The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity
by Dr. Ian Cutress & Andrei Frumusanu on November 4, 2021 9:00 AM ESTCPU Tests: SPEC ST Performance on P-Cores & E-Cores
SPEC2017 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 10.0.0
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions. We decided to build our SPEC binaries on AVX2, which puts a limit on Haswell as how old we can go before the testing will fall over. This also means we don’t have AVX512 binaries, primarily because in order to get the best performance, the AVX-512 intrinsic should be packed by a proper expert, as with our AVX-512 benchmark. All of the major vendors, AMD, Intel, and Arm, all support the way in which we are testing SPEC.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labeled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
For Alder Lake, we start off with a comparison of the Golden Cove cores, both in DDR5 as well as DDR4 variants. We’re pitting them as direct comparison against Rocket Lake’s Cypress Cove cores, as well as AMD’s Zen3.
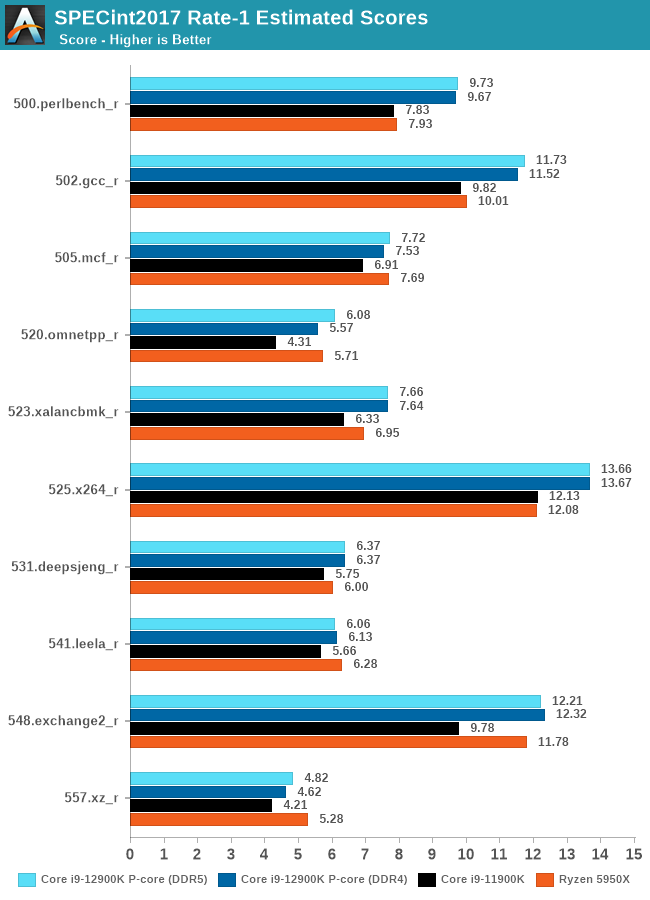
Starting off in SPECint2017, the first thing I’d say is that for single-thread workloads, it seems that DDR5 doesn’t showcase any major improvements over DDR4. The biggest increase for the Golden Cove cores are in 520.omnetpp_r at 9.2% - the workload is defined by sparse memory accessing in a parallel way, so DDR5’s doubled up channel count here is likely what’s affecting the test the most.
Comparing the DDR5 results against RKL’s WLC cores, ADL’s GLC showcases some large advantages in several workloads: 24% in perlbench, +29% in omnetpp, +21% in xalancbmk, and +26% in exchange2 – all of the workloads here are likely boosted by the new core’s larger out of order window which has grown to up to 512 instructions. Perlbench is more heavily instruction pressure biased, at least compared to other workloads in the suite, so the new 6-wide decoder also likely is a big reason we see such a large increase.
The smallest increases are in mcf, which is more pure memory latency bound, and deepsjeng and leela, the latter which is particularly branch mispredict heavy. Whilst Golden Cove improves its branch predictors, the core also had to add an additional cycle of misprediction penalty, so the relative smaller increases here make sense with that as a context.
