Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
A new CI-700 Coherent Interconnect & NI-700 NoC For SoCs
Finally, the last new announcement of the day is a new interconnect and network-on-chip generation. The last time Arm had announced a mobile/client interconnect was back in in 2015 with the CCI-550. The reason for the large gap between IPs, in Arm’s own words, is that ever since Arm’s introduction of the DSU in its CPU complexes, there really hasn’t been any need for a cache coherent interconnect in the market. While that’s eyebrow-raising from a GPU perspective, it makes perfect sense from a CPU perspective, as coherency between CPU cores was the primary driver for such interconnects until then.
With the advent of new more complex computing platforms, such as NPUs, accelerators, and hopeful more use of GPUs in cache-coherent fashions, Arm saw a need gap in its portfolio and decided to update its client-side interconnect IP.


The new CI-700 is a mobile and client optimised variant of Arm’s infrastructure CMN mesh network, implementing important new interoperability with the new IP announced today, such as the new DSU or CPU cores.
The new mesh interconnect scales up from 1 to 8 DSU clusters, and supports up to 8 memory controllers, and also introduces innovations such as a system level cache.
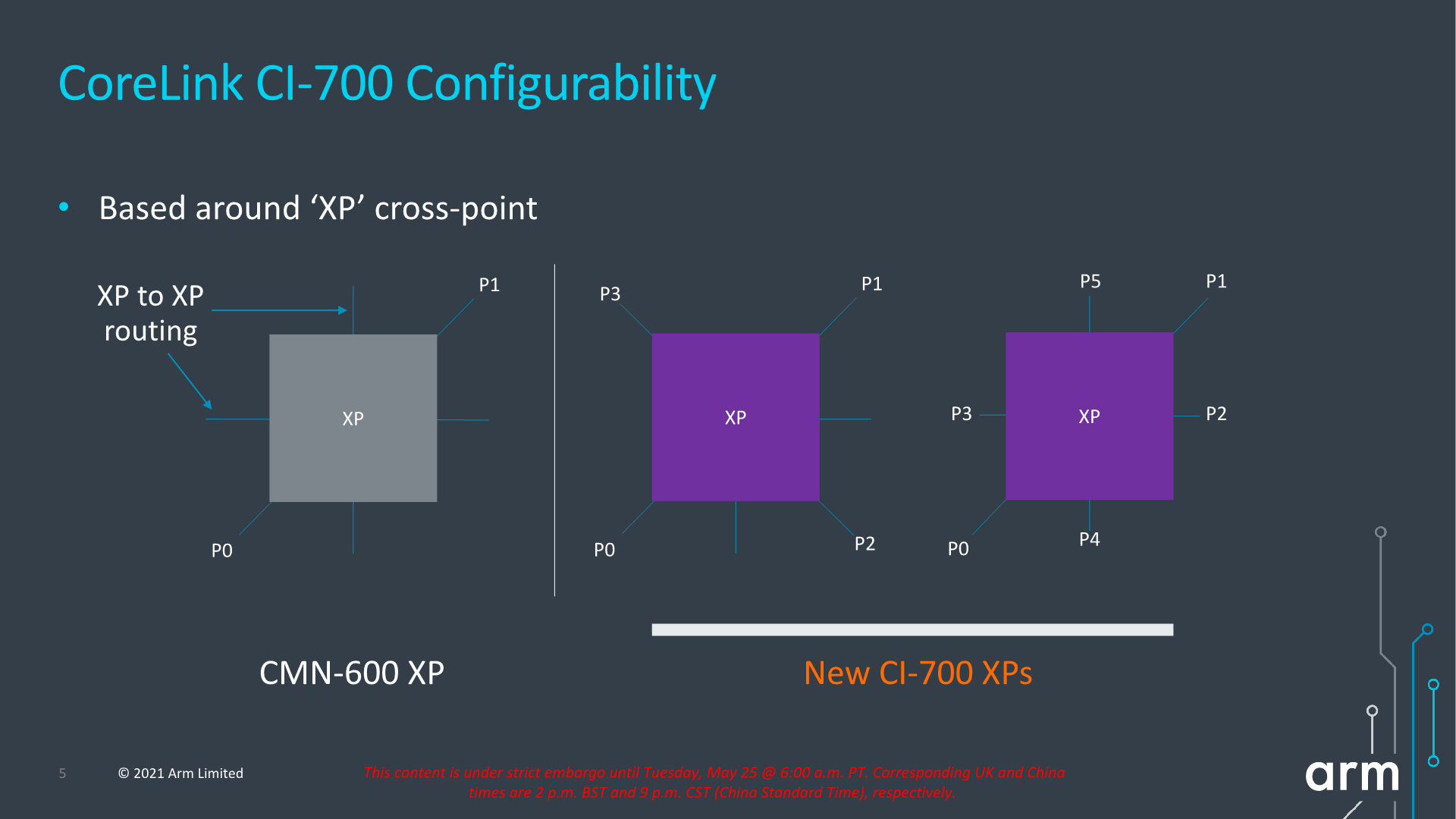

The mesh network topology and building blocks is very similar to what we’ve seen in the CMN infrastructure IP, in that “points” in the mesh are comprised of “cross-points” or “XP”. One differentiation that’s unique to the client mesh implementation is that XPs can have more attached connectivity ports, trading in routing connection paths. The new IP can also be configured as just a sole XP with no real mesh so to speak of, or essentially a 1x1 mesh configuration. This can grow up to a 4x3 mesh in the largest possible configuration.
