AMD EPYC Milan Review Part 2: Testing 8 to 64 Cores in a Production Platform
by Andrei Frumusanu on June 25, 2021 9:30 AM ESTSPEC - Multi-Threaded Performance - Subscores
Picking up from the power efficiency discussion, let’s dive directly into the multi-threaded SPEC results. As usual, because these are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2 (for Zen3 as well due to GCC 10.2 not having znver3).
I’ll be going over two chart comparisons, first of all, with the respective flagship parts, consisting of the new EPYC 7763 numbers, pitted against Intel’s 40-core Xeon Ice Lake SP and Ampere’s Altra Q80-33, along with the figures we have on AMD’s EPYC 7742. It’s to be noted that this latter is a 225W part, compared to the 280W 7763.
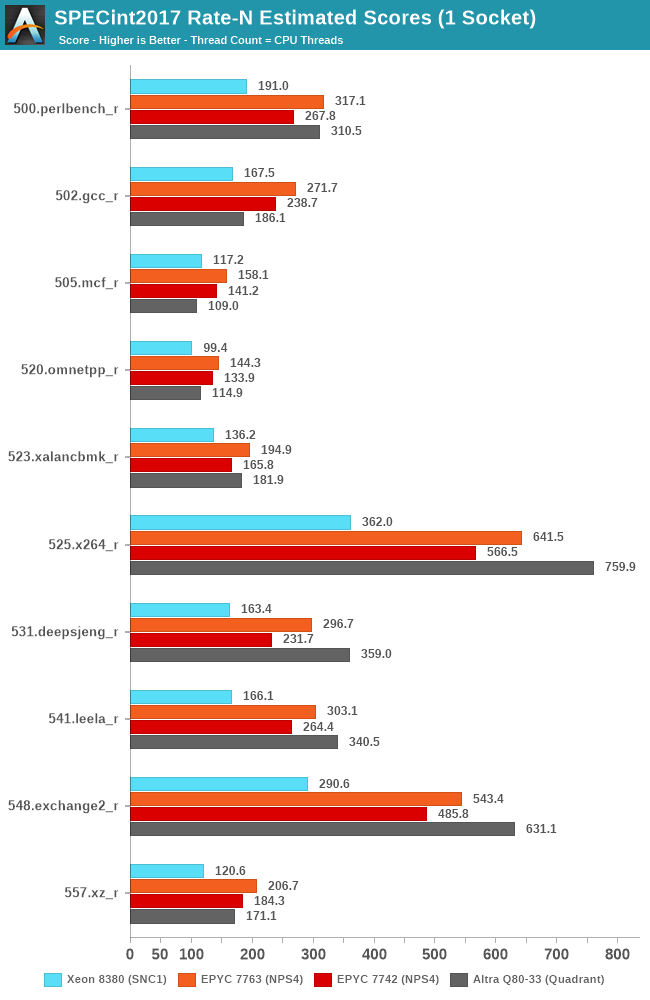
In SPECint2017, the EPYC 7763 extends its lead over Intel’s current best CPU, improving the numbers beyond what we had originally published in our April review. While AMD also further narrows the gap to Ampere’s 80-core Altra SKU, there are still many core-bound workloads that still notably favour the Neoverse N1 part given its 25% advantage in core count.
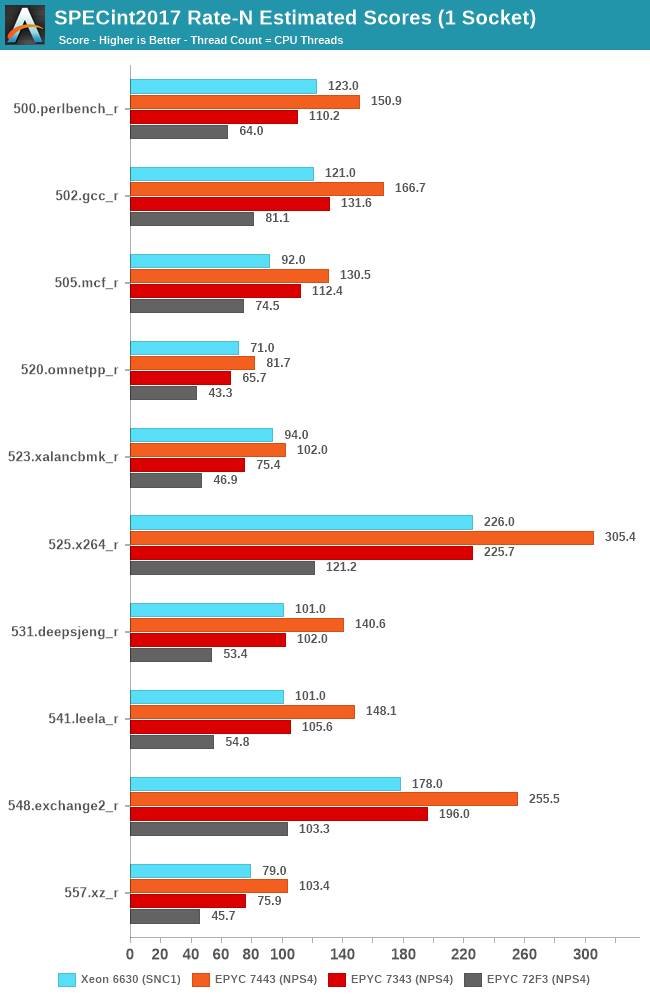
Also in SPECint2017, but this time focusing on the mid-tier SKUs, the main comparison points that are interesting here is the new 24-core EPYC 7443 and 16-core EPYC 7343 against the new 28-core Xeon 6330. What’s shocking here, is that Intel’s new Ice Lake SP server chip has troubles not only competing against AMD’s 24-core chip, but actually even struggles to differentiate itself from AMD’s 16-core chip, which is quite shocking.
