No more mysteries: Apple's G5 versus x86, Mac OS X versus Linux
by Johan De Gelas on June 3, 2005 7:48 AM EST- Posted in
- Mac
Mac OS X: beautiful but...
The Mac OS X (Server) operating system can't be described easily. Apple:
While there are many very good ideas in Mac OS X, it reminds me a lot of fusion cooking, where you make a hotch-potch of very different ingredients. Let me explain.

Hexley the platypus, the Darwin mascot
Everything else is located in smaller programs, servers, which communicate with each other via ports and an IPC (Inter Process Communication) system. Explaining this in detail is beyond the scope of this article (read more here). But in a nutshell, a Mach microkernel should be more elegant, easier to debug and better at keeping different processes from writing in eachother's protected memory areas than our typical "monolithic" operating systems such as Linux and Windows NT/XP/2000. The Mach microkernel was believed to be the future of all operating systems.
However, you must know that applications (in the userspace) need, of course, access to the services of the kernel. In Unix, this is done with a Syscall, and it results in two context switches (the CPU has to swap out one process for another): from the application to the kernel and back.
The relatively complicated memory management (especially if the server process runs in user mode instead of kernel) and IPC messaging makes a call to the Mach kernel a lot slower, up to 6 times slower than the monolithic ones!
It also must be remarked that, for example, Linux is not completely a monolithic OS. You can choose whether you like to incorporate a driver in the kernel (faster, but more complex) or in userspace (slower, but the kernel remains slimmer).
Now, while Mac OS X is based on Mach 3, it is still a monolithic OS. The Mach microkernel is fused into a traditional FreeBSD "system call" interface. In fact, Darwin is a complete FreeBSD 4.4 alike UNIX and thus monolithic kernel, derived from the original 4.4BSD-Lite2 Open Source distribution.
The current Mac OS X has evolved a bit and consists of a FreeBSD 5.0 kernel (with a Mach 3 multithreaded microkernel inside) with a proprietary, but superb graphical user interface (GUI) called Aqua.
Performance problems
As the mach kernel is hidden away deep in the FreeBSD kernel, Mach (kernel) threads are only available for kernel level programs, not applications such as MySQL. Applications can make use of a POSIX thread (a " pthread"), a wrapper around a Mach thread.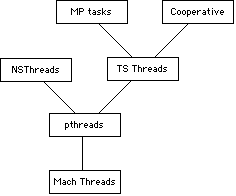
Mac OS X thread layering hierarchy (Courtesy: Apple)
In order to maintain binary compatibility, Apple might not have been able to implement some of the performance improvements found in the newer BSD kernels.
Another problem is the way threads could/can get access to the kernel. In the early versions of Mac OS X, only one thread could lock onto the kernel at once. This doesn't mean only one thread can run, but that only one thread could access the kernel at a given time. So, a rendering calculation (no kernel interaction) together with a network access (kernel access) could run well. But many threads demanding access to the memory or network subsystem would result in one thread getting access, and all others waiting.
This "kernel locked bottleneck" situation has improved in Tiger, but kernel locking is still very coarse. So, while there is a very fine grained multi-threading system (The Mach kernel) inside that monolithic kernel, it is not available to the outside world.
So, is Mac OS X the real reason why MySQL and Apache run so slow on the Mac Platform? Let us find out... with benchmarks, of course!








116 Comments
View All Comments
Icehawk - Friday, June 3, 2005 - link
Interesting stuff. I'd like to see more data too. Mmm Solaris.Unfortunately the diagrams weren't labeled for the most part (in terms of "higher is better") making it difficult to determine the results.
And the whole not displaying on FF properly... come on.
NetMavrik - Friday, June 3, 2005 - link
You can say that again! NT shares a whole lot more than just similarites to VMS. There are entire structures that are copied straight from VMS. I think most people have forgotten or never knew what "NT" stood for anyway. Take VMS, increment each letter by one, and you get WNT! New Technology my a$$.Guspaz - Friday, June 3, 2005 - link
Good article. But I'd like to see it re-done with the optimal compiler per-platform, and I'd like to see PowerPC Linux used to confirm that OSX is the cause of the slow MySQL performance.melgross - Friday, June 3, 2005 - link
I was just thinking back about this and remembered something I've seenComputerworld has had articles over the past two years or so about companies who have gone to XServes. They are using them with Apache, SYbase or Oracle. I don't remember any complaints about performance.
Also Oracle itself went to XServes for its own datacenter. Do you think they would have done that if performance was bad? They even stated that the performance was very good.
Something here seems screwed up.
brownba - Friday, June 3, 2005 - link
johan, i always appreciate your articles.you've been /.'d !!!!
and anandtech is holding up well.
good job
bostrov - Friday, June 3, 2005 - link
Since so much effort went in to vector facilities and instruction sets ever since the P54 days, shouldn't "best effort" on each CPU be used (use the IBM compiler on G5 and the Intel compiler on x86) - by using gcc you're using an almost artifically bad compiler and there is no guarantee that gcc will provide equivilant optimizations for each platform anyway.I think it'd be very interesting to see an article with the very best available compilers on each platform running the benchmarks.
Incidently, intel C with the vector instruction sets disabled still does better.
JohanAnandtech - Friday, June 3, 2005 - link
bostrov: because the Intel compiler is superb at vectorizing code. I am testing x87 FPU and gcc, you are testing SSE-2 performance with the Intel compiler.JohanAnandtech - Friday, June 3, 2005 - link
minsctdp: A typo which happened during final proofread. All my original tables say 990 MB/s. Fixed now.bostrov - Friday, June 3, 2005 - link
My own results for flops 2.0: (compiled with Intel C 8.1, 3.2 Ghz Prescott with 160 Mhz - 5:4 ratio - FSB)flops20-c_prescott.exe
FLOPS C Program (Double Precision), V2.0 18 Dec 1992
Module Error RunTime MFLOPS
(usec)
1 1.7764e-013 0.0109 1288.7451
2 -1.4166e-013 0.0082 852.7242
3 8.1046e-015 0.0067 2531.7045
4 9.0483e-014 0.0052 2858.2062
5 -6.2061e-014 0.0140 2065.6650
6 3.3640e-014 0.0100 2906.2439
7 -5.7980e-012 0.0327 366.4559
8 3.7692e-014 0.0111 2700.8968
Iterations = 512000000
NullTime (usec) = 0.0000
MFLOPS(1) = 1088.7826
MFLOPS(2) = 854.7579
MFLOPS(3) = 1609.7508
MFLOPS(4) = 2753.5016
Why are the anandtech results so poor?
melgross - Friday, June 3, 2005 - link
I thought that GCC comes with Tiger. I have read Apple's own info, and it definitely mentions GCC 4. Perhaps that would help the vectorization process.Altivec is such an important part of the processor and the performance of the machine that I would like to see properly written code used to compare these machines.