The mesh supports from 1 to 8 SLC slices, with up to 4MB per slice for a total of 32MB, and snoop filter SRAM with coverage of up to 8MB address space per slice. It’s noted that generally Arm recommends 1.5-2x of coverage of the underlying private cache hierarchies of the mesh clients.
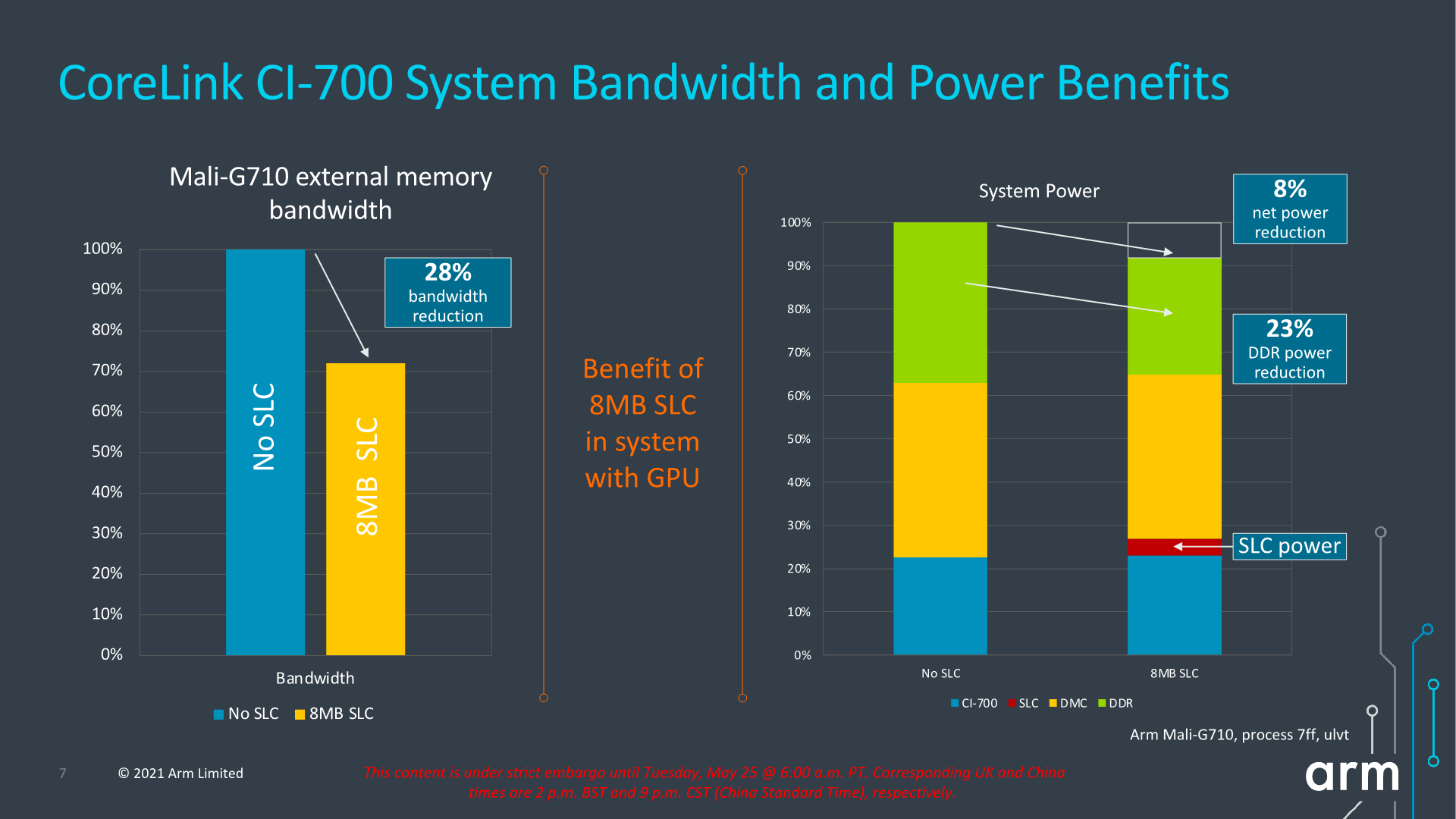
The SLC can server as both a bandwidth amplifier as well as reducing external memory/DRAM transactions, reducing system power reduction.