The 72F3 8-core part is interesting, but generally we have troubles to competitively place such a SKU given that we don’t have a comparable part from the competition to pit against it.
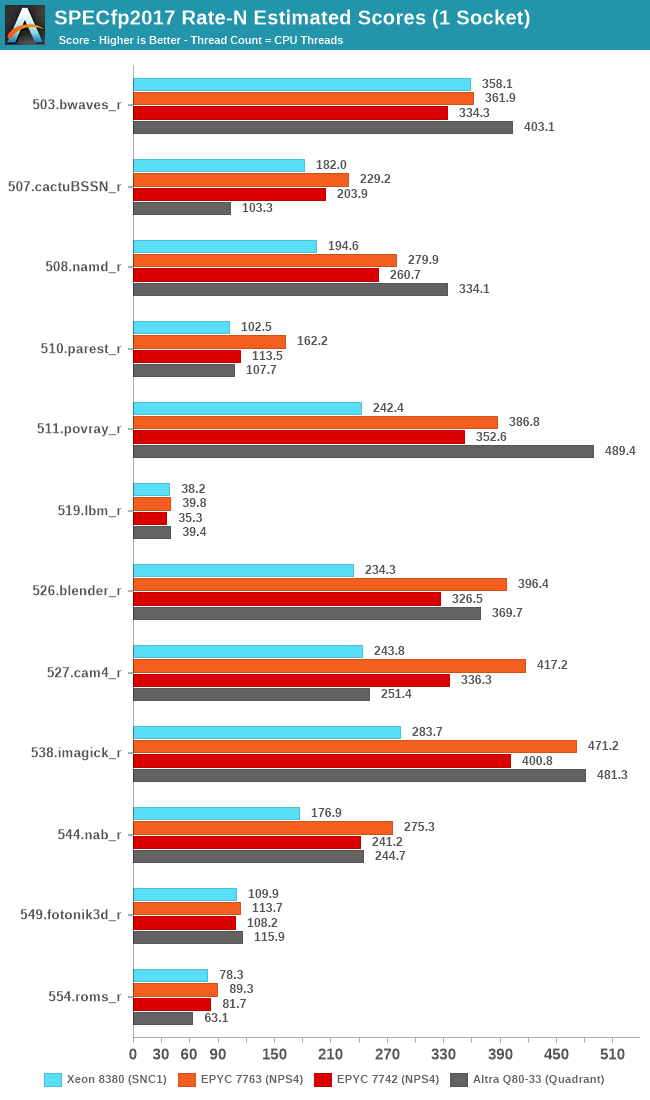
For the high-end SKUs, we again see the 7763 increase its performance positioning compared to what we had review a few months ago, although with fewer large performance boost outliers, due o the memory-heavy nature of the floating-point test suite.
