Intel Core i9-13900K and i5-13600K Review: Raptor Lake Brings More Bite
by Gavin Bonshor on October 20, 2022 9:00 AM ESTCore-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
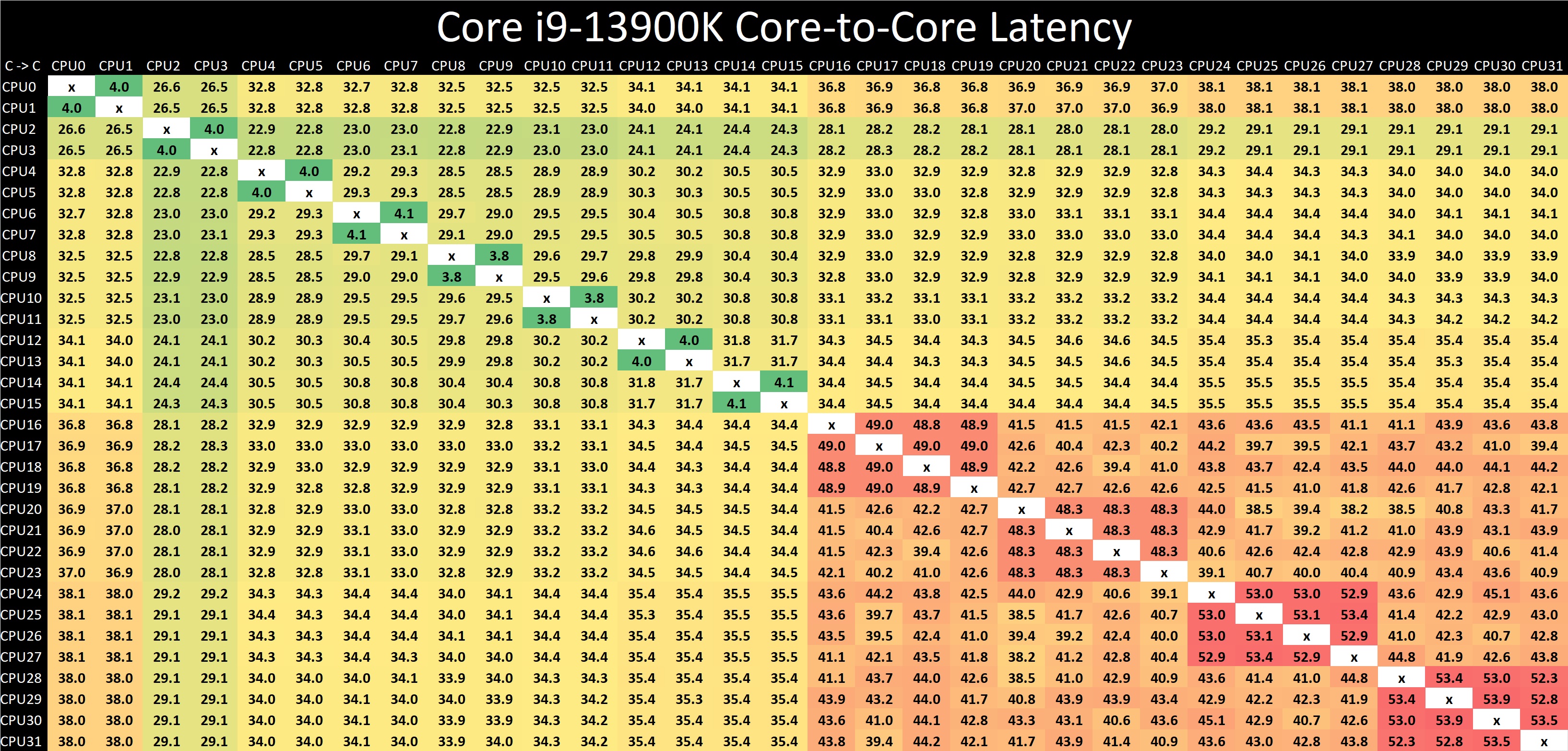
(Click on image to enlarge)
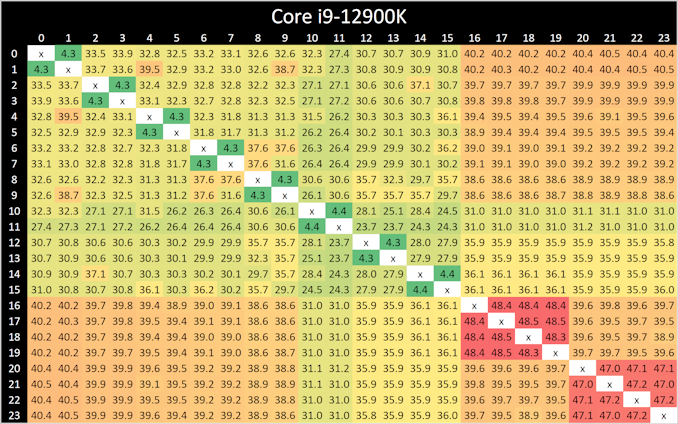
Looking at core-to-core latencies going from Alder Lake (12th Gen) to Raptor Lake (13th Gen), things look quite similar on the surface. The P-cores are listed within Windows 11 from cores 0 to 15, and in comparison to Alder Lake, latencies are much the same as what we saw when we reviewed the Core i9-12900K last year. The same comments apply here as with the Core i9-12900K, as we again see more of a bi-directional cache coherence.
