The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity
by Dr. Ian Cutress & Andrei Frumusanu on November 4, 2021 9:00 AM ESTCPU Tests: SPEC MT Performance - P and E-Core Scaling
Update Nov 6th:
We’ve finished our MT breakdown for the platform, investigating the various combination of cores and memory configurations for Alder Lake and the i9-12900K. We're posting the detailed scores for the DDR5 results, following up the aggregate results for DDR4 as well.
The results here solely cover the i9-12900K and various combinations of MT performance, such as 8 E-cores, 8 P-cores with 1T as well as 2T, and the full 24T 8P2T+8E scenario. The results here were done on Linux due to easier way to set affinities to the various cores, and they’re not completely comparable to the WSL results on the previous page, however should be within small margins of error for most tests.
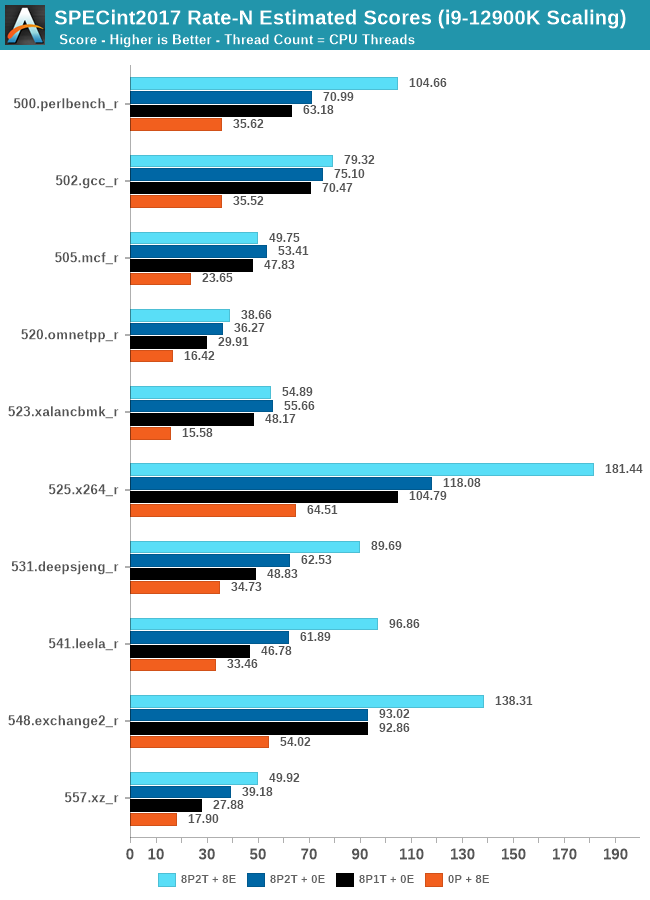
In the integer suite, the E-cores are quite powerful, reaching scores of around 50% of the 8P2T results, or more.
Many of the more core-bound workloads appear to very much enjoy just having more cores added to the suite, and these are also the workloads that have the largest gains in terms of gaining performance when we add 8 E-cores on top of the 8P2T results.
Workloads that are more cache-heavy, or rely on memory bandwidth, both shared resources on the chip, don’t scale too well at the top-end of things when adding the 8 E-cores. Most surprising to me was the 502.gcc_r result which barely saw any improvement with the added 8 E-cores.
More memory-bound workloads such as 520.omnetpp or 505.mcf are not surprising to see them not scale with the added E-cores – mcf even seeing a performance regression as the added cores mean more memory contention on the L3 and memory controllers.
