Arm Unveils 2023 Mobile CPU Core Designs: Cortex-X4, A720, and A520 - the Armv9.2 Family
by Gavin Bonshor on May 28, 2023 8:30 PM ESTCortex-A720: Middle Core, Big on Efficiency
Focusing on Arm's latest middle core, the Cortex-A720 hasn't changed much from the previous Cortex A715 design last year, which was also Arm's first AArch64-only middle core. Arm has a set philosophy for its A700 family, and that's mostly about increasing performance through optimizations, delivering maximum levels of power efficiency within set thermal limits, and optimizing workloads for actual use cases instead of blisteringly fast benchmark performance. Arm's key aims are to enhance performance metrics while maintaining power efficiency, area, and all within an acceptable thermal envelope. Cost is also essential, with many entry-level mobile devices already on the market leveraging the Cortex A700 family for its main cores.

Similar to the Cortex-X4 in that the Cortex-A720 is built around the Armv9.2 ISA, Arm has optimized its design to enable the A720 to deliver more performance within the same power budget compared to the Cortex A715. The Arm 700-series family typically covers a much broader range of applications and caters to various markets, including, and not limited to, digital TVs (DTV), smartphones, and laptops. Having more comprehensive flexibility in a more diverse space has its advantages, and Arm looks to capitalize on that with the Cortex-A720 acting as the 'workhorse' of the TSC23 core cluster.
Devices such as smartphones at the entry-level typically want to reduce cost but maximize performance and efficiency, and that's where cores such as the Cortex-A720 come into play; the Cortex-X4 is primarily allocated to devices with flagship status or those that require the most burst and sustained performance, such as top tier smartphones, tablets, and laptops. Meanwhile, Cortex-A720 is the next step down, giving up the X4's high peak performance for a much smaller core size and with correspondingly lower energy consumption.
For the Cortex-A720 in particular, Arm is also offering multiple configuration options. Along with the standard, highest-performing option, Arm has what they're terming an "entry-tier" configuration that shaves A720 down to the same size as Arm Cortex-A78, all while still offering a 10% uplift in overall performance. With some Arm customers being especially austere on die sizes, moves such as these are necessary to convince them to finally make the jump over to the Cortex-A7xx series and Armv9.
Arm's focus is to broaden the range of the entry-level market and expand on the possible use cases for its Cortex-A720 core so that it can be implemented into a wider variety of entry-level mobile devices and in lower-end markets.

Some of the critical improvements to the Cortex-A720, when compared to the previous A715, is Arm has opted for a faster branch mispredict recovery. Branch prediction breaks down the instructions into predicates, and a branch predictor will only execute statements it predicates to be true. Opting for a faster branch mispredict recovery has multiple benefits, as it not only reduces the delay within the execution of instructions, but it can improve overall performance. Another element of this is pipeline efficiency, as a branch misprediction can disrupt the flow of instruction throughout the pipeline, and the ability to do this faster not only yields benefits to performance but also to overall power efficiency.

Arm has reduced the overall branch mispredict penalty on A720 to 11 cycles, down from 12 on the Cortex A715. They have also improved upon their 2-taken branch prediction technique, which predicts the outcome of the instruction, and, again, adds efficiency to the pipeline and reduces the penalties regarding misprediction.
Another improvement is the Pipelined FDIV/FSQRT (division + square root), which performs operations on floating point numbers using the pipelines. Allowing for concurrent executions of both FDI and FSQRT can improve instruction throughput, and Arm claims to have achieved a significant speed boost without impacting the overall area. There are also faster transfers from floating point to floating point, including NEON and SVE2 integer, which Arm introduced for Armv9. This also includes overall improvements to issue queues and the execution units, which simplifies the forwarding of data forwarding to AGUs.

