Apple's M1 Pro, M1 Max SoCs Investigated: New Performance and Efficiency Heights
by Andrei Frumusanu on October 25, 2021 9:00 AM EST- Posted in
- Laptops
- Apple
- MacBook
- Apple M1 Pro
- Apple M1 Max
CPU MT Performance: A Real Monster
What’s more interesting than ST performance, is MT performance. With 8 performance cores and 2 efficiency cores, this is now the largest iteration of Apple Silicon we’ve seen.
As a prelude into the scores, I wanted to remark some things on the previous smaller M1 chip. The 4+4 setup on the M1 actually resulted that a significant chunk of the MT performance being enabled by the E-cores, with the SPECint score in particular seeing a +33% performance boost versus just the 4 P-cores of the system. Because the new M1 Pro and Max have 2 less E-cores, just assuming linear scaling, the theoretical peak of the M1 Pro/Max should be +62% over the M1. Of course, the new chips should behave better than linear, due to the better memory subsystem.
In the detailed scores I’m showcasing the full 8+2 scores of the new chips, and later we’ll talk about the 8 P scores in context. I hadn’t run the MT scores of the new Fortran compiler set on the M1 and some numbers will be missing from the charts because of that reason.
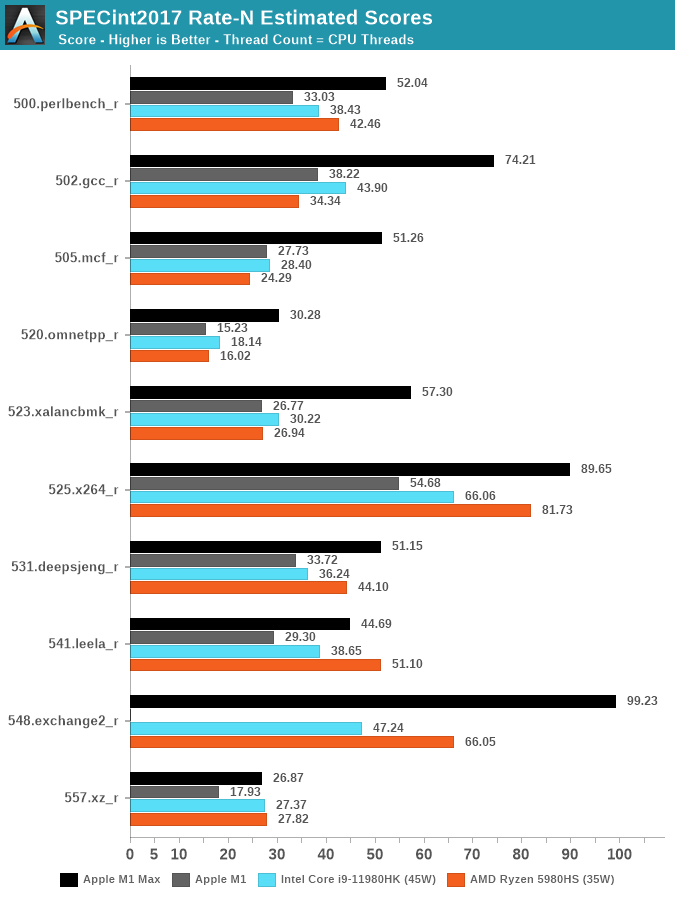
Looking at the data – there’s very evident changes to Apple’s performance positioning with the new 10-core CPU. Although, yes, Apple does have 2 additional cores versus the 8-core 11980HK or the 5980HS, the performance advantages of Apple’s silicon is far ahead of either competitor in most workloads. Again, to reiterate, we’re comparing the M1 Max against Intel’s best of the best, and also nearly AMD’s best (The 5980HX has a 45W TDP).
The one workload standing out to me the most was 502.gcc_r, where the M1 Max nearly doubles the M1 score, and lands in +69% ahead of the 11980HK. We’re seeing similar mind-boggling performance deltas in other workloads, memory bound tests such as mcf and omnetpp are evidently in Apple’s forte. A few of the workloads, mostly more core-bound or L2 resident, have less advantages, or sometimes even fall behind AMD’s CPUs.
