we collectively just ignore the existence of the MediaTek Dimensity chipsets.
I think we will have to wait to hear the announcement of next-gen chips for 2024, in the form of QC 8g3 and MTK D9400. Let's see their claimed battery life improvement, their performance improvement, and deduce the efficiency from there. Look at which silicon they're building upon (TSMC 4nm vs 5nm). And finally look at the in depth reviews from the likes of Anandtech/Andrei, Geekerwan, and Golden Reviewer.
iphonebestgamephone - Wednesday, May 31, 2023 - link
Techtechpotato instead of anandtech/andreiFindecanor - Monday, May 29, 2023 - link
ARM MTE and PAC are two different things, and I find it really silly to see them touted for use together.MTE steals eight pointer bits that would have been used for PAC, and on some implementations the bits for PAC would then be as few as 3.
You would better pick one or the other, depending on your protection scheme.
syxbit - Monday, May 29, 2023 - link
So Arm are still years behind Apple? And possibly will be slower than Nuvia too?I guess this just helps QUalcomm, as smaller companies have no choice. Either use slow off the shelf parts, or pay QCOMM for their superior chip (assuming Nuvia is as good as claimed.).
DanNeely - Thursday, June 1, 2023 - link
Blame some of the mainland China android forks. They've spent years trying to pretend 64 bit only was never going to happen and were nowhere near ready when last years x3 dropped support for 32 bit code.Arnulf - Monday, May 29, 2023 - link
"up for the 6/8-wide dispatch with of the X3"From ... width