The Intel 12th Gen Core i9-12900K Review: Hybrid Performance Brings Hybrid Complexity
by Dr. Ian Cutress & Andrei Frumusanu on November 4, 2021 9:00 AM ESTCPU Tests: SPEC MT Performance - P and E-Core Scaling
Update Nov 6th:
We’ve finished our MT breakdown for the platform, investigating the various combination of cores and memory configurations for Alder Lake and the i9-12900K. We're posting the detailed scores for the DDR5 results, following up the aggregate results for DDR4 as well.
The results here solely cover the i9-12900K and various combinations of MT performance, such as 8 E-cores, 8 P-cores with 1T as well as 2T, and the full 24T 8P2T+8E scenario. The results here were done on Linux due to easier way to set affinities to the various cores, and they’re not completely comparable to the WSL results on the previous page, however should be within small margins of error for most tests.
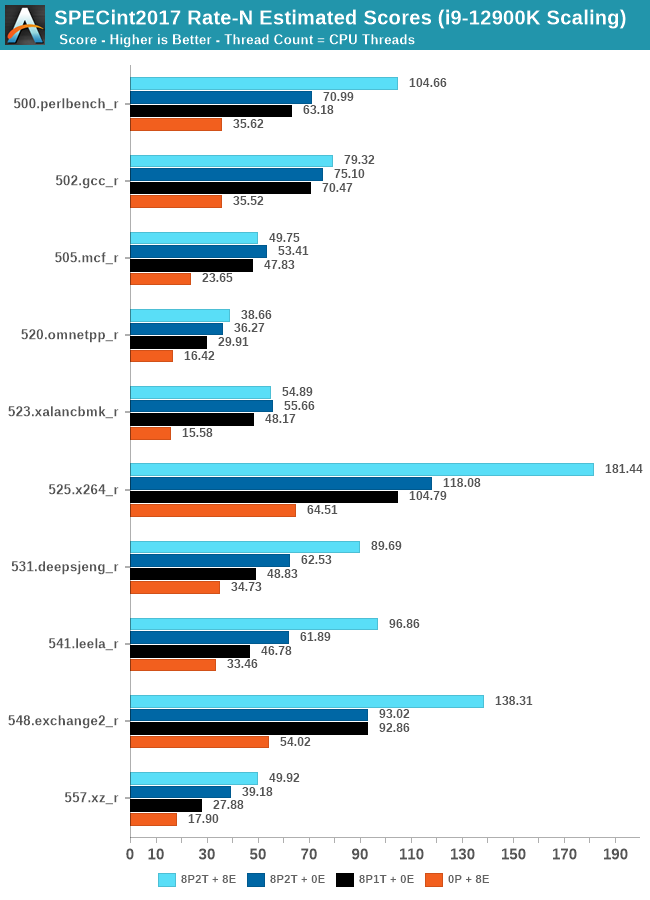
In the integer suite, the E-cores are quite powerful, reaching scores of around 50% of the 8P2T results, or more.
Many of the more core-bound workloads appear to very much enjoy just having more cores added to the suite, and these are also the workloads that have the largest gains in terms of gaining performance when we add 8 E-cores on top of the 8P2T results.
Workloads that are more cache-heavy, or rely on memory bandwidth, both shared resources on the chip, don’t scale too well at the top-end of things when adding the 8 E-cores. Most surprising to me was the 502.gcc_r result which barely saw any improvement with the added 8 E-cores.
More memory-bound workloads such as 520.omnetpp or 505.mcf are not surprising to see them not scale with the added E-cores – mcf even seeing a performance regression as the added cores mean more memory contention on the L3 and memory controllers.
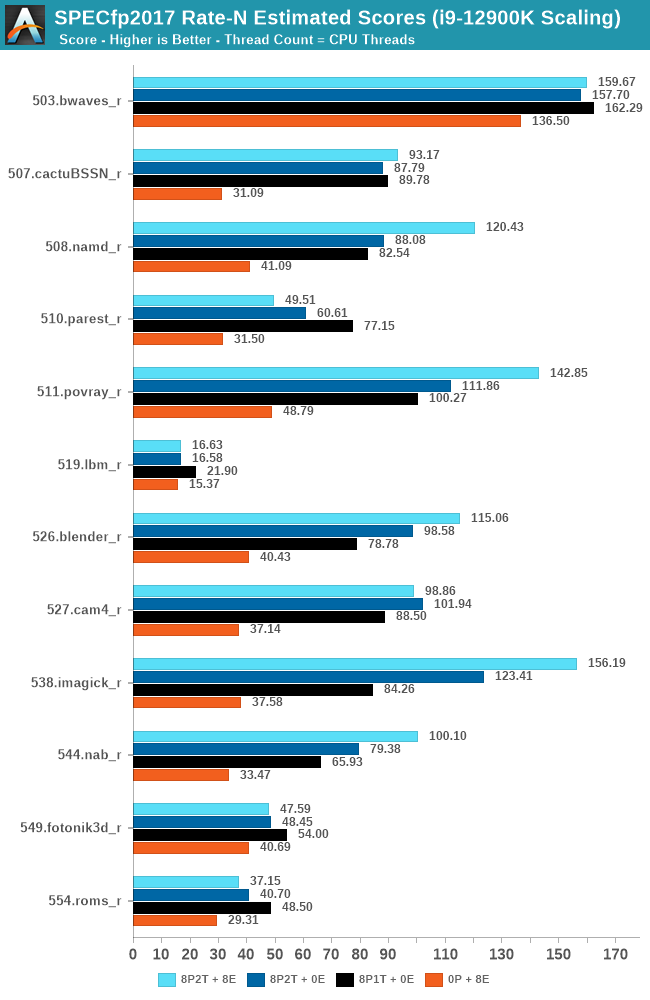
In the FP suite, the E-cores more clearly showcase a lower % of performance relative to the P-cores, and this makes sense given their design. Only few more compute-bound tests, such as 508.namd, 511.povray, or 538.imagick see larger contributions of the E-cores when they’re added in on top of the P-cores.
