The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity
by Dr. Ian Cutress & Andrei Frumusanu on November 4, 2021 9:00 AM ESTCPU Tests: SPEC MT Performance - P and E-Core Scaling
Update Nov 6th:
We’ve finished our MT breakdown for the platform, investigating the various combination of cores and memory configurations for Alder Lake and the i9-12900K. We're posting the detailed scores for the DDR5 results, following up the aggregate results for DDR4 as well.
The results here solely cover the i9-12900K and various combinations of MT performance, such as 8 E-cores, 8 P-cores with 1T as well as 2T, and the full 24T 8P2T+8E scenario. The results here were done on Linux due to easier way to set affinities to the various cores, and they’re not completely comparable to the WSL results on the previous page, however should be within small margins of error for most tests.
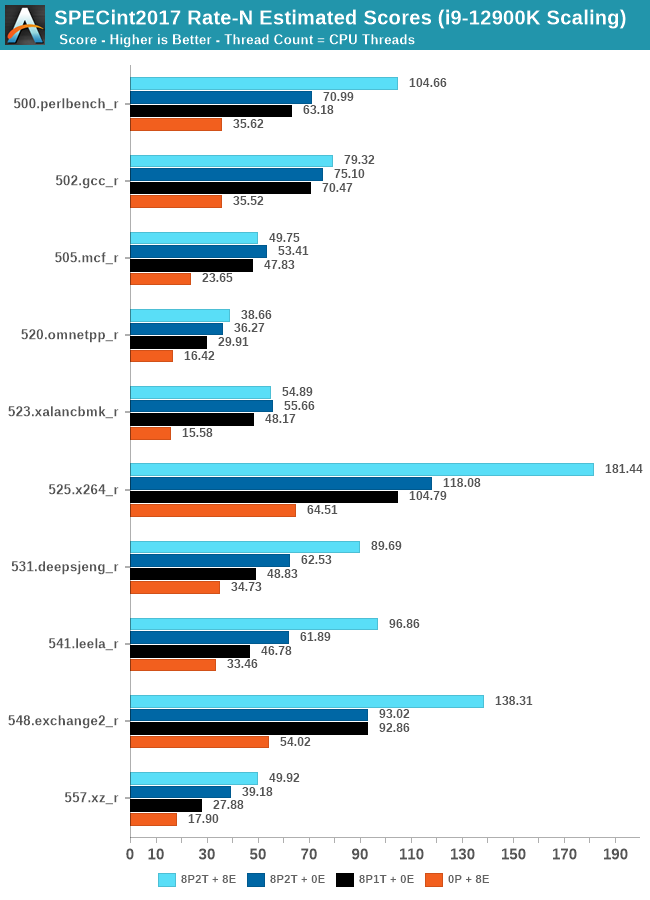
In the integer suite, the E-cores are quite powerful, reaching scores of around 50% of the 8P2T results, or more.
Many of the more core-bound workloads appear to very much enjoy just having more cores added to the suite, and these are also the workloads that have the largest gains in terms of gaining performance when we add 8 E-cores on top of the 8P2T results.
Workloads that are more cache-heavy, or rely on memory bandwidth, both shared resources on the chip, don’t scale too well at the top-end of things when adding the 8 E-cores. Most surprising to me was the 502.gcc_r result which barely saw any improvement with the added 8 E-cores.
More memory-bound workloads such as 520.omnetpp or 505.mcf are not surprising to see them not scale with the added E-cores – mcf even seeing a performance regression as the added cores mean more memory contention on the L3 and memory controllers.