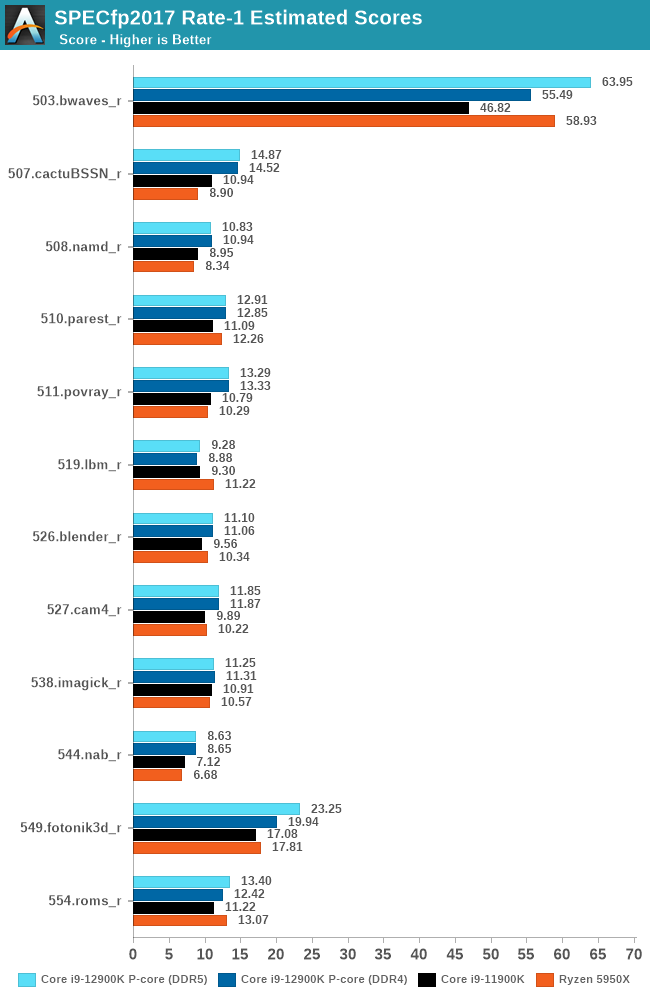
In the FP suite, the DDR5 results have a few larger outliers compared to the DDR4 set, bwaves and fotonik3d showcase +15% and +17% just due to the memory change, which is no surprise given both workloads extremely heavy memory bandwidth characteristic.
Compared to RKL, ADL showcases also some very large gains in some of the workloads, +33% in cactuBBSN, +24% in povray. The latter is a surprise to me as it should be a more execution-bound workload, so maybe the new added FADD units of the cores are coming into play here.
We’ve had not too much time to test out the Gracemont cores in isolation, but we are able to showcase some results. This set here is done on native Linux rather than WSL due to affinity issues on Windows, the results are within margin of error between the platforms, however there are a few % points outliers on the FP suite. Still, comparing the P to E-cores are in apples-to-apples conditions in these set of graphs:
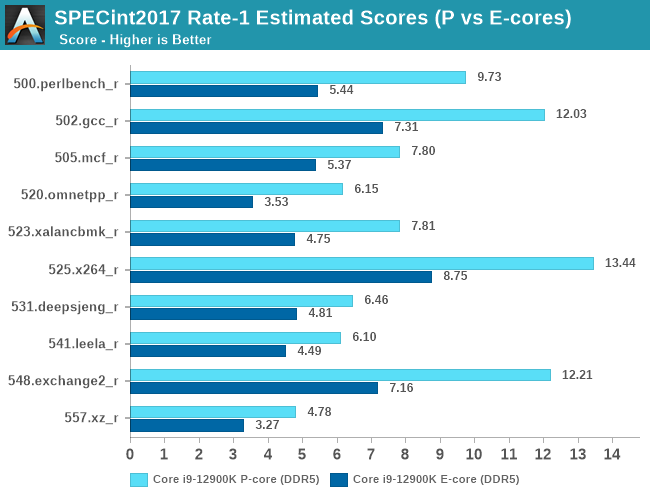
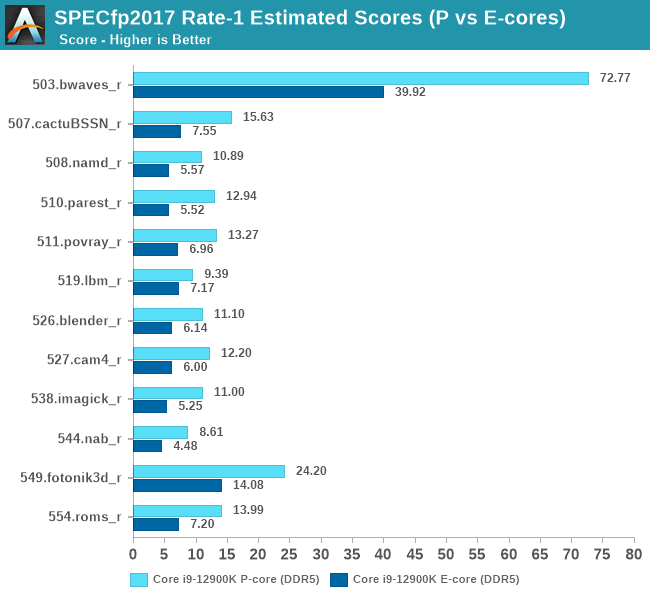
When Intel mentioned that the Gracemont E-cores of Alder Lake were matching the ST performance of the original Skylake, Intel was very much correct in that description. Unlike what we consider “little” cores in a normal big.LITTLE setup, the E-cores of Alder Lake are still quite performant.
