The Ampere Altra Max Review: Pushing it to 128 Cores per Socket
by Andrei Frumusanu on October 7, 2021 8:00 AM EST- Posted in
- Servers
- Arm
- Neoverse N1
- Ampere
- Altra Max
SPEC - Per-Core Performance under Load
A metric that is actually more interesting than isolated single-thread performance, is actually per-thread performance in a fully loaded system. This actually is a measurement and benchmark figure that would greatly interest enterprises and customers which are running software or workloads that are possibly licensed on a per-core basis, or simply workloads that require a certain level of per-thread service level agreement in terms of performance.
The Altra Max here is inevitably expected to post worse metrics than the Altra – first of all due to the 10% lower core frequencies, and second of all due to lower shared resources that need to be shared amongst more cores.
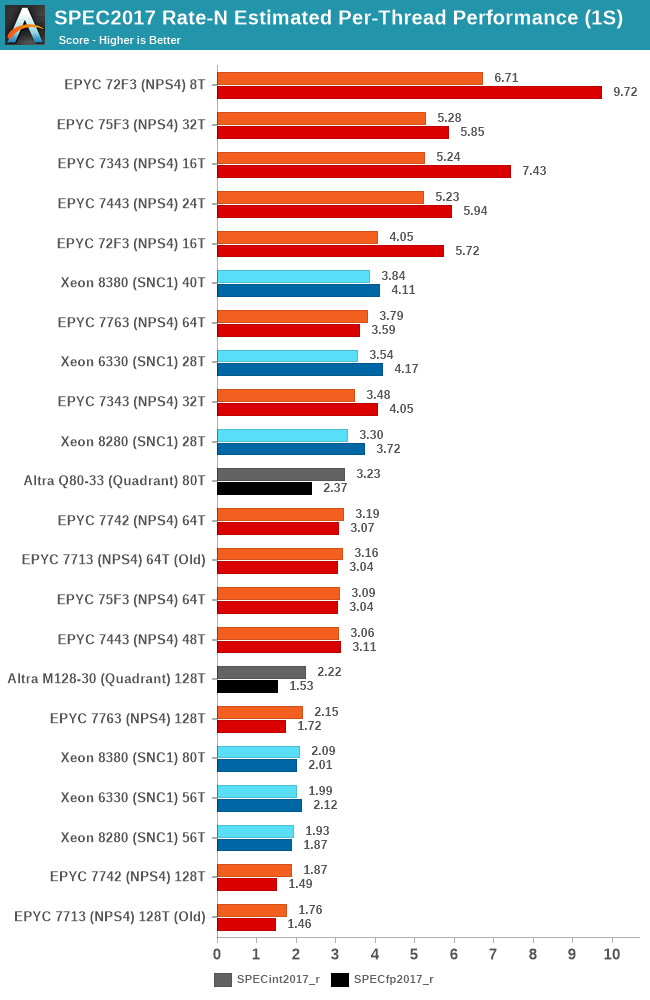
As expected, taking view of the aggregate socket performance figures here, the M128-80 doesn’t fare well here in the metric, as it takes the much controversial “flock of chickens” approach to core performance. It’s also dragged down by the score regressions in the memory bound workload in SPEC.
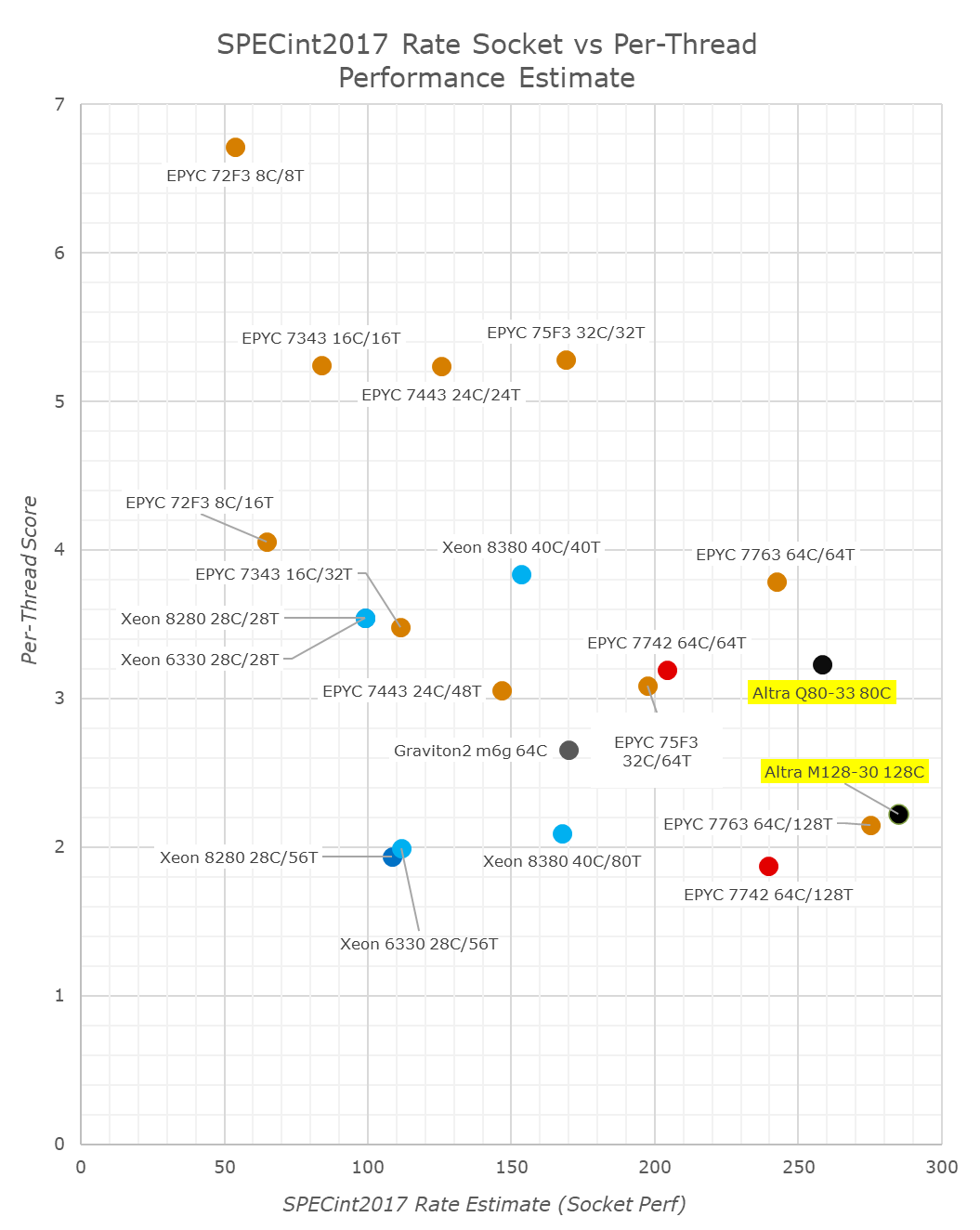
In terms of total throughput vs per-thread performance, the M128-30 barely differs to the EPYC 7763 with SMT and half the physical cores.
Again, I have to reiterate that these figures are all very much not in favour of the workloads that the Altra Max was designed for – cloud and hyperscaler workloads, which don’t tend to have the same harsher memory demands as some of the workloads in the SPEC suite. However, extracting those workloads in a different subset would also be a questionable practise and actually frowned upon.
The Altra Max here really does need to have huge footnotes in the way that it presents itself.








60 Comments
View All Comments