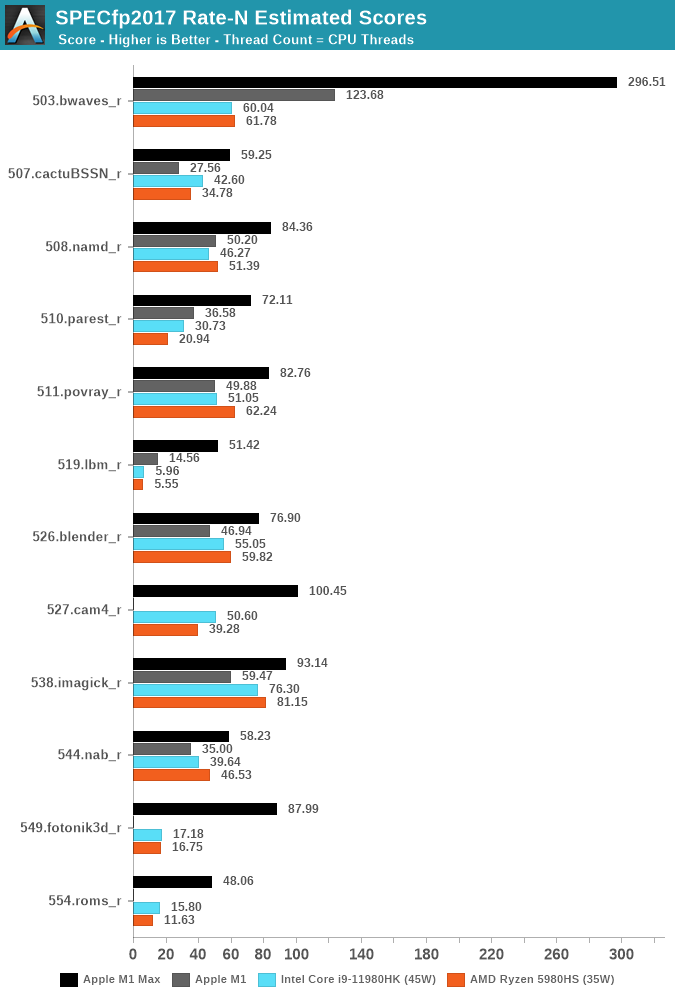
The fp2017 suite has more workloads that are more memory-bound, and it’s here where the M1 Max is absolutely absurd. The workloads that put the most memory pressure and stress the DRAM the most, such as 503.bwaves, 519.lbm, 549.fotonik3d and 554.roms, have all multiple factors of performance advantages compared to the best Intel and AMD have to offer.
The performance differences here are just insane, and really showcase just how far ahead Apple’s memory subsystem is in its ability to allow the CPUs to scale to such degree in memory-bound workloads.
Even workloads which are more execution bound, such as 511.porvray or 538.imagick, are – albeit not as dramatically, still very much clearly in favour of the M1 Max, achieving significantly better performance at drastically lower power.
We noted how the M1 Max CPUs are not able to fully take advantage of the DRAM bandwidth of the chip, and as of writing we didn’t measure the M1 Pro, but imagine that design not to score much lower than the M1 Max here. We can’t help but ask ourselves how much better the CPUs would score if the cluster and fabric would allow them to fully utilise the memory.
