Apple's M1 Pro, M1 Max SoCs Investigated: New Performance and Efficiency Heights
by Andrei Frumusanu on October 25, 2021 9:00 AM EST- Posted in
- Laptops
- Apple
- MacBook
- Apple M1 Pro
- Apple M1 Max
Power Behaviour: No Real TDP, but Wide Range
Last year when we reviewed the M1 inside the Mac mini, we did some rough power measurements based on the wall-power of the machine. Since then, we learned how to read out Apple’s individual CPU, GPU, NPU and memory controller power figures, as well as total advertised package power. We repeat the exercise here for the 16” MacBook Pro, focusing on chip package power, as well as AC active wall power, meaning device load power, minus idle power.
Apple doesn’t advertise any TDP for the chips of the devices – it’s our understanding that simply doesn’t exist, and the only limitation to the power draw of the chips and laptops are simply thermals. As long as temperature is kept in check, the silicon will not throttle or not limit itself in terms of power draw. Of course, there’s still an actual average power draw figure when under different scenarios, which is what we come to test here:
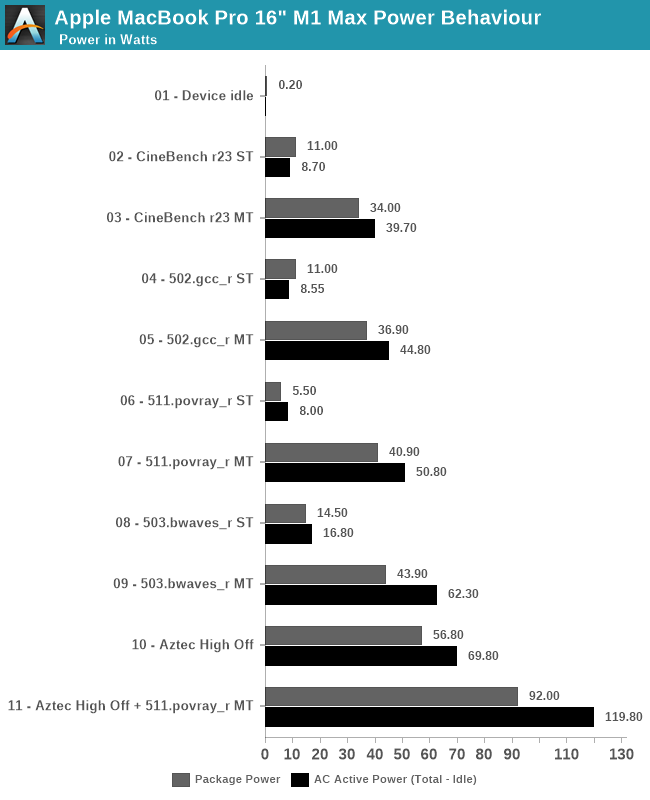
Starting off with device idle, the chip reports a package power of around 200mW when doing nothing but idling on a static screen. This is extremely low compared to competitor designs, and is likely a reason Apple is able achieve such fantastic battery life. The AC wall power under idle was 7.2W, this was on Apple’s included 140W charger, and while the laptop was on minimum display brightness – it’s likely the actual DC battery power under this scenario is much lower, but lacking the ability to measure this, it’s the second-best thing we have. One should probably assume a 90% efficiency figure in the AC-to-DC conversion chain from 230V wall to 28V USB-C MagSafe to whatever the internal PMIC usage voltage of the device is.
In single-threaded workloads, such as CineBench r23 and SPEC 502.gcc_r, both which are more mixed in terms of pure computation vs also memory demanding, we see the chip report 11W package power, however we’re just measuring a 8.5-8.7W difference at the wall when under use. It’s possible the software is over-reporting things here. The actual CPU cluster is only using around 4-5W under this scenario, and we don’t seem to see much of a difference to the M1 in that regard. The package and active power are higher than what we’ve seen on the M1, which could be explained by the much larger memory resources of the M1 Max. 511.povray is mostly core-bound with little memory traffic, package power is reported less, although at the wall again the difference is minor.
In multi-threaded scenarios, the package and wall power vary from 34-43W on package, and wall active power from 40 to 62W. 503.bwaves stands out as having a larger difference between wall power and reported package power – although Apple’s powermetrics showcases a “DRAM” power figure, I think this is just the memory controllers, and that the actual DRAM is not accounted for in the package power figure – the extra wattage that we’re measuring here, because it’s a massive DRAM workload, would be the memory of the M1 Max package.
On the GPU side, we lack notable workloads, but GFXBench Aztec High Offscreen ends up with a 56.8W package figure and 69.80W wall active figure. The GPU block itself is reported to be running at 43W.