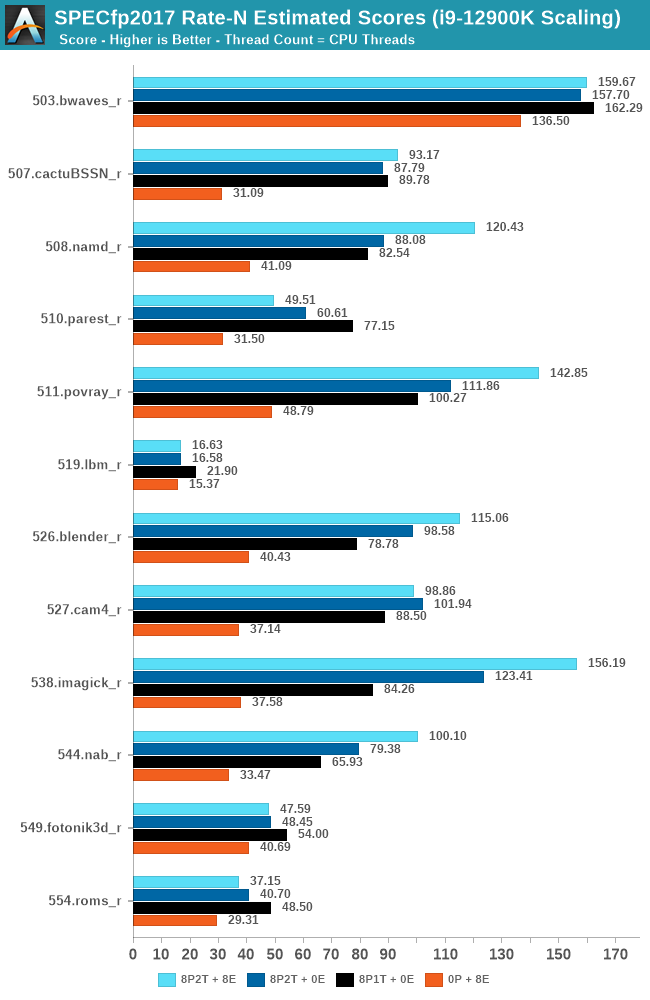
In the FP suite, the E-cores more clearly showcase a lower % of performance relative to the P-cores, and this makes sense given their design. Only few more compute-bound tests, such as 508.namd, 511.povray, or 538.imagick see larger contributions of the E-cores when they’re added in on top of the P-cores.
The FP suite also has a lot more memory-hungry workload. When it comes to DRAM bandwidth, having either E-cores or P-cores doesn’t matter much for the workload, as it’s the memory which is bottlenecked. Here, the E-cores are able to achieve extremely large performance figures compared to the P-cores. 503.bwaves and 519.lbm for example are pure DRAM bandwidth limited, and using the E-cores in MT scenarios allows for similar performance to the P-cores, however at only 35-40W package power, versus 110-125W for the P-cores result set.
Some of these workloads also see regressions in performance when adding in more cores or threads, as it just means more memory traffic contention on the chip, such as seen in the 8P2T+8E, 8P2T regressions over the 8P1T results.
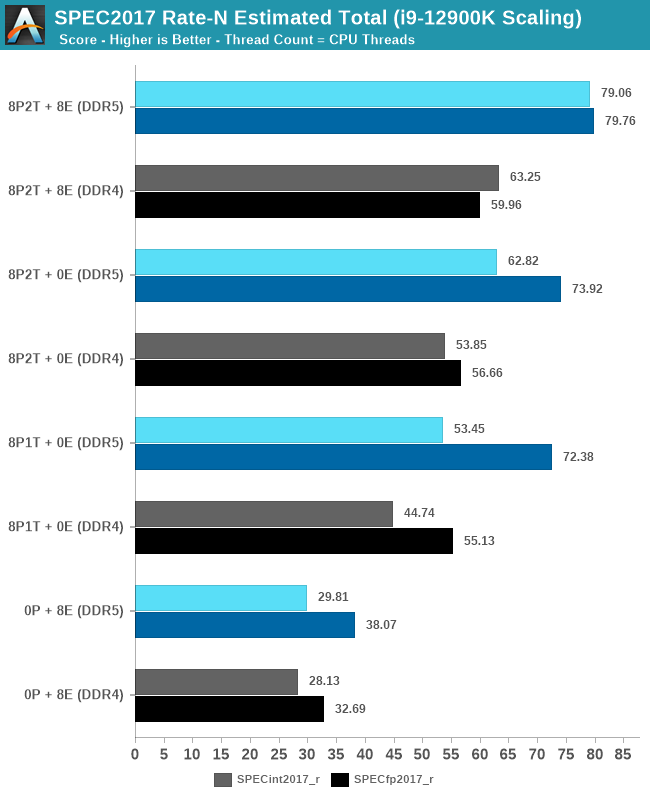
What’s most interesting here is the scaling of performance and the attribution between the P-cores and the E-cores. Focusing on the DDR5 set, the 8 E-cores are able to provide around 52-55% of the performance of 8 P-cores without SMT, and 47-51% of the P-cores with SMT. At first glance this could be argued that the 8P+8E setup can be somewhat similar to a 12P setup in MT performance, however the combined performance of both clusters only raises the MT scores by respectively 25% in the integer suite, and 5% in the FP suite, as we are hitting near package power limits with just 8P2T, and there’s diminishing returns on performance given the shared L3. What the E-cores do seem to allow the system is to allows to reduce every-day average power usage and increase the efficiency of the socket, as less P-cores need to be active at any one time.