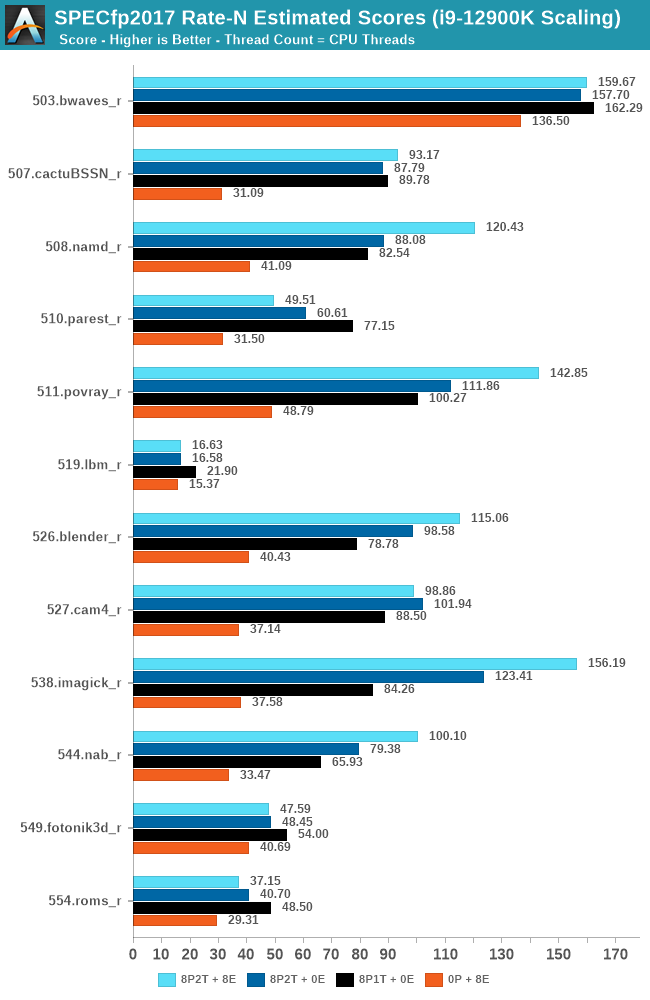
In the FP suite, the E-cores more clearly showcase a lower % of performance relative to the P-cores, and this makes sense given their design. Only few more compute-bound tests, such as 508.namd, 511.povray, or 538.imagick see larger contributions of the E-cores when they’re added in on top of the P-cores.
The FP suite also has a lot more memory-hungry workload. When it comes to DRAM bandwidth, having either E-cores or P-cores doesn’t matter much for the workload, as it’s the memory which is bottlenecked. Here, the E-cores are able to achieve extremely large performance figures compared to the P-cores. 503.bwaves and 519.lbm for example are pure DRAM bandwidth limited, and using the E-cores in MT scenarios allows for similar performance to the P-cores, however at only 35-40W package power, versus 110-125W for the P-cores result set.
Some of these workloads also see regressions in performance when adding in more cores or threads, as it just means more memory traffic contention on the chip, such as seen in the 8P2T+8E, 8P2T regressions over the 8P1T results.
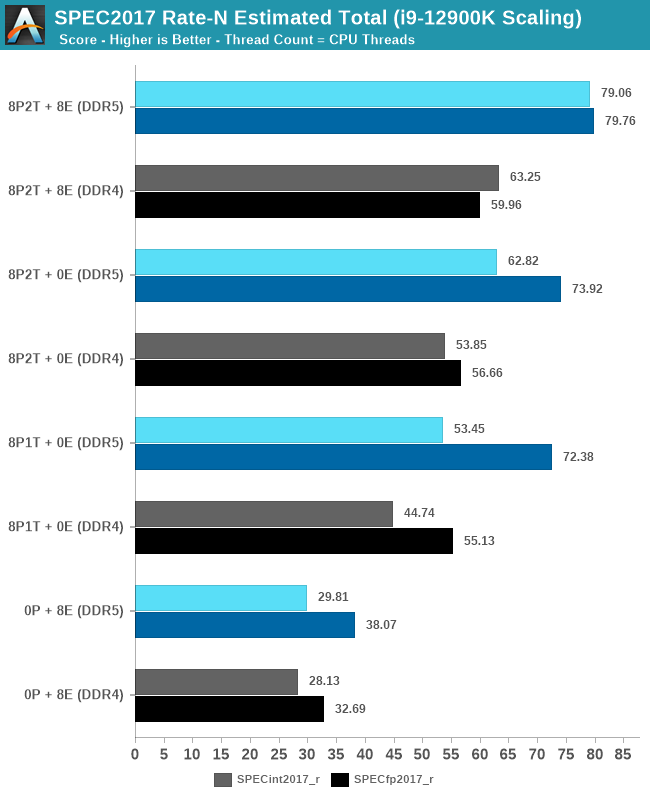
What’s most interesting here is the scaling of performance and the attribution between the P-cores and the E-cores. Focusing on the DDR5 set, the 8 E-cores are able to provide around 52-55% of the performance of 8 P-cores without SMT, and 47-51% of the P-cores with SMT. At first glance this could be argued that the 8P+8E setup can be somewhat similar to a 12P setup in MT performance, however the combined performance of both clusters only raises the MT scores by respectively 25% in the integer suite, and 5% in the FP suite, as we are hitting near package power limits with just 8P2T, and there’s diminishing returns on performance given the shared L3. What the E-cores do seem to allow the system is to allows to reduce every-day average power usage and increase the efficiency of the socket, as less P-cores need to be active at any one time.








