Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
A new CI-700 Coherent Interconnect & NI-700 NoC For SoCs
Finally, the last new announcement of the day is a new interconnect and network-on-chip generation. The last time Arm had announced a mobile/client interconnect was back in in 2015 with the CCI-550. The reason for the large gap between IPs, in Arm’s own words, is that ever since Arm’s introduction of the DSU in its CPU complexes, there really hasn’t been any need for a cache coherent interconnect in the market. While that’s eyebrow-raising from a GPU perspective, it makes perfect sense from a CPU perspective, as coherency between CPU cores was the primary driver for such interconnects until then.
With the advent of new more complex computing platforms, such as NPUs, accelerators, and hopeful more use of GPUs in cache-coherent fashions, Arm saw a need gap in its portfolio and decided to update its client-side interconnect IP.


The new CI-700 is a mobile and client optimised variant of Arm’s infrastructure CMN mesh network, implementing important new interoperability with the new IP announced today, such as the new DSU or CPU cores.
The new mesh interconnect scales up from 1 to 8 DSU clusters, and supports up to 8 memory controllers, and also introduces innovations such as a system level cache.
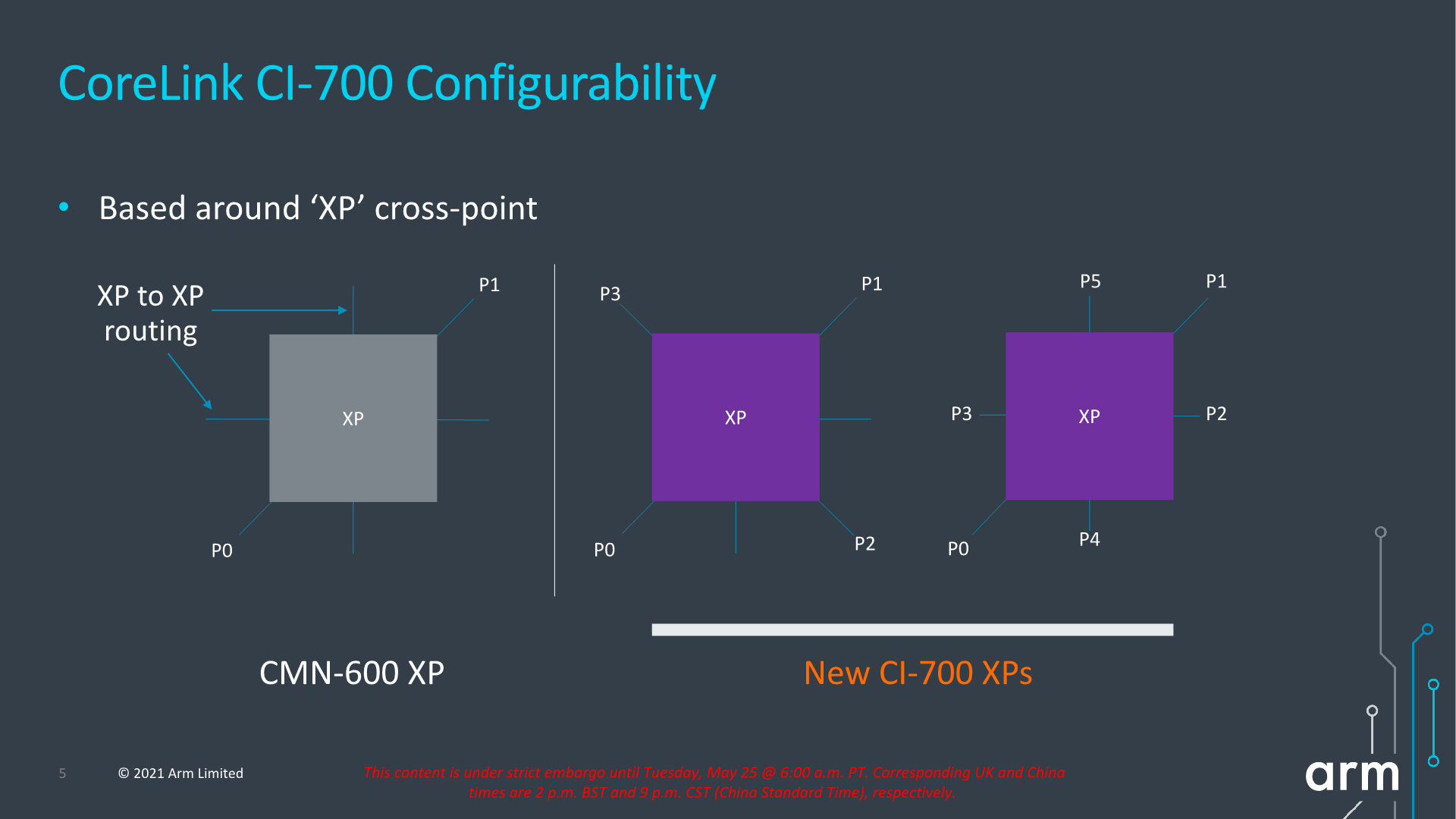

The mesh network topology and building blocks is very similar to what we’ve seen in the CMN infrastructure IP, in that “points” in the mesh are comprised of “cross-points” or “XP”. One differentiation that’s unique to the client mesh implementation is that XPs can have more attached connectivity ports, trading in routing connection paths. The new IP can also be configured as just a sole XP with no real mesh so to speak of, or essentially a 1x1 mesh configuration. This can grow up to a 4x3 mesh in the largest possible configuration.
The mesh supports from 1 to 8 SLC slices, with up to 4MB per slice for a total of 32MB, and snoop filter SRAM with coverage of up to 8MB address space per slice. It’s noted that generally Arm recommends 1.5-2x of coverage of the underlying private cache hierarchies of the mesh clients.