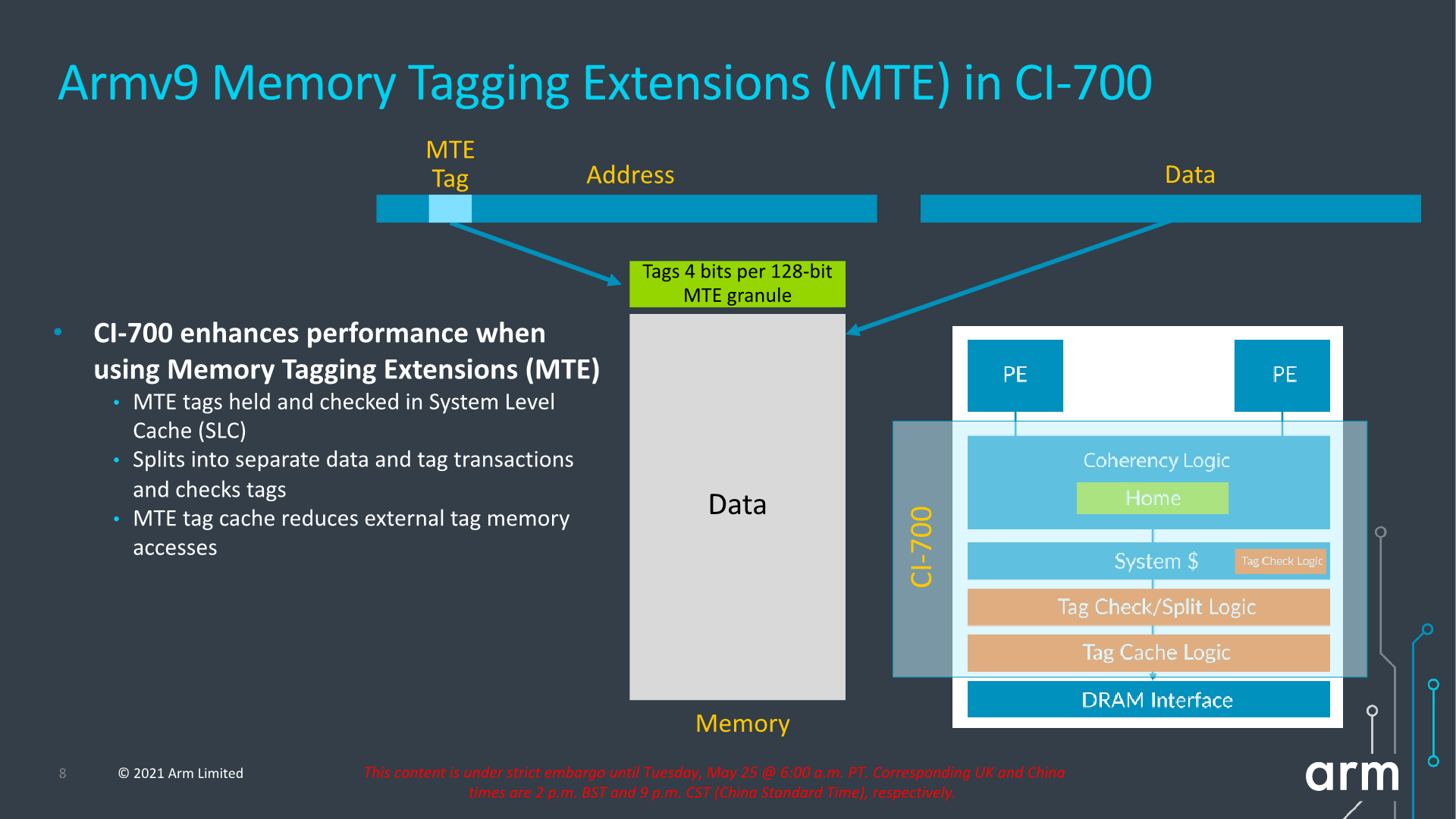
We see a reiteration of the support for MTE, allowing for this generation of IPs to support the feature across the new CPU IP, the DSU, and the new cache coherent interconnect.