Within the memory system of the Cortex-A720, reduced the L2 cache latency to 9-cycles, and Arm claims to have up to 2x the memset(0) bandwidth within the L2 cache. Without going into much detail about their methods, Arm also claims to have improved generationally on accuracy and coverage to the prefetcher. However, it has a new L2 spatial prefetch engine, which was previously a pioneering Cortex-X core system design feature.
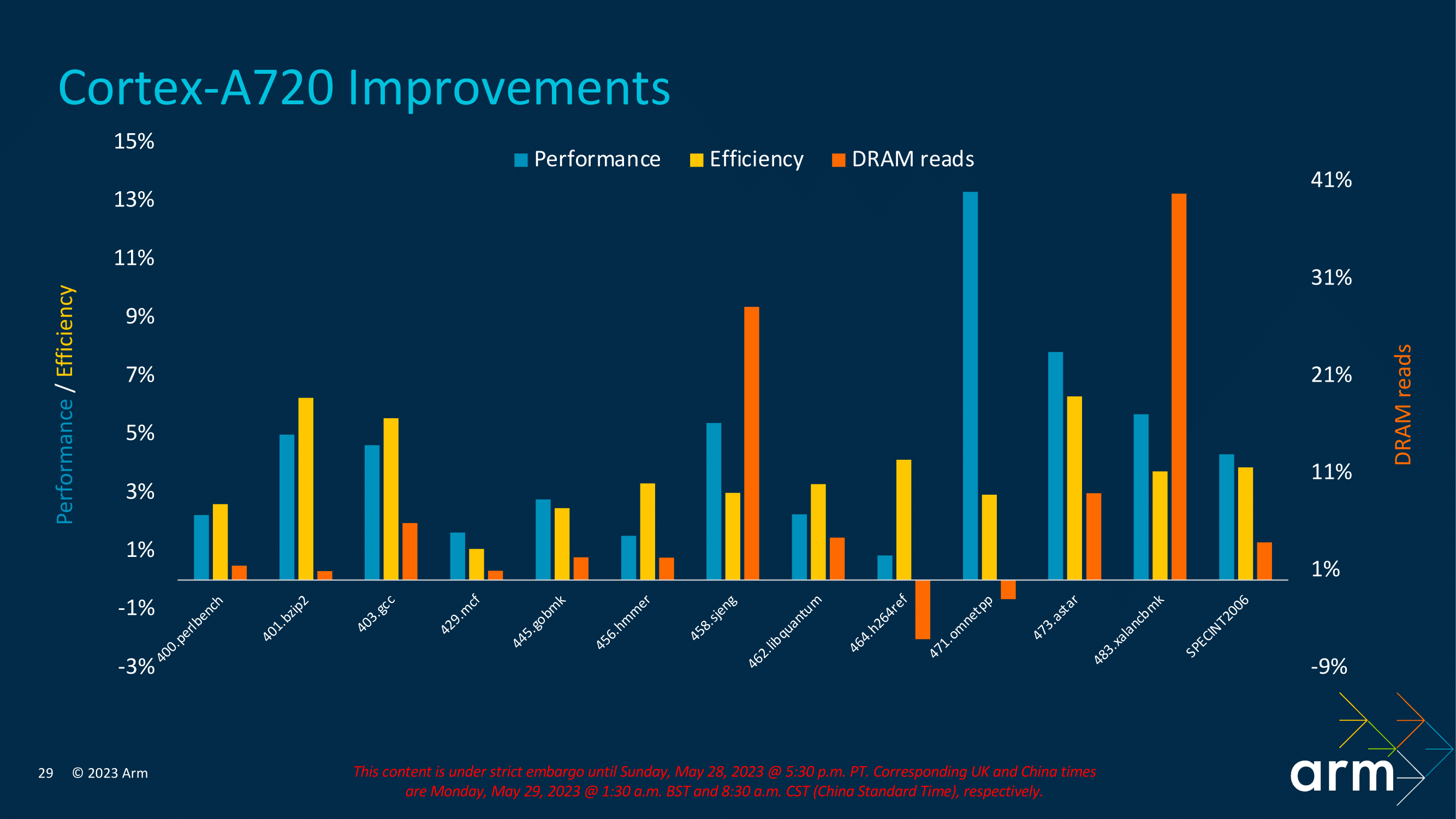
Translating the refinements and improvements to performance, Arm estimates the performance uplift to be about 15% at iso-frequency, depending on the workload. Among other benchmarkmarks, thare are clear gains over the previous generation in SPECint2017 and improvements within internal testing with SPECint2006. For example, using SPECint2007 as its performance indication metric in SPECint2007_403.gcc, the Cortex-A720 has a gain of around 5% over the Cortex A715, with an even more significant improvement of about 6% in power efficiency.
Other performance metrics on offer include DRAM reads, which Arm has focused a lot of attention on making more efficient, showing minor gains overall; SPEC2007int_483.xalacbmk shows a massive increase of up to 41% in DRAM read performance. While everything is relative and subjective to the workload tasked, Arm has made some clear forward progress with its latest Cortex-A720 CPU core microarchitecture.