Finally, stressing out both CPU and GPU at the same time, the SoC goes up to 92W package power and 120W wall active power. That’s quite high, and we haven’t tested how long the machine is able to sustain such loads (it’s highly environment dependent), but it very much appears that the chip and platform don’t have any practical power limit, and just uses whatever it needs as long as temperatures are in check.
| M1 Max MacBook Pro 16" |
Intel i9-11980HK MSI GE76 Raider |
|||||
| Score | Package Power (W) |
Wall Power Total - Idle (W) |
Score | Package Power (W) |
Wall Power Total - Idle (W) |
|
| Idle | 0.2 | 7.2 (Total) |
1.08 | 13.5 (Total) |
||
| CB23 ST | 1529 | 11.0 | 8.7 | 1604 | 30.0 | 43.5 |
| CB23 MT | 12375 | 34.0 | 39.7 | 12830 | 82.6 | 106.5 |
| 502 ST | 11.9 | 11.0 | 9.5 | 10.7 | 25.5 | 24.5 |
| 502 MT | 74.6 | 36.9 | 44.8 | 46.2 | 72.6 | 109.5 |
| 511 ST | 10.3 | 5.5 | 8.0 | 10.7 | 17.6 | 28.5 |
| 511 MT | 82.7 | 40.9 | 50.8 | 60.1 | 79.5 | 106.5 |
| 503 ST | 57.3 | 14.5 | 16.8 | 44.2 | 19.5 | 31.5 |
| 503 MT | 295.7 | 43.9 | 62.3 | 60.4 | 58.3 | 80.5 |
| Aztec High Off | 307fps | 56.8 | 69.8 | 266fps | 35 + 144 | 200.5 |
| Aztec+511MT | 92.0 | 119.8 | 78 + 142 | 256.5 | ||
Comparing the M1 Max against the competition, we resorted to Intel’s 11980HK on the MSI GE76 Raider. Unfortunately, we wanted to also do a comparison against AMD’s 5980HS, however our test machine is dead.
In single-threaded workloads, Apple’s showcases massive performance and power advantages against Intel’s best CPU. In CineBench, it’s one of the rare workloads where Apple’s cores lose out in performance for some reason, but this further widens the gap in terms of power usage, whereas the M1 Max only uses 8.7W, while a comparable figure on the 11980HK is 43.5W.
In other ST workloads, the M1 Max is more ahead in performance, or at least in a similar range. The performance/W difference here is around 2.5x to 3x in favour of Apple’s silicon.
In multi-threaded tests, the 11980HK is clearly allowed to go to much higher power levels than the M1 Max, reaching package power levels of 80W, for 105-110W active wall power, significantly more than what the MacBook Pro here is drawing. The performance levels of the M1 Max are significantly higher than the Intel chip here, due to the much better scalability of the cores. The perf/W differences here are 4-6x in favour of the M1 Max, all whilst posting significantly better performance, meaning the perf/W at ISO-perf would be even higher than this.
On the GPU side, the GE76 Raider comes with a GTX 3080 mobile. On Aztec High, this uses a total of 200W power for 266fps, while the M1 Max beats it at 307fps with just 70W wall active power. The package powers for the MSI system are reported at 35+144W.
Finally, the Intel and GeForce GPU go up to 256W power daw when used together, also more than double that of the MacBook Pro and its M1 Max SoC.
The 11980HK isn’t a very efficient chip, as we had noted it back in our May review, and AMD’s chips should fare quite a bit better in a comparison, however the Apple Silicon is likely still ahead by extremely comfortable margins.








493 Comments
View All Comments
OreoCookie - Friday, October 29, 2021 - link
You shouldn't mix the M1 Pro and M1 Max: the article was about the Max. The Pro makes some concessions and it looks like there are some workloads where you can saturate its memory bandwidth … but only barely so. Even then, the M1 Pro would have much, much more memory bandwidth than any laptop CPU available today (and any x86 on the horizon).And I think you should include the L2 cache here, which is larger than the SL cache on the Pro, and still significant in the Max (28 MB vs. 48 MB).
I still think you are nitpicking: memory bandwidth is a strength of the M1 Pro and Max, not a weakness. The extra cache in AMD's Zen 3D will not change the landscape in this respect either.
richardnpaul - Friday, October 29, 2021 - link
The article does describe the differences between the two on the front page and runs comparisons throughout the benchmarks, whilst it's titled to be about the Max I found that it really basically covered both chips, the focus was on what benefits if any the Max brings over the Pro, so I felt it natural to include what I now see is a confusing reference to 24MB because you don't know what's going on in my head 😁From what I could tell the SL cache was not described like a typical L3 cache but I guess you could think of it more like that, so I was thinking of it as almost like an L4 cache (thus my comment about its placement in the die, its next to the memory controllers, and the GPU blocks, and quite far away from the CPU cores themselves so there will be a larger penalty for access vs a typical L3 which would be very close to the CPU core blocks. I've gone back and looked again and it's not as far away as I first though as I'd mistook where the CPU cores were)
Total cache is 72MB (76MB including the efficiency cores' L2, and anything in the GPU), the AMD Desktop M3 chip has 36MB and will be 100MB with the Vcache so certainly in the same ballpark really, as in it's a lot currently (but I'm sure that we'll see the famed 1GB in the next decade). The M1 Max is crazy huge for a laptop which is why I compare it to the desktop Zen3 and also because nothing else is really comparable with 8 cores.