474 Comments
View All Comments
Netmsm - Sunday, November 7, 2021 - link
I believe, we're not talking about ISO-efficiency or manufacturing or engineering details as facts! These are facts but in the appropriate discussion. Here, we have results. These results are produced by all those technological efforts. In fact, those theoretical improvements are getting concluded in these pragmatical information. Therefore, we should NOT wink at performance per watt in RESULTS - not ISO-related matters.So, the fact, my friend, is Intel new architecture does tend to suck 70-80 percent more power and give 50-60 percent more heat. Just by overclocking 100MHz 12900k jumps from ~80-85 to 100 degrees centigrade while consuming ~300 watts.
Once in past, AMD tried to get ahead of Nvidia by 6990 in performance because they coveted the most powerful graphic card title. AMD made the hottest and the noisiest graphic card in the history and now Intel is mimicking :))
One can argue that it is natural when you cannot stop or catch a rival so try to do some chicaneries. As it is very clear that Anandtech deliberately does not tend to put even the nominal TDP of Intel 12900k in their benches. I loathe this iniquitous practice!
Wrs - Sunday, November 7, 2021 - link
@Netmsm I believe the mistake is construing performance-per-watt (PPW) of a consumer chip as indicative of PPW for a future server chip based on the same core. Consumer chips are typically optimized for performance-per-area (PPA) because consumers want snappiness and they are afraid of high purchase costs while simultaneously caring much less than datacenters about cost of electricity.Netmsm - Monday, November 8, 2021 - link
@Wrs You cannot totally separate efficiency of consumer and enterprise chips!As an incontrovertible fact, architecture is what primarily (not completely) determines the efficacy of a processor.
Is Intel going to kit out upcoming server CPUs in an improved architecture?
Wrs - Monday, November 8, 2021 - link
@Netmsm Architecture, process, and configuration all can heavily impact efficiency/PPW. I’m not aware of any architectural reason that Golden Cove would be much less efficient. It’s a mildly larger core, but it doesn’t have outrageous pipelining or execution imbalances. It derives from a lineage of reasonably efficient cores, and they had to be as they remained on aging 14nm. Processwise Intel 7 isn’t much less efficient than TSMC N7, either. (It could even be more efficient, but analysis hasn’t been precise enough to tell.) But clearly ADL in a 12900/12700k is set up to be inefficient yet performant at high load by virtue of high frequency/voltage scaling and thermal density. I could do almost the same on a dual CCD Ryzen, before running into AM4 socket limits. That’s obviously not how either company approaches server chips.Netmsm - Tuesday, November 9, 2021 - link
When you cannot infer or appraise or guess we should drop it for now and wait for real tests of upcoming server chips to come.regards ^_^
GamingRiggz - Tuesday, March 15, 2022 - link
Thankfully you are no engineer.AbRASiON - Thursday, November 4, 2021 - link
AMD would have less of an issue If the 5000 processors weren’t originally priced gouged.Many people held off switching teams due to that. Instead of the processor being an amazing must buy, it was just a decent purchase. So they waited.
If you’re On the back foot in this game, you should be competing hard always to get that stranglehold and mind share.
I’m glad they’re competing though and hopefully they release some very competitive and REASONABLY PRICED products in the near future.
Fataliity - Thursday, November 4, 2021 - link
Their revenue and marketshare #'s beg to disagree.Spunjji - Friday, November 5, 2021 - link
They've been selling every CPU they can make. There are shortages of every Zen 3 based notebook out there (to the extent that some OEMs have cancelled certain models) and they're selling so many products based on the desktop chiplets that Threadripper 5000 simply isn't a thing. You ought to factor that into your assessment of how they're doing.BillBear - Thursday, November 4, 2021 - link
Is anyone gullible enough to forget more than a decade of price gouging, low core counts and nearly nonexistent performance increases we got from Intel, vs. the high core counts, increasing performance, and lower prices we got from AMD?