Latencies between each Raptor Cove core have actually improved when compared to the Golden Cove cores on Alder Lake from 4.3/4.4 ns, down to 3.8/4.1 ns per each L1 access point.
The biggest difference is the doubling of the E-cores (Gracemont) on the Core i9-13900K, which as a consequence, adds more paths and crossovers. These paths do come with a harsher latency penalty than we saw with the Core i9-12900K, with latencies around the E-cores ranging from 48 to 54 ns within four core jumps between them; this is actually slower than it was on Alder Lake.
One possible reason for the negative latency is the 200 MHz reduction in base frequency on the Gracemont cores on Raptor Lake when compared with Alder Lake. When each E-core (Gracemont) core is communicating with each other, they travel through the L2 cache clusters via the L3 cache ring and back again, which does seem quite an inefficient way to go.








169 Comments
View All Comments
Pjotr - Thursday, October 20, 2022 - link
Closing thoughts typos: Ryzen 580X3D and Ryzen 700. ReplyRyan Smith - Thursday, October 20, 2022 - link
Thanks! Replymode_13h - Thursday, October 20, 2022 - link
Thanks for the review!Could you please add the aggregates, in the SPEC 2017 scores? There's usually a summary chart that has an average of the individual benchmarks, and then it often has the equivalent scores from more CPUs/configurations than the individual test graphs contain. For example, see the Alder Lake review:
https://www.anandtech.com/show/17047/the-intel-12t... Reply
Arbie - Thursday, October 20, 2022 - link
TechSpot / Hardware Unboxed show that to complete a Blender job the 13900K takes 50% more total system energy than does the 7950X. Intel completing a Cinebench job takes 70% more energy. Meaning heat in the room. And that's with the Intel chip thermal throttling instantly on even the best cooling.Looking at AT's "Power" charts here, which list the Intel chip as "125W" and AMD as "170W", many readers will get EXACTLY THE OPPOSITE impression.
Sure, you mention the difficulties in comparing TDPs etc, and compare this gen Intel to last gen etc but none of that "un-obscures" the totally erroneous Intel vs AMD picture you've conveyed.
ESPECIALLY when your conclusion says they're "very close in performance" !! BAD JOB, AT. The worst I've seen here in a very long time. Incomprehensibly bad. Reply
gezafisch - Thursday, October 20, 2022 - link
Cope harder - watch Der8auer's video showing that the 13900k can beat any chip at efficiency with the right settings - https://youtu.be/H4Bm0Wr6OEQ ReplyRyan Smith - Thursday, October 20, 2022 - link
We go into the subject of power consumption at multiple points and with multiple graphs, including outlining the 13900K's high peak power consumption in the conclusion.https://images.anandtech.com/graphs/graph17601/130...
Otherwise, the only place you see 125W and 170W are in the specification tables. And those values are the official specifications for those chips. Reply
boeush - Thursday, October 20, 2022 - link
Not true. You have those insanely misleading "TDP" labels on every CPU in the legend of every performance comparison chart. This paints a very misleading picture of "competitive" performance, whereas performance at iso-power (e.g. normalized per watt, based on total system power consumption measured at the outlet) would be much more enlightening. Replyboeush - Thursday, October 20, 2022 - link
*per watt-hour (not per watt)[summed over the duration of the benchmark run] Reply
dgingeri - Thursday, October 20, 2022 - link
Is it just me, or does the L1 cache arrangement seem a bit odd? 48k data and 32k instruction for the P cores and 32k data and 64k instruction on the e-cores. Seems a bit odd to me. ReplyOtritus - Thursday, October 20, 2022 - link
Golden/Raptor Cove has a micro-op cache for instructions. 4096 micro-ops is about equal to 16Kb of instruction cache, which is effectively 48Kb-D + 48Kb-I. I don’t remember whether Gracemont has a micro-op cache. However, it doesn’t have hyperthreading, so maybe it just needs less data cache per core. Reply