I don't think it's a weakness, it's pretty huge for a 10TF GPU and an 8 core CPU (plus whatever the NPU etc. pull through it). I'm just not a fan of the compromises involved, such as RAM that can't be upgraded; though a 512bit interface would necessitate quite a few PCB layers to achieve with modular RAM.
Oxford Guy - Friday, October 29, 2021 - link
Apple pioneered the disposable closed system with the original Mac.It was so extreme that Jobs used outright bait and switch fraud to sucker the tech press with speech synthesis. The only Mac to be sold at the time of the big unveiling had 128K and was not expandable. Jobs used a 512K prototype without informing the press so he could run speech synthesis — software that also did not come with the Mac (another deception).
Non-expandable RAM isn’t a bug to Apple’s management; it’s a very highly-craved feature.
techconc - Thursday, October 28, 2021 - link
You're exactly right. Here's what Affinity Photo has to say about it..."The #M1Max is the fastest GPU we have ever measured in the @affinitybyserif Photo benchmark. It outperforms the W6900X — a $6000, 300W desktop part — because it has immense compute performance, immense on-chip bandwidth and immediate transfer of data on and off the GPU (UMA)."
richardnpaul - Thursday, October 28, 2021 - link
They're right, which is why you see SMA these days on the newer AMD stuff (Resize BAR) and why Nvidia did the custom interface tech with IBM and are looking to do the same in servers with ARM to leverage these kinds of performance gains. It's also the reason why AMD bought ATI in the first place all those years ago; the whole failed heterogeneous compute (it must be galling for some at AMD that Apple have executed on this promise so well.)techconc - Thursday, October 28, 2021 - link
You clearly don't understand what drives performance. You have a very limited view which looks only at the TFLOPs metric and not at the entire system. Performance comes from the following 3 things: High compute performance (TFLOPS), fast on-chip bandwidth and fast transfer on and off the GPU.As an example, Andy Somerfield, lead for Affinity Photo app had the following to say regarding the M1 Max with their application:
"The #M1Max is the fastest GPU we have ever measured in the @affinitybyserif Photo benchmark. It outperforms the W6900X — a $6000, 300W desktop part — because it has immense compute performance, immense on-chip bandwidth and immediate transfer of data on and off the GPU (UMA)."
This is comparing the M1 Max GPU to a $6000, 300W part and the M1 Max handily outperforms it. In terms of TFLOPS, the 6900XT has more than 2x the power. Yet, the high speed and efficient design of the share memory on the M1 Max allows it to outperform this more expensive part in actual practice. It does so while using just a fraction of the power. That does make the M1 Max pretty special.
richardnpaul - Thursday, October 28, 2021 - link
Yes TFLOPs is a very simple metric and doesn't directly tell you much about performance, but it's a general guide (Nvidia got more out of their hardware compared to AMD for example and have until the 6800 series if you only looked at the TFLOPS figures.) Please, tell me more about what I think and understand /sIt's fastest for their scenario and for their implementation. It may be, and is very likely, that there's some specific bottleneck that they are hitting with the W6900X that isn't a problem with the implementation details of the M1 Pro/Max chips. Their issue seems to be interconnect bandwidth, they're constantly moving data back and forth between the CPU and GPU and with the M1 chips they don't need to do that, saving huge amounts of time because the PCI-E bus adds a lot of latency from what I understand so you really don't want to transfer back and forth over it (and maybe you don't need to, maybe you can do something differently in the software implementation, maybe you can't and it's just a problem that's much more efficiently done on this kind of architecture I don't know and wouldn't be able to comment knowing nothing about the software or problem that it solves. What I don't take at face value is one person/company saying use our software as it's amazing on only this hardware; I mean a la Oracle right?)
When it comes to gaming performance, it seems that the 6900XT or the RTX 3080 seem to put this chip in its place, based on the benchmarks we saw (infact, the mobile 3080 is basically just an RTX 3070 so even more so which could be because of all sorts of issues already highlighted) you could say that the GPU isn't good as a GPU but is great at one task as a highly parallel co-processor for one piece of software that if that's the software you want to use then great for you but if you want to use the GPU for actual GPU tasks it might underwhelm (though in a laptop format and for this little power draw of ~120W max it's not going to do that for a few years which is the point that you're making and I'm not disputing - Apple will obviously launch new replacements which will put this in the shade in time).
Hrunga_Zmuda - Tuesday, October 26, 2021 - link
From the developers of Affinity Photo:"The #M1Max is the fastest GPU we have ever measured in the @affinitybyserif Photo benchmark. It outperforms the W6900X — a $6000, 300W desktop part — because it has immense compute performance, immense on-chip bandwidth and immediate transfer of data on and off the GPU (UMA)."
Ahem, a laptop that tops out at not much more than the top GPU. That is bananas!
buta8 - Wednesday, October 27, 2021 - link
Please tell me how monitor the CPU Bandwidth - Intra-cacheline R&W?buta8 - Wednesday, October 27, 2021 - link
Please tell me how monitor the CPU Bandwidth - Intra-cacheline R&W?