52 Comments
View All Comments
Kangal - Monday, May 29, 2023 - link
I also forgot to mention, we've had leaks for more than a year about ARMv9 and their Second-Gen cores. They were promised with a sizeable performance improvement at a reduced power draw.Turns out the rumours were not correct. Well sort of. We assumed the advances came just from the architecture but that's not it. We're seeing a modest improvement in the architecture, and the benefits coming from a number of other factors. They're relying on a new DynamIQ setup, more cache, faster memory, all mixing together to have an overall notable improvement. Going 64bit-only in microcode will have unseen benefits too. And the elephant in the room is the jump to TSMC-3NM node shrink, which will likely have frequency increases.
So comparing the QC 8g1 (Samsung 5nm) to the (TSMC-5nm) QC 8g1+ and QC 8g2 (+5nm-TSMC) and (TSMC-3NM) QC 8g3 will be a mixed bag.
Kangal - Monday, May 29, 2023 - link
A TCS23 (X4+720+520) with 1+5+2 configuration, only yields a +27% performance uplift at the same power, compared to TCS22 (X3+715+510) in 1+3+4 cluster.Something is miscalculated there!!!
They either mean:
1) TCS23 vs TCS23, with only difference being different configuration
2) TCS22 vs TCS22, with only difference being different configuration
3) TCS22 vs TCS23, and they meant PLUS an extra +27% performance on top of the architectural improvements
4) It's not a typo, and they really did mean you ONLY get +27% uplift total. Which doesn't make sense since they claimed the X4 uses -40% less energy than X3, whilst the A720 uses -20% less energy than A715, and the A520 uses -22% less energy than A530. Logically speaking if you just multiply the efficiency gains by the core quantities you get an impressive figure. Unless you divide that by the total cores, that gives you an average drop by -23% energy, but that's not the total. Unless the engineers or the marketers are utterly incompetent there at ARM, and they meant this -23% figure gets increased to -27% figure (+4% efficiency gain) just based on the cluster configuration difference. That's not a great improvement, it's negligible, and not substantial enough to require a new silicon stamp (which explains MediaTek).
1x40% + 5x20% + 2x22% = 184% / 8 = 23%
Doug_S - Monday, May 29, 2023 - link
There are so many factors changing like more L2 cache, supporting more L3 cache, faster memory, better processes and they don't tell you anything about what the differences are.If they said X3 with x cache, y DRAM on process z was compared to X3 with x cache, y DRAM on process z then you could assume the performance uplift was due to their architecture. But they are turning all those knobs so who knows what improvement comes from the core versus what is around the core and what node it is on.
Doug_S - Monday, May 29, 2023 - link
Ugh I meant X3 compared to X4 of course.Kangal - Tuesday, May 30, 2023 - link
I got that, but the architecture has been rather since the Cortex-A78. Just like how there was a long period of time since the release of the Cortex-A57 compared to the Cortex-A72. That extra time let ARM make a lot of big architectural improvements. In fact, it was pretty lengthy that we got Custom Cores developed by the likes of Nvidia, Qualcomm, Samsung, all which were vastly superior to the Cortex-A57 and they matched the subsequent release of the Cortex-A72.My biggest concern is the mistakes in their slides.
If you have a 1+3+4 TCS22 design, and you do nothing but change the A510 to A520, you should see an upgrade of 22% per core. So 22% x4 should see a +88% uptick in performance. Now compare that to the mere 27% upgrade they said if you upgraded all the core types (X4 / A720 / A520) and you went with a larger chipset with the 1+5+2 design. Something is clearly amiss.
Another solution to the riddle is they are using the problematic silicon from Samsung-5nm. Making a comparison between the flawed QC 8g1, against a new chipset using the same node, but upgrading the Core-types and the Cluster-design. Even then it's a bad excuse, because that would mean its barely competing against the 6-month old QC 8g2 (on TSMC node), and we collectively just ignore the existence of the MediaTek Dimensity chipsets.
I think we will have to wait to hear the announcement of next-gen chips for 2024, in the form of QC 8g3 and MTK D9400. Let's see their claimed battery life improvement, their performance improvement, and deduce the efficiency from there. Look at which silicon they're building upon (TSMC 4nm vs 5nm). And finally look at the in depth reviews from the likes of Anandtech/Andrei, Geekerwan, and Golden Reviewer.
iphonebestgamephone - Wednesday, May 31, 2023 - link
Techtechpotato instead of anandtech/andreiFindecanor - Monday, May 29, 2023 - link
ARM MTE and PAC are two different things, and I find it really silly to see them touted for use together.MTE steals eight pointer bits that would have been used for PAC, and on some implementations the bits for PAC would then be as few as 3.
You would better pick one or the other, depending on your protection scheme.
syxbit - Monday, May 29, 2023 - link
So Arm are still years behind Apple? And possibly will be slower than Nuvia too?I guess this just helps QUalcomm, as smaller companies have no choice. Either use slow off the shelf parts, or pay QCOMM for their superior chip (assuming Nuvia is as good as claimed.).
DanNeely - Thursday, June 1, 2023 - link
Blame some of the mainland China android forks. They've spent years trying to pretend 64 bit only was never going to happen and were nowhere near ready when last years x3 dropped support for 32 bit code.Arnulf - Monday, May 29, 2023 - link
"up for the 6/8-wide dispatch with of the X3"From ... width