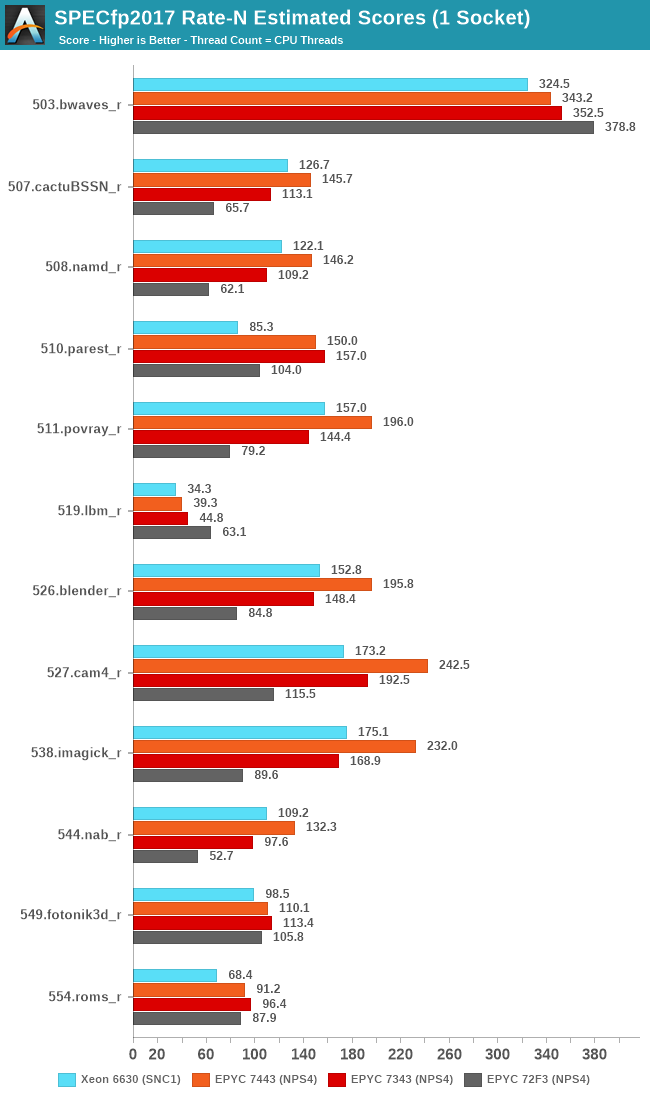
In the low-end SKUs, we see a similar story as in the integer suite, where AMD’s 16-core 7343 battles it out against Intel’s 28-core Xeon, while the 24-core unit is comfortable a good margin ahead of the competition.
The 72F3 showcases some interesting score here – because there’s more workloads that are fundamentally memory bound; the actual core count deficit of this SKU doesn’t really hamper its performance compared to its siblings. If anything, the lower core count actually has some positive side-effects as it results in less cache and DRAM contention, resulting in less overhead and actually higher performance than the higher core count parts. Theoretically you could mimic this with the higher core count parts by simply running fewer workload instances and threads, but if a system deployment would be running workloads that are more typical of such performance characteristics, the low-core count 72F3 could make sense.








58 Comments
View All Comments
Andrei Frumusanu - Friday, June 25, 2021 - link
Those results don't contradict anything I'm saying. Given a normalised throughput performance of the socket, for example here where the 16- and 24- core Milan equals or beats the 28-core ICL-SP in many workloads, the Xeon still handily beats those Milan parts in transactional workloads. The 40-core Xeon has 77% of the jbb performance of the 64-core EPYC even though in the int suite it's only at 60%. Those particular STH results work out because the 7543P is $1000 cheaper than the 7543, but for the SKUs we had in today, Intel still is on equal footing in terms of DB performance value.Cllaymenn - Friday, June 25, 2021 - link
Whatever one says about some insignificant single anomaly in some DB test... The fact is that ANY company, from small to large, any corporation needing power, any data centre, hosting, cloud computing, research institutes, universities, will choose EPYC on ZEN3 over even the 8320, because it will allow them to compute faster, make more money per month, and less stress for administrators when there are higher network loads, clouds because AMD will "grind" / process faster the requests/needs of thousands of of thousands of clients simultaneously using servers, because in addition to more compute power has more bandwidth AMD platform especially with 256 threads and 8 channel memory and fast Infinity Fabric and many of the ZEN3 optimizations... and is more flexible (harder to clog or jam Zen2/Zen3 from what I've noticed. ) These processors grind through anything you throw at them without any breathlessness.schujj07 - Friday, June 25, 2021 - link
While Spec is an "industry standard" benchmark, vendors spend hours optimizing for their servers to look better. Therefore as an administrator and designer of a high performance data-center I personally look at Spec results with a grain of salt. For example, Super Micro submitted data for 2 of their A+ AS-1124US-TNRP with dual 75F3 on April 26, 2021. One system has max-jOPS of 276,317 and critial-jOPS of 116,628. The other has a score of 211,179 max-jOPS & 191,813 critical-jOPS. They also have 2 X12DPG-QT6 with dual 8380's and one has scores of 272,500 for max-jOPS & 147,409 for critical-jOPS. The other has scores of 258,368 for max-jOPS & 201,334 for critical-jOPS. In these cases the 75F3 with few cores and threads ends up in a virtual tie with the 8380 in the transactional workload for one of the results, but the second result in the database is a 22-30% lower based on comparison systems. https://www.spec.org/jbb2015/results/res2021q2/Depending on the results you want, the 75F3 is a much better value or of equal value to the 8380. I think now you can see why I take Spec with a grain of salt on their results. Globally saying that Milan has issues in transactional DBs based solely on Spec results isn't a good idea. While I know it is the benchmarks that you choose as they are "industry standard," I think it would be worth while to invest in creating an actual real world scenario DB benchmark that doesn't use Spec.
