Intel Architecture Day 2021: Alder Lake, Golden Cove, and Gracemont Detailed
by Dr. Ian Cutress & Andrei Frumusanu on August 19, 2021 9:00 AM ESTConclusions
Alder Lake is set to come to market for both desktop and mobile, and we’re expecting the desktop hardware to start to appear by the end of the year – perhaps a little later for the rest of the family, but all-in-all we expect Intel is experiencing some serious squeaky bum time regarding how all the pieces will fit in place at that launch. The two main critical factors are operating systems and memory.
Because Alder Lake is Intel’s first full-stack attempt to commercialize a hybrid design, it has had to work closely with Microsoft to enable all the features it needs to make managing a hybrid core design properly beneficial to users. Intel’s new Thread Director Technology couples an integrated microcontroller per P-core and a new API for Windows 11 such that the scheduler in the operating system can take hints about the workflow on the core at a super fine granularity – every 30 microseconds or so. With information about what each thread is doing (from heavy AVX2 down to spin lock idling), the OS can react when a new thread needs performance, and choose which threads need to be relegated down to the E-core or as a hyperthread (which is classified as slower than an E-core).

When I first learned Alder Lake was going to be a hybrid design, I was perhaps one of the most skeptical users about how it was going to work, especially with some of the limits of Windows 10. At this point today however, with the explanations I have from Intel, I’m more confident than not that they’ve done it right. Some side off-the-record conversations I have had have only bolstered the idea that Microsoft has done everything Intel has asked, and users will need Windows 11 to get that benefit. Windows 10 still has some Hardware Guided Scheduling, but it’s akin to only knowing half the story. The only question is whether Windows 11 will be fully ready by the time Alder Lake comes to market.
For memory, as a core design, Alder Lake will have support for DDR4 and DDR5, however only one can be used at any given time. Systems will have to be designed for one or the other – Intel will state that by offering both, OEMs will have the opportunity to use the right memory at the right time for the right cost, however the push to full DDR5 would simplify the platform a lot more. We’re starting to see DDR5 come to the consumer market, but not in any volume that makes any consumer sense – market research firms expect the market to be 10% DDR5 by the end of 2022, which means that consumers might have to be stay with DDR4 for a while, and vendors will have to choose whether to bundle DDR5 with their systems. Either way, there’s no easy answer to the question ‘what memory should I use with Alder Lake’.
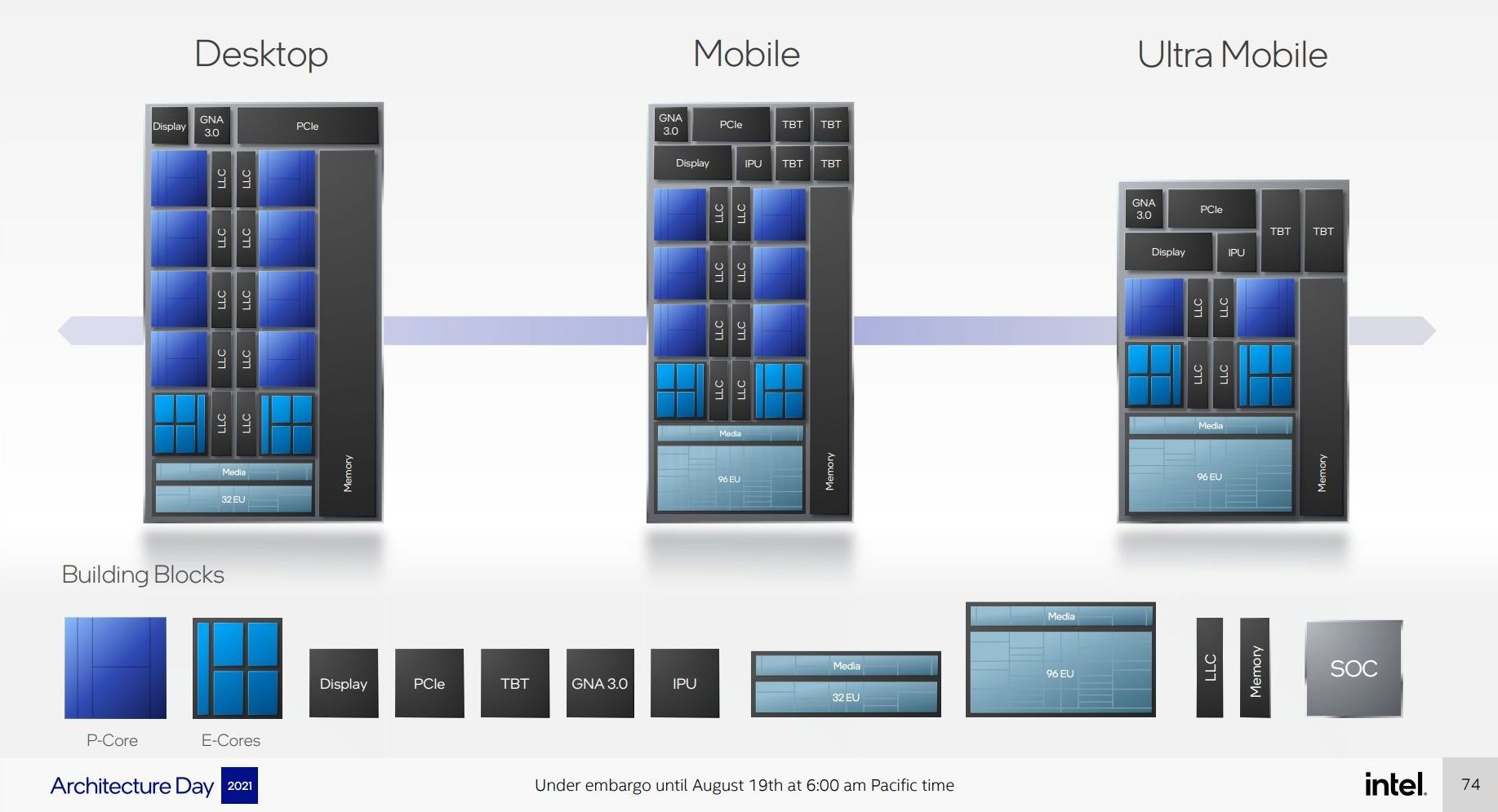
Through The Cores and The Atoms