In the aggregate scores, an E-core is roughly 54-64% of a P-core, however this percentage can go as high as 65-73%. Given the die size differences between the two microarchitectures, and the fact that in multi-threaded scenarios the P-cores would normally have to clock down anyway because of power limits, it’s pretty evident how Intel’s setup with efficiency and density cores allows for much higher performance within a given die size and power envelope.
In SPEC, in terms of package power, the P-cores averaged 25.3W in the integer suite and 29.2W in the FP suite, in contrast to respectively 10.7W and 11.5W for the E-cores, both under single-threaded scenarios. Idle package power ran in at 1.9W.
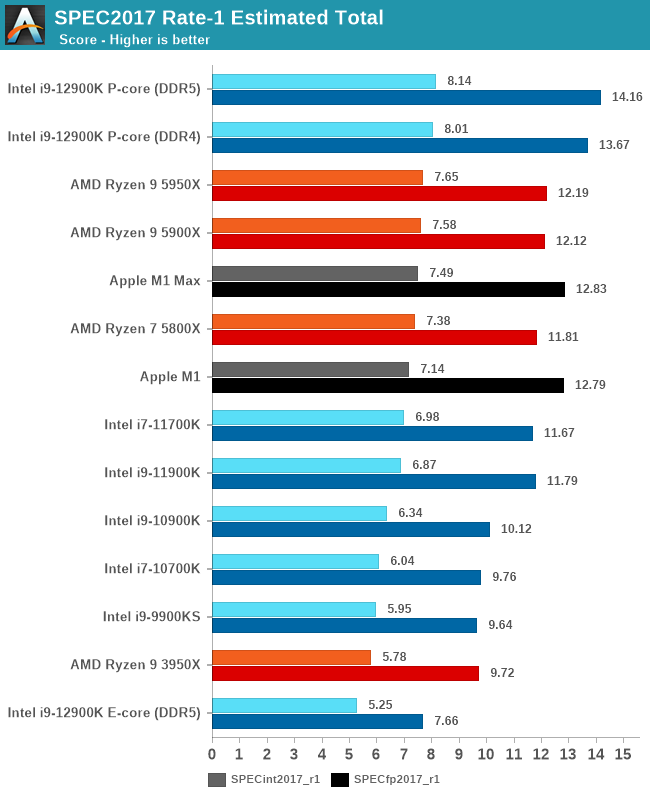
Alder Lake and the Golden Cove cores are able to reclaim the single-threaded performance crown from AMD and Apple. The increases over Rocket Lake come in at +18-20%, and Intel’s advantage over AMD is now at 6.4% and 16.1% depending on the suite, maybe closer than what Intel would have liked given V-cache variants of Zen3 are just a few months away.