Andrei Frumusanu - Friday, June 25, 2021 - link
> One system has max-jOPS of 276,317 and critial-jOPS of 116,628. The other has a score of 211,179 max-jOPS & 191,813 critical-jOPS.Which generally makes submitted scores not very useful, we're using apples-to-apples runs here, and while you can argue they're not as optimised, they're comparable to each other.
And I also never said that Milan has *issues*, I'm simply saying that compared to other workloads where there's a massive performance lead for AMD, Intel is still competitive, a view that falls in line with many industry customers.
Cllaymenn - Friday, June 25, 2021 - link
We know that Intel watches the Anandtech website, and that you are aware of this, they also send you expensive hardware for testing, and hope that the results will be more favourable to their new development (e.g. 8320) which they have been working on for a long time. I think it would be unpleasant and uncomfortable to criticise their new products harshly if I were writing a review, but I would rather gently point out which is good at what, which is leading and which still needs to catch up. Because of the awareness of the efforts of hundreds or even thousands of Intel engineers I would not have the heart to criticize their new product, or sharply, clearly say who wins everything and the rest can hide. I know that even the engineers, designers and CPU architects like to read about their new baby after work, and they go to sites like Anandtech with enthusiasm and quiet hope that they have made a better impression on the reviewer and readers, than their previous older products, that we have noticed a significant difference, jump in performance and that it has been appreciated and maybe there will be some nice, positive comments, feedback. It probably gives them a lot of happiness to see people out there enjoying the results of their hard work and another success for the company. Because the 8320 was a huge challenge for these people, it's a brand new fresh 10nm SuperFin technology and a mega monolithic 40 core big piece of silicon. And it works! It may not catch up with the 64 core competition but it's still a huge step forward for them, reaching a significant milestone. Once they mastered this SuperFin 10nm technology to create monolithic 40 core chips they now have a lot of experience and know how to do it even better, especially in a modular architecture where the silicon pieces will be smaller. Many of the threads stem from the creation of the Xeon 8320, so I understand the reviewer's attitude of appreciating the level of technology, sophistication, and performance of their new design. (sorry for some grammatical errors, I'm still improving)bwhitty - Friday, June 25, 2021 - link
Can't tell if you're very subtly implying Andrei is coloring the results in favor of Intel? Perhaps you're not, but anyways it doesn't seem he is. Other than that, I agree thatSmall correction: Ice Lake is on 10nm+, not Super Fin. Tiger Lake is 10SF (10++), and Sapphire Rapids will be on 10 Enhance Super Fin, so 10nm+++.
Tangent: I think that Ice Lake being on the non-SF process actually bodes extremely well for Sapphire Rapids because Ice Lake even in laptops is just not that good from a mfg perspective. It's basically Intel 10nm's first shippable and salvaged process. Super Fin appears far, far better in Tiger Lake versus Ice Lake, and so an improvement on top of that thusly should perhaps finally bring Intel's mfg in line with TSMC 7nm. That gives Sapphire Rapids a good place to be in the first half of 2022 until Genoa rolls out on TSMC 5nm is late 2022 / early 2023.
Cllaymenn - Friday, June 25, 2021 - link
bwhitty. I did not mean favoring Intel products, but a more subdued way of speaking about their performance in relation to ZEN3, a way other than the popular Linus on YT, which is sharply pressing Intel with each premiere of new AMD products.As for Super Fin, I read about it recently in one of the popular IT websites. I typed in google and found a quote
"Intel Xeon Scalable Ice Lake-SP processors were announced some time ago, but we had to wait a while for their premiere. We finally got it - we got to know the technical details of the units, as well as their performance results. Intel Xeon Scalable units (Ice Lake-SP) use the new Sunny Cove microarchitecture, which is expected to translate into up to a 20% increase in IPC over the previous generation Skylake. The chipsets are manufactured using a new 10nm SuperFin process.
As I checked with a few other sources, I now know that this site was wrong about the 83xx series.
Ian Cutress - Friday, June 25, 2021 - link
On 10nm naming, Intel has changed it twice. There are no + or ++ any more.https://www.anandtech.com/show/16107/what-products...
bwhitty - Monday, June 28, 2021 - link
Oh yes, Dr Cutress, I know all these Intel mfg node specifics purely from Anandtech’s breakdownsoutsideloop - Friday, June 25, 2021 - link
Far, far better? Tiger Lake H still sucks power like an anebriated Cleopatra.