dullard - Thursday, October 7, 2021 - link
Far too many people mistakenly think it is AMD vs Intel. In reality it is ARM vs (AMD + Intel together).TheinsanegamerN - Thursday, October 7, 2021 - link
In reality it's AMD VS INTEL, with ARM the red headed stepchild with 3 extra chromosomes drooling in the corner. x86 still commands 99% of the server market.DougMcC - Thursday, October 7, 2021 - link
And the reason is price/performance. These chips are pricey for what they deliver, and it shows in amazon instance costs. We looked at moving to graviton 2 instances in aws and even with the in-house pricing advantage there we would be losing 55+% performance for <25% price advantage.eastcoast_pete - Thursday, October 7, 2021 - link
Was/is it really that bad? Wow! I thought AWS is making a value play for their gravitons, your example suggests that isn't working so great.mode_13h - Thursday, October 7, 2021 - link
Could be that demand is simply outstripping their supply. Amazon isn't immune from chip shortages either, you know?DougMcC - Thursday, October 7, 2021 - link
It was for us. Could be that there are workload issues specific to us, though as a pretty basic j2ee app it's somewhat hard for me to imagine that we are unique.lightningz71 - Friday, October 8, 2021 - link
It is VERY workload dependent.lemurbutton - Friday, October 8, 2021 - link
Graviton2 is now 50% of all new instances at AWS.DougMcC - Friday, October 8, 2021 - link
Not super surprising. Even with the massive loss of performance, it's still cheaper. If you don't need performance, why wouldn't you choose the cheapest thing?Wilco1 - Friday, October 8, 2021 - link
In most cases Graviton is not only cheaper but also significantly faster. It's easy to find various examples:https://docs.keydb.dev/blog/2020/03/02/blog-post/
https://about.gitlab.com/blog/2021/08/05/achieving...
https://yegorshytikov.medium.com/aws-graviton-2-ar...
https://www.instana.com/blog/best-practices-for-an...