Again, the E-core performance of ADL is impressive, while not extraordinary ahead in the FP suite, they can match the performance of some middle-stack Zen2 CPUs from only a couple of years ago in the integer suite.








474 Comments
View All Comments
Netmsm - Sunday, November 7, 2021 - link
I believe, we're not talking about ISO-efficiency or manufacturing or engineering details as facts! These are facts but in the appropriate discussion. Here, we have results. These results are produced by all those technological efforts. In fact, those theoretical improvements are getting concluded in these pragmatical information. Therefore, we should NOT wink at performance per watt in RESULTS - not ISO-related matters.So, the fact, my friend, is Intel new architecture does tend to suck 70-80 percent more power and give 50-60 percent more heat. Just by overclocking 100MHz 12900k jumps from ~80-85 to 100 degrees centigrade while consuming ~300 watts.
Once in past, AMD tried to get ahead of Nvidia by 6990 in performance because they coveted the most powerful graphic card title. AMD made the hottest and the noisiest graphic card in the history and now Intel is mimicking :))
One can argue that it is natural when you cannot stop or catch a rival so try to do some chicaneries. As it is very clear that Anandtech deliberately does not tend to put even the nominal TDP of Intel 12900k in their benches. I loathe this iniquitous practice!
Wrs - Sunday, November 7, 2021 - link
@Netmsm I believe the mistake is construing performance-per-watt (PPW) of a consumer chip as indicative of PPW for a future server chip based on the same core. Consumer chips are typically optimized for performance-per-area (PPA) because consumers want snappiness and they are afraid of high purchase costs while simultaneously caring much less than datacenters about cost of electricity.Netmsm - Monday, November 8, 2021 - link
@Wrs You cannot totally separate efficiency of consumer and enterprise chips!As an incontrovertible fact, architecture is what primarily (not completely) determines the efficacy of a processor.
Is Intel going to kit out upcoming server CPUs in an improved architecture?
Wrs - Monday, November 8, 2021 - link
@Netmsm Architecture, process, and configuration all can heavily impact efficiency/PPW. I’m not aware of any architectural reason that Golden Cove would be much less efficient. It’s a mildly larger core, but it doesn’t have outrageous pipelining or execution imbalances. It derives from a lineage of reasonably efficient cores, and they had to be as they remained on aging 14nm. Processwise Intel 7 isn’t much less efficient than TSMC N7, either. (It could even be more efficient, but analysis hasn’t been precise enough to tell.) But clearly ADL in a 12900/12700k is set up to be inefficient yet performant at high load by virtue of high frequency/voltage scaling and thermal density. I could do almost the same on a dual CCD Ryzen, before running into AM4 socket limits. That’s obviously not how either company approaches server chips.Netmsm - Tuesday, November 9, 2021 - link
When you cannot infer or appraise or guess we should drop it for now and wait for real tests of upcoming server chips to come.regards ^_^
GamingRiggz - Tuesday, March 15, 2022 - link
Thankfully you are no engineer.AbRASiON - Thursday, November 4, 2021 - link
AMD would have less of an issue If the 5000 processors weren’t originally priced gouged.Many people held off switching teams due to that. Instead of the processor being an amazing must buy, it was just a decent purchase. So they waited.
If you’re On the back foot in this game, you should be competing hard always to get that stranglehold and mind share.
I’m glad they’re competing though and hopefully they release some very competitive and REASONABLY PRICED products in the near future.
Fataliity - Thursday, November 4, 2021 - link
Their revenue and marketshare #'s beg to disagree.Spunjji - Friday, November 5, 2021 - link
They've been selling every CPU they can make. There are shortages of every Zen 3 based notebook out there (to the extent that some OEMs have cancelled certain models) and they're selling so many products based on the desktop chiplets that Threadripper 5000 simply isn't a thing. You ought to factor that into your assessment of how they're doing.BillBear - Thursday, November 4, 2021 - link
Is anyone gullible enough to forget more than a decade of price gouging, low core counts and nearly nonexistent performance increases we got from Intel, vs. the high core counts, increasing performance, and lower prices we got from AMD?