474 Comments
View All Comments
Wrs - Saturday, November 6, 2021 - link
@Netmsm I'll leave that to the market as I don't foresee using any of the 3 that soon lol. It would stand to reason that if one product is both cheaper and better, it would keep gaining share at the expense of the other. If that doesn't happen I would question the premise of cheaper + better. And seeing as it's a major market for Intel, I have little doubt they'll adjust prices if they do find themselves selling an inferior product.Netmsm - Sunday, November 7, 2021 - link
That's right. We always check performance per watt and per dollar. A product should be reasonable with respect to its price and power consumption, this is a must.12900k can consume up to 241 which is very closer to Threadripper not Ryzen 5900's TDP and yet competing with chips having 125 TDP! What a parody this is!
I can't disregard and throw away efficiency factor, that's all.
Spunjji - Friday, November 5, 2021 - link
Seeing this has made me very interested to see the value proposition Alder Lake will be offering in gaming notebooks. I was vaguely planning to switch up to a Zen 3+ offering for my next system, but this might be enough to make me reconsider.EnglishMike - Thursday, November 4, 2021 - link
<blockquote>re: Enterprise: Considering power consumption, it's like a Pyrrhic victory for Intel.</blockquote>Why? This is not an enterprise solution -- that's the upcoming Sapphire Rapids Xeon processors, a completely different CPU platform.
Sure, if all you're doing is pegging desktop CPUs at 100% for video processing or a similar workload, then Alder Lake isn't for you, but the gaming benchmarks clearly show that when it comes to more typical desktop workloads, the i9 12900k is inline with the top of the line AMD processors in terms of power consumption.
Netmsm - Thursday, November 4, 2021 - link
and who in his right mind would believe that upcoming Xeon processors can bring revolutionary breakthrough in power consumption?!EnglishMike - Friday, November 5, 2021 - link
And that, my friend, is a great example of moving the goalposts.We'll have to see what Intel offers re: Xeon's but one thing is for sure, they're going to offer a completely different power profile to their flagship desktop CPUs, because that's the nature of the datacenter business.
Netmsm - Saturday, November 6, 2021 - link
Of course the nature of enterprise won't accept this power consumption. In PC world customers may not care how ineffective a processor is. Intel will reduce the power consumption but the matter is how its processor will accomplish the job! We see an unacceptable performance to watt in Intel's new architecture that needs something like a miracle for Xeon's to become competitive with Epyc's.Wrs - Saturday, November 6, 2021 - link
No miracle is needed... just go down the frequency-voltage curve. Existing Ice Lake Xeons already do that. What's new about Sapphire Rapids is not so much the process tech (it's still 10nm) but the much larger silicon area enabled per package due to the EMIB packaging. That's their plan to be competitive with Epyc and its multichip modules.Netmsm - Sunday, November 7, 2021 - link
And what will happen to performance as frequency-voltage curve goes down?Just look at facts! With about 100w more power consumption Intel's new architecture gets itself in front of Zen 3 by a slight margin in some cases that lucidly tells us it can never reduce power consumption and yet beat Epyc in performance.
Wrs - Sunday, November 7, 2021 - link
@Netmsm I'm looking at facts. The process nodes are very similar. One side has both a bigger/wider core (Golden Cove) and a really small core (Gracemont). The other side just has the intermediate size core (Zen 3). As a result, on some benchmarks one side wins by a fair bit, and on other benchmarks, the other side takes the cake. Many benches are a tossup.In this case the side that theoretically wins on efficiency at iso-throughput (MC performance) is the side that devotes more total silicon to the cores & cache. When comparing a 12900k to a 5950x, the latter has slightly more area across the CCDs, about 140 mm2 versus around 120 mm2. The side that's more efficient at iso-latency (ST/lightly threaded) is the one that devotes more silicon to their largest/preferred cores, which obviously here is ADL. In practice companies don't release their designs at iso-performance, and for throughput benchmarks one may encounter memory and other platform bottlenecks. But Intel seems to have aggressively clocked Golden Cove such that it's impossible for AMD to reach iso-latency with Zen 3 no matter the power input (i.e., you'd have to downclock the ADL). That has significant end-user implications as not everything can be split into more threads.
The Epyc Rome SKUs are already downclocked relative to Vermeer, like most server/workstation CPUs. Epyc Rome tops out at 64 Zen3 cores across 8 chiplets. Sapphire Rapids, which isn't out yet, has engineering samples topping out at 80 Golden Cove cores across 4 ~400mm2 chiplets. Given what we know about relative core sizes, which side is devoting more silicon to cores? There's your answer to performance at iso-efficiency. That's not to say it's fair to compare a product a year out vs. one you can obtain now, but also I don't see a Zen4 or N5 AMD server CPU within the next year.