From a design perspective, both the P-core and E-core are showcasing substantial improvements to their designs compared to previous generations.
The new Golden Cove core has upgraded the front-end decoder, which has been a sticking point for analysis of previous Cove and Lake cores. The exact details of how they operate are still being kept under wraps, but having a 6-wide variable length decoder is going to be an interesting talking point against 8-wide fixed-length decoders in the market and which one is better. The Golden Cove core also has very solid IPC figure gains, Intel saying 19%, although the fact there are some regressions is interesting. Intel did compare Golden Cove to Cypress Cove, the backported desktop core, rather than Willow Cove, the Tiger Lake core, which would have been a more apt comparison given that our testing shows Willow Cove slightly ahead. But still, around 19% is a good figure. Andrei highlights in his analysis that the move from a 10-wide to a 12-wide disaggregated execution back-end should be a good part of that performance, and that most core designs that go down this route end up being good.
However, for Gracemont, Intel has taken that concept to the extreme. Having 17 execution ports allows Intel to clock-gate each port when not in use, and even when you couple that with a smaller 5-wide allocation dispatch and 8-wide retire, it means that without specific code to keep all 17 ports fed, a good number are likely to be disabled, saving power. The performance numbers Intel provided were somewhat insane for Gracemont, suggesting +8% performance over Skylake at peak power, or a variety of 40% ST perf/power or 80% MT perf/power against Skylake. If Gracemont is truly a Skylake-beating architecture, then where have you been! I’m advocating for a 64-core HEDT chip tomorrow.
One harsh criticism Intel is going to get back is dropping AVX-512 for this generation. For the talk we had about ‘no transistor left behind’, Alder Lake dropped it hard. That’s nothing to say if the functionality will come back later, but if rumors are believed and Zen 4 has some AVX-512 support, we might be in a situation where the only latest consumer hardware on the market supporting AVX-512 is from AMD. That would be a turn-up. But AMD’s support is just a rumor, and really if Intel wants to push AVX-512 again, it will have a Sisyphean task to convince everyone it’s what the industry needs.
Where We Go From Here
There are still some unanswered questions as to the Alder Lake design, and stuff that we will test when we get the hardware in hand. Intel has an event planned for the end of October called the Intel InnovatiON event (part of the ON series), which would be the right time to introduce Alder Lake as a product to the world. Exactly when it comes to retail will be a different question, but as long as Intel executes this year on the technology, it should make for an interesting competition with the rest of the market.