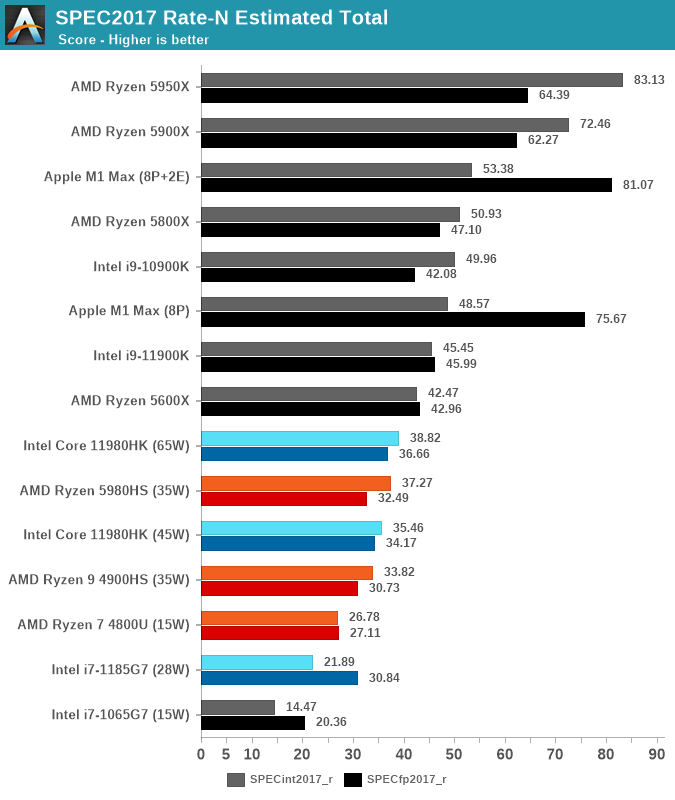
In the aggregate scores – there’s two sides. On the SPECint work suite, the M1 Max lies +37% ahead of the best competition, it’s a very clear win here and given the power levels and TDPs, the performance per watt advantages is clear. The M1 Max is also able to outperform desktop chips such as the 11900K, or AMD’s 5800X.
In the SPECfp suite, the M1 Max is in its own category of silicon with no comparison in the market. It completely demolishes any laptop contender, showcasing 2.2x performance of the second-best laptop chip. The M1 Max even manages to outperform the 16-core 5950X – a chip whose package power is at 142W, with rest of system even quite above that. It’s an absolutely absurd comparison and a situation we haven’t seen the likes of.
We also ran the chip with just the 8 performance cores active, as expected, the scores are a little lower at -7-9%, the 2 E-cores here represent a much smaller percentage of the total MT performance than on the M1.
Apple’s stark advantage in specific workloads here do make us ask the question how this translates into application and use-cases. We’ve never seen such a design before, so it’s not exactly clear where things would land, but I think Apple has been rather clear that their focus with these designs is catering to the content creation crowd, the power users who use the large productivity applications, be it in video editing, audio mastering, or code compiling. These are all areas where the microarchitectural characteristics of the M1 Pro/Max would shine and are likely vastly outperform any other system out there.








493 Comments
View All Comments
richardnpaul - Wednesday, October 27, 2021 - link
I'm not saying that it's not great and energy efficient marvel of technology (although you're forgetting that the compared part is Zen3 mobile 35W part which has 12MB rather than 32MB of L3 and that's partly because its a small die on 7nm).They mentioned Metal they mentioned how they can't get direct comparative results, this is one of the downsides of this, and the others from Apple, chip, great as it is it has drawbacks that hamper it which are nothing to to do with the architecture.
OreoCookie - Wednesday, October 27, 2021 - link
I don’t think I’m forgetting anything here. I am just saying that Anandtech should compare the M1 Max against actual products rather than speculate how it compares to future products like Alderlake or Zen 3 with V cache. Your claim was that the article “comes across as a fanboi article”, and I am just saying that they are just giving the chip a great review because in their low-level benchmarks it outclasses the competition in virtually every way. That’s not fanboi-ism, it is just rooted in fact.And yes, they explained the issue with APIs and the lack of optimization of games for the Mac. Given that Mac users either aren’t gamers or (if they are gamers) tend to not use their Macs for gaming, we can argue how important that drawback actually is. In more GPU compute-focussed benchmarks (e. g. by Affinity that make cross-platform creativity apps), the results of the GPU seem very impressive.