The FP suite also has a lot more memory-hungry workload. When it comes to DRAM bandwidth, having either E-cores or P-cores doesn’t matter much for the workload, as it’s the memory which is bottlenecked. Here, the E-cores are able to achieve extremely large performance figures compared to the P-cores. 503.bwaves and 519.lbm for example are pure DRAM bandwidth limited, and using the E-cores in MT scenarios allows for similar performance to the P-cores, however at only 35-40W package power, versus 110-125W for the P-cores result set.
Some of these workloads also see regressions in performance when adding in more cores or threads, as it just means more memory traffic contention on the chip, such as seen in the 8P2T+8E, 8P2T regressions over the 8P1T results.
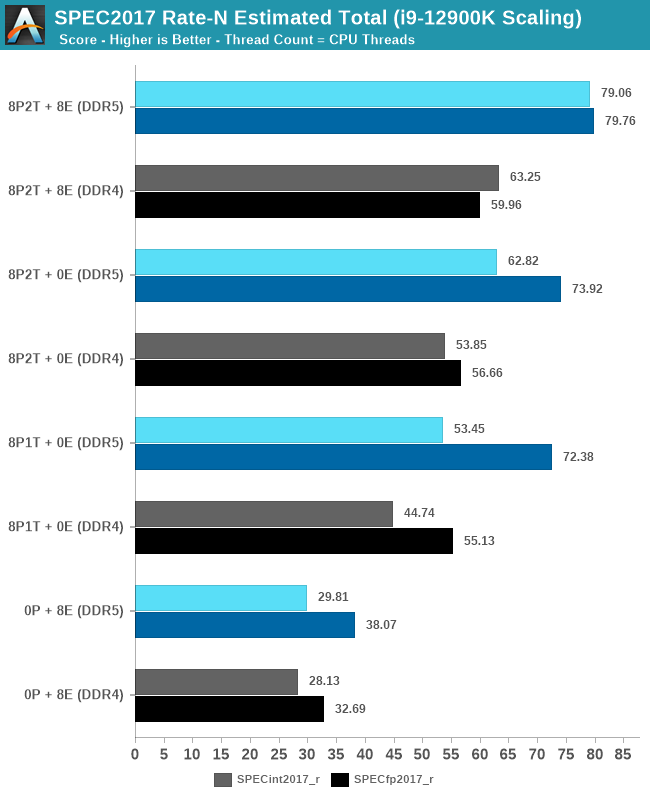
What’s most interesting here is the scaling of performance and the attribution between the P-cores and the E-cores. Focusing on the DDR5 set, the 8 E-cores are able to provide around 52-55% of the performance of 8 P-cores without SMT, and 47-51% of the P-cores with SMT. At first glance this could be argued that the 8P+8E setup can be somewhat similar to a 12P setup in MT performance, however the combined performance of both clusters only raises the MT scores by respectively 25% in the integer suite, and 5% in the FP suite, as we are hitting near package power limits with just 8P2T, and there’s diminishing returns on performance given the shared L3. What the E-cores do seem to allow the system is to allows to reduce every-day average power usage and increase the efficiency of the socket, as less P-cores need to be active at any one time.








474 Comments
View All Comments
mode_13h - Monday, November 15, 2021 - link
Do you know, for a fact, that the new scheduling policies override the priority-boost you mentioned? I wouldn't assume so, but I'm not saying they don't.Maybe I'm optimistic, but I think MS is smart enough to know there are realtime services that don't necessarily have focus and wouldn't break that usage model.
ZioTom - Monday, November 29, 2021 - link
Windows 11 scheduler fails to allocate workloads...I noticed that the scheduler parks the cores if the application isn't full screen.
I did a test on a 12700k with Handbrake: as long as the program window remains in the foreground, all the Pcore and Ecore are allocated at 100%. If I open a browser and use it while the movie is being compressed, the kernel takes the load off the Pcore and runs the video compression only on the Ecores. Absurd behavior, absolutely useless!
alpha754293 - Wednesday, January 12, 2022 - link
I have my 12900K for a little less than a month now and here's what I've found from the testing that I've done with the CPU:(Hardware notes/specs: Asus Z690 Prime-P D4 motherboard, 4x Crucial 32 GB DDR4-3200 unbuffered, non-ECC RAM (128 GB total), running CentOS 7.7.1908 with the 5.14.15 kernel)
IF your workload CAN be multithreaded and it can run on BOTH the P cores AND the E cores simultaneously, then there is a potential that you can have better performance than the 5950X. BUT if you CAN'T run your application on both the P cores and the E cores at the same time (which a number of distributed parallel applications that rely on MPI), then you WON'T be able to realise the performance advantages that having both said P cores and E cores would give you (based on what the benchmark results show).
And if your program, further, cannot use HyperThreading (which some HPC/CAE program will actually lock you out of doing so), then you can be upwards of anywhere between 63-81% SLOWER than the 5950X (because on the 5950X, even with SMT disabled, you can still run the programme on all 16 physical cores, vs. the 8 P cores on the 12900K).
Please take note.
alceryes - Wednesday, August 24, 2022 - link
Question.Did you use 'affinities' for all the different core tests (P-core only, P+E-core tests)?