Alongside the new CI-700 coherent interconnect, we’re also seeing a new NI-700 network-on-chip for non-coherent data transfers between a SoC’s various IP blocks. The big new improvements here is the introduction of packetization for data transfers, which leads to a reduction of wires and thus improves area efficiency of the NoC on the SoC.
Overall, the new system IP announced today is very interesting, but the one question that’s one has to ask oneself is exactly who these net interconnects are meant for. Over the last few years, we’ve seen essentially every major mobile vendor roll out their own in-house cache-coherent interconnect IP, such as Samsung’s SCI or MediaTek’s MCSI, and other times we don’t see vendors talk about their in-house interconnects at all (Qualcomm). Due to almost everybody having their own IP, I’m not sure what the likelihood would be that any of the big players would jump back to Arm’s own solutions – if somebody were to adopt it, it would rather be amongst the smaller name vendors and newcomers to the market. From a business and IP portfolio perspective, the new designs make a lot of sense and allows to have the building blocks to create a mostly Arm-only SoC, which is an important item to have on the menu for Arm’s more diverse customer base.








181 Comments
View All Comments
WorBlux - Thursday, May 27, 2021 - link
These micro-ops are greatly exaggerated. For instance Gracemont CPU's don't have any. And 4 of the 5 decoders on intel are simple, meaning they only drop one micro-op per instruction.Having to deal with a variable length instruction is still a bitch on the front end.
mode_13h - Saturday, May 29, 2021 - link
> Gracemont CPU's don't have any.I think you meant to say they don't have micro-op *caches*.
Tomatotech - Tuesday, May 25, 2021 - link
They’re correct. x86 cores have been RISC internally since the Pentium era. They’re black boxes that take CISC instructions, then internally these instructions are converted to RISC for the microprocessors.See the Development section of this wiki article for the Pentium. Later chips expanded and further developed the internal RISC parts after the success of the Pentium. Sorry to shatter your illusions.
https://en.wikipedia.org/wiki/P5_(microarchitectur...
Wilco1 - Tuesday, May 25, 2021 - link
RISC/CISC is only ever about the ISA, never about implementation. Even the very first 8086 uses simpler micro-ops internally in its microcode, but that doesn't make it any more RISC than modern implementations.Another common misconception that changing the decoder is all that is required to change ISAs. This is also incorrect since the internals are very different between ISAs.
Thala - Tuesday, May 25, 2021 - link
Precisely. x86 will never escape from the problem:- having variable length instructions
- having less architectural registers
- having TSO memory model
And no internal RISC-like microarchitecture will help with above issues.
GeoffreyA - Wednesday, May 26, 2021 - link
"having variable length instructions"The main bottleneck of x86 and the part where ARM has the upper hand. Still, it's not impossible that some genius at AMD or Intel could crack the variable-length handicap once and for all. The micro-op cache did much. Something else is still missing.
mode_13h - Wednesday, May 26, 2021 - link
> Still, it's not impossible that some genius at AMD or> Intel could crack the variable-length handicap once and for all.
The only solution I see to that is basically letting the uop cache spill to RAM, so the decoder works more like a JIT translation engine.
And that only solves *one* of x86's key detriments.
GeoffreyA - Thursday, May 27, 2021 - link
That's a possibility but more work on the OS side. In that case, it might be better to switch to a new, fixed-length ISA altogether.If there were some way to index instruction start/end before reaching the decoder. Perhaps the compiler could help but that might break compatibility.
mode_13h - Saturday, May 29, 2021 - link
> That's a possibility but more work on the OS side.Yes. The era of "free" CPU performance improvements is coming to an end.
> In that case, it might be better to switch to a new, fixed-length ISA altogether.
Well, it's one thing Intel or AMD could do to eke a little more life out of x86-64. I think it's actually not a lot to ask from operating systems.
> If there were some way to index instruction start/end before reaching the decoder.
Perhaps the L1 instruction cache could do some preliminary analysis, during fills. They could add a couple extra bits per byte, to hold information subsequently useful to the decoder.
Or, maybe the decoder could just write back some info to help itself, if it needs to re-decode those same instructions after the corresponding micro-ops have been evicted from the micro-op cache.
GeoffreyA - Monday, May 31, 2021 - link
"Perhaps the L1 instruction cache could do some preliminary analysis"Interestingly, some CPUs did mark the instruction boundaries in the cache. Possibly the same principle. If I remember right, the Pentium MMX and some of the Atoms; and on AMD's side, K7 all the way to Bulldozer.