richardnpaul - Thursday, October 28, 2021 - link
My main disagreement was not them comparing with with Zen3, but more that I felt that they failed to adequately cover how the change would impact this use case scenario between M1 versions given that comparing Zen2 to Zen3 has been covered (and AMD have already said that the Vcache will mainly impact gaming and server workloads by around 15% on average) and shown in these specific use cases to have quite a large benefit and I'd just wanted that kind of abstract logical analysis of how the Max might be more positively positioned for this or these use cases above say the original M1. (I know that they mentioned in the article that they didn't have the M1 anymore and the actual AMD 5900HS device is dead which has severely impacted their testing here.I come to Anandtech specifically for the more indepth coverage that you don't get elsewhere and I come for all the hardware articles irrespective of brand because I'm interested in technology not brand names which is why I dislike articles that come across as biased (whilst it'll never be intentionally biased we're all human at the end of the day and it's hard not to let the excitement of novel tech cloud our judgement).
richardnpaul - Wednesday, October 27, 2021 - link
Also my comparison was AMD to AMD between generations and how it might apply to increasing the cache sizes of the M1 and the positive improvement it might have on performance in situations using the GPU such as gaming.Ppietra - Wednesday, October 27, 2021 - link
You are so focused on a fringe case that you don’t stop to think that "maybe" there are other things happening besides "gluing" a CPU and GPU on the same silicon, fighting for memory bandwidth. Unified memory architecture plus CPU and GPU sharing data over the system cache, has an impact on memory bandwidth needs.Besides this, looking at data that it is provided, we seem to be far from saturating memory bandwidth on a regular basis.
It would be interesting though to actually see how applications behave when truly optimised for this hardware and not just ported with some compatibility abstraction layer in the middle. Affinity Photo would probably be the best example.
richardnpaul - Wednesday, October 27, 2021 - link
This is exactly what I wanted coving in the article. If the GPU and CPU are hitting the memory subsystem they are going to be competing for cache hits. My point was that Zen3 (desktop) showed a large positive correlation between doubling the cache (or unifying it into a single blob in reality) and increased FPS in games and that that might also hold true for the increased cache on the M1 Pro and Max.Unfortunately testing this chip is hampered by decisions completely unrelated to the hardware itself, and that also applies to certain use cases.
it'll be more interesting to see testing the same games under Linux between an Nvidia/AMD/Intel based laptop as then the only differences should be the ISA; and immature drivers.
Ppietra - Wednesday, October 27, 2021 - link
"hitting the memory subsystem they are going to be competing for cache hits"CPU and GPU also have their own cache (CPU 24MB L2 total; GPU don’t know how much now) which is very substantial.
And I think you are not seeing the picture about CPU and GPU not having to duplicate resources, working on the same data in an enormous 48MB system cache (when using native APIs of course) before even needing to access RAM, reducing latency, etc. This can be very powerful. So no, I don’t assume that there will any significant impact because of some fringe case while ignoring the great benefits that it brings.
richardnpaul - Wednesday, October 27, 2021 - link
One person's fringe edge case is another person's primary use case.The 24/48MB is a shared cache between the CPU and GPU (and everything else that accesses main memory).
Ppietra - Wednesday, October 27, 2021 - link
no, it’s a fringe case period! You don’t see laptop processors with these amounts of L2 cache and system cache anywhere, not even close, and yet for some reason you feel that it would be at an disadvantage, failing to acknowledge the advantages of sharingrichardnpaul - Thursday, October 28, 2021 - link
What you call a fringe case I call 2.35m people. Okay, so it's probably on about 1.5 to 2% of Mac users; it's ~2.5% of Steam users.I know people who play games on Windows Machines because their GPUs in their Macs aren't good enough. Those people who are frustrated having to maintain a Windows machine just to play games. Those people will buy into an M1 Pro or Max just so they can be rid of the Windows system. It won't be their main concern, but then they're not going to be buying an M1 Pro/Max for the reason of rendering etc when they're a web developer, they're going to buy it so that they can dump the pain in the backside Windows gaming machine. Valve don't maintain their MacOS version of Steam for no good reason.