AMD EPYC Milan Review Part 2: Testing 8 to 64 Cores in a Production Platform
by Andrei Frumusanu on June 25, 2021 9:30 AM ESTCompiling Performance / LLVM
As we’re trying to rebuild our server test suite piece by piece – and there’s still a lot of work go ahead to get a good representative “real world” set of workloads, one more highly desired benchmark amongst readers was a more realistic compilation suite. Chrome and LLVM codebases being the most requested, I landed on LLVM as it’s fairly easy to set up and straightforward.
git clone https://github.com/llvm/llvm-project.gitcd llvm-projectgit checkout release/11.xmkdir ./buildcd ..mkdir llvm-project-tmpfssudo mount -t tmpfs -o size=10G,mode=1777 tmpfs ./llvm-project-tmpfscp -r llvm-project/* llvm-project-tmpfscd ./llvm-project-tmpfs/buildcmake -G Ninja \ -DLLVM_ENABLE_PROJECTS="clang;libcxx;libcxxabi;lldb;compiler-rt;lld" \ -DCMAKE_BUILD_TYPE=Release ../llvmtime cmake --build .We’re using the LLVM 11.0.0 release as the build target version, and we’re compiling Clang, libc++abi, LLDB, Compiler-RT and LLD using GCC 10.2 (self-compiled). To avoid any concerns about I/O we’re building things on a ramdisk. We’re measuring the actual build time and don’t include the configuration phase as usually in the real world that doesn’t happen repeatedly.
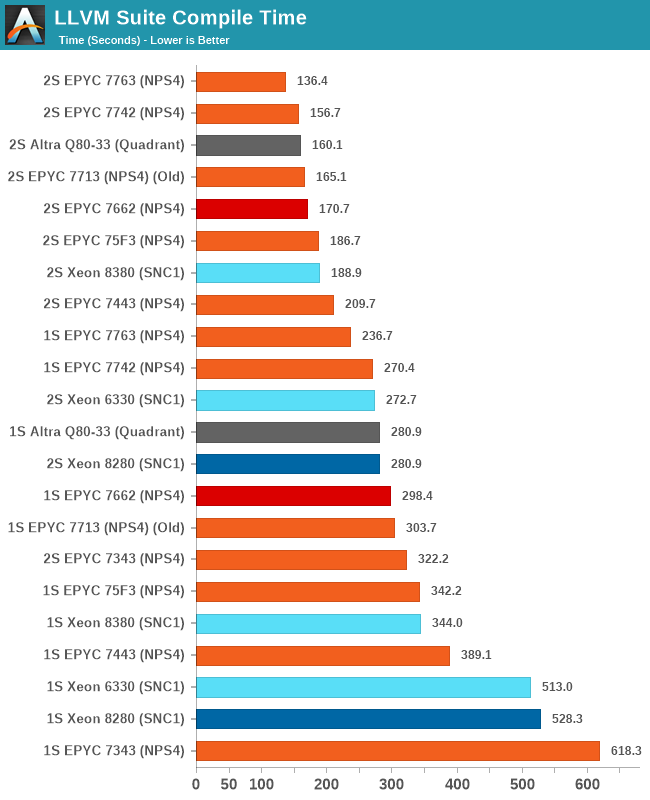
In compiling workloads, the 7763 and 75F3 also saw a 3-4% increase in performance compared to their initial reviews.
The 16-core 7343 ends up as the worst performing chip in this metric, while the 24-core 7443 still managed to put itself well ahead of the 28-core Xeon 6330.
I’ve omitted the 72F3 from the chart due to its bad results of >17 minutes per socket rescaling the chart too much – obviously compiling is not the use-case for that SKU.








58 Comments
View All Comments
Threska - Sunday, June 27, 2021 - link
Seems the only thing blunted is the economics of throwing more hardware at the problem. Actual technical development has taken off because all the chip-makers have multiple customers across many domains. That's why Anandtech and others are able to have articles like they have.tygrus - Sunday, June 27, 2021 - link
Reminds me of the inn keeper from Les Miserables. Nice to your face with lots of good promises but then tries to squeeze more money out of the customer at every turn.tygrus - Sunday, June 27, 2021 - link
I was ofcourse referring to the SW not the CPU.130rne - Tuesday, September 14, 2021 - link
What the hell did I just read? Just came across this, I had no idea the enterprise side was this fucked. They are scalping the ungodly dog shit out of their own customers. So you obviously can't duplicate their software in house meaning you're forced to use their software to be competitive, that seems to be the gist. So I buy a stronger cpu, usually a newer model, yeah? And it's more power efficient, and I restrict the software to a certain number of threads on those cpus, they'll just switch the pricing model because I have a better processor. This would incentivize me to buy cheaper processors with less threads, yeah? Buy only what I need.130rne - Tuesday, September 14, 2021 - link
Continued- basically gimping my own business, do I have that right? Yes? Ok cool, just making sure.eachus - Thursday, July 15, 2021 - link
There is a compelling use case that builders of military systems will be aware of. If you have an in-memory database and need real-time performance, this is your chip. Real-time doesn't mean really fast, it means that the performance of any command will finish within a specified time. So copy the database on initialization into the L3 cache, and assuming the process is handing the data to another computer for further processing, the data will stay in the cache. (Writes, of course, will go to main memory as well, but that's fine. You shouldn't be doing many writes, and again the time will be predictable--just longer.)I've been retired for over a decade now, so I don't have any knowledge of systems currently being developed.
Who would use a system like this? A good example would be a radar recognition and countermeasures database. The fighter (or other aircraft) needs that data within milliseconds, microseconds is better.
hobbified - Thursday, August 19, 2021 - link
At the time I was involved in that (~2010) it was per-core, with multiple cores on a package counting as "half a CPU" — that is, 1 core = 1CPU license, two 1-core packages = 2CPU license, one 2-core package = 1CPU license, 4 cores total = 2CPU license, etc.I'm told they do things in a completely different (but no less money-hungry) way these days.
lemurbutton - Friday, June 25, 2021 - link
Can we get some metrics on $/performance as well as power/performance? I think the Altra part would be better value there.schujj07 - Friday, June 25, 2021 - link
"Database workloads are admittedly still AMD’s weakness here, but in every other scenario, it’s clear which is the better value proposition." I find this conclusion a bit odd. In MultiJVM max-jOPS the 2S 24c 7443 has ~70% the performance of the 2S 40c 8380 (SNC1 best result) despite having 60% the cores of the 8380. In the critical-jOPS the 7443's performance is between the 8380's SNC1 & SNC2 results despite the core disadvantage. To me that means that the DB performance of the Epyc isn't a weakness.I have personally run the SAP HANA PRD performance test on Epyc 7302's & 7401's. Both CPUs passed the SAP HANA PRD performance test requirements on ESXi 6.7 U3. However, I do not have scores from Intel based hosts for comparison of scores.
schujj07 - Friday, June 25, 2021 - link
The DB conclusion also contradicts what I have read on other sites. https://www.servethehome.com/amd-epyc-7763-review-... Look at the MariaDB numbers for explanation of what is being analyzed. Their 32c Epyc &543p vs Xeon 6314U is also a nice core count vs core count comparison. https://www.servethehome.com/intel-xeon-gold-6314u... In that the Epyc is ~20%+ faster in Maria than the Xeon.