223 Comments
View All Comments
GreenReaper - Friday, August 20, 2021 - link
Intel Threat Detected!ifThenError - Friday, August 20, 2021 - link
LOL!Underrated comment
mode_13h - Saturday, August 21, 2021 - link
:Ddiediealldie - Thursday, August 19, 2021 - link
I'm quite curious how their E-cores are designed. They somehow use 6-way decoder which is same width compared to P-cores. And use twice bigger I-cache, yet using 1/4 of area.Maybe it's related to design philosophy? or Atom team's a true trump card of the Intel design team?
name99 - Thursday, August 19, 2021 - link
That "6-way decoder" is typical Intel double-talk. What is done is that you have two decoders that can each decode three instructions. This works IF there is a branch between the two sets of instructions, because the branch landing point provides a resync point for the second decoder, so the two can run in parallel.You could obviously extend this, in a decent Next Fetch Predictor system, to have the NFP store the lengths of each instruction in the run of instructions to be decoded, and get trivial parallel decode. And Andy Glew (I think it was him, either him or Jim K) submitted a patent for this around 2000. But in true Intel fashion, nothing seems to have been done with the idea...
GeoffreyA - Saturday, August 21, 2021 - link
If I'm not mistaken, Tremont or Goldmont, can't remember which, began marking the instruction boundaries in cache.name99 - Saturday, August 21, 2021 - link
Doing it in the cache is more difficult. Of course it makes the most sense! But it hits the problem that, *in theory*, you can have stupid code that jumps into the middle of an instruction and starts decoding the alternative version of the byte stream that results.This is, of course, absolutely insane, but it's part of the joy that is supporting x86.
Now one way to handle this is to tag the boundaries not in the I-cache (where you can jump to any byte) but in structures that are already set up to deal with instruction streams (as opposed to byte streams). Hence the Next Fetch Predictor, as I described, or in a trace cache if you are using that.
Another solution would be yet another predictor! Assume most code will be sane, but have a separate pool of decoders that are validating the byte stream as opposed to the high-speed instruction stream going through main path of the CPU. In the event of a mismatch
- treat it like a branch misprediction, flush and restart AND
- train the predictor that for this particular cache line, we have to decode slowly and surely
Now why doesn't Intel do any of these things? You and I can think of them, just as people like Andy Glew were thinking of variants of them 20 years ago.
My primary hypothesis is that Intel has become locked into the idea that GHz is everything. Sure they occasionally say they don't believe this, or even claim to have reformed after a disaster (*cough* Pentium4 *cough*) but then they head right back to the crack house.
I suspect it's something like the same mentality as the US Air Force -- when pilots form the highest levels of command, they see pilots as the essence of what the Air Force IS; drones and UAV's are a cute distraction but will never be the real thing.
Similarly, if you see GHz as the essence of what Intel is, that smarts are cute but real men work on GHz, then you will always be sacrificing smarts if they might cut into GHz. But GHz costs the problems we see in the big cores: the crazy power draws, and the ridiculously low density...
Well, this is getting into opinion, not technology, so interpret it as you wish!
GeoffreyA - Sunday, August 22, 2021 - link
Looking at the article again, I see their on-demand instruction length decoder is where this is happening. Seems to be caching lengths after they're worked out. I also wonder if this is why Atom hasn't had a uop cache as yet. It's either that or the length caching, because the uop cache will indirectly serve that purpose as well (decoded instructions don't need their lengths worked out). So it's perhaps a matter of die area here that Intel chose that instead of a uop cache.GeoffreyA - Sunday, August 22, 2021 - link
It's been said that K7 to Bulldozer also did a similar thing, marking instruction boundaries in the cache. And the Pentium MMX, but need to double check this one.mode_13h - Sunday, August 22, 2021 - link
> In the event of a mismatch - treat it like a branch misprediction, flush and restartYes, because even assembly language doesn't make it easy to jump into the middle of another instruction. IMO, any code which does that *deserves* to run slowly, so that it will get replaced with newer software that's written in an actual programming language.
> My primary hypothesis is that Intel has become locked into the idea that GHz is everything.
I think they just got lulled into thinking it was enough to deliver modest generational gains. Anything more ambitious probably jeopardized the schedule or risked their profit margins due to the cores getting to big and expensive. And when time comes for more performance, they reach into their old playbook and go with a "sure" win, like wider vectors. I wonder if the example of TSX reveals anything about their execution, on the more innovative stuff. Because that doesn't build a lot of confidence for taking on bold, new ideas.
> when pilots form the highest levels of command,
> they see pilots as the essence of what the Air Force IS
Not just pilots, but specifically fighter pilots. So, they also don't care much about bombers or Space Command (now Space Force). The only way to change that would be to make them care, by making them more accountable for the other programs, until they realize they need them to be run by someone who know about that stuff. Either that or just reorg the whole military. That would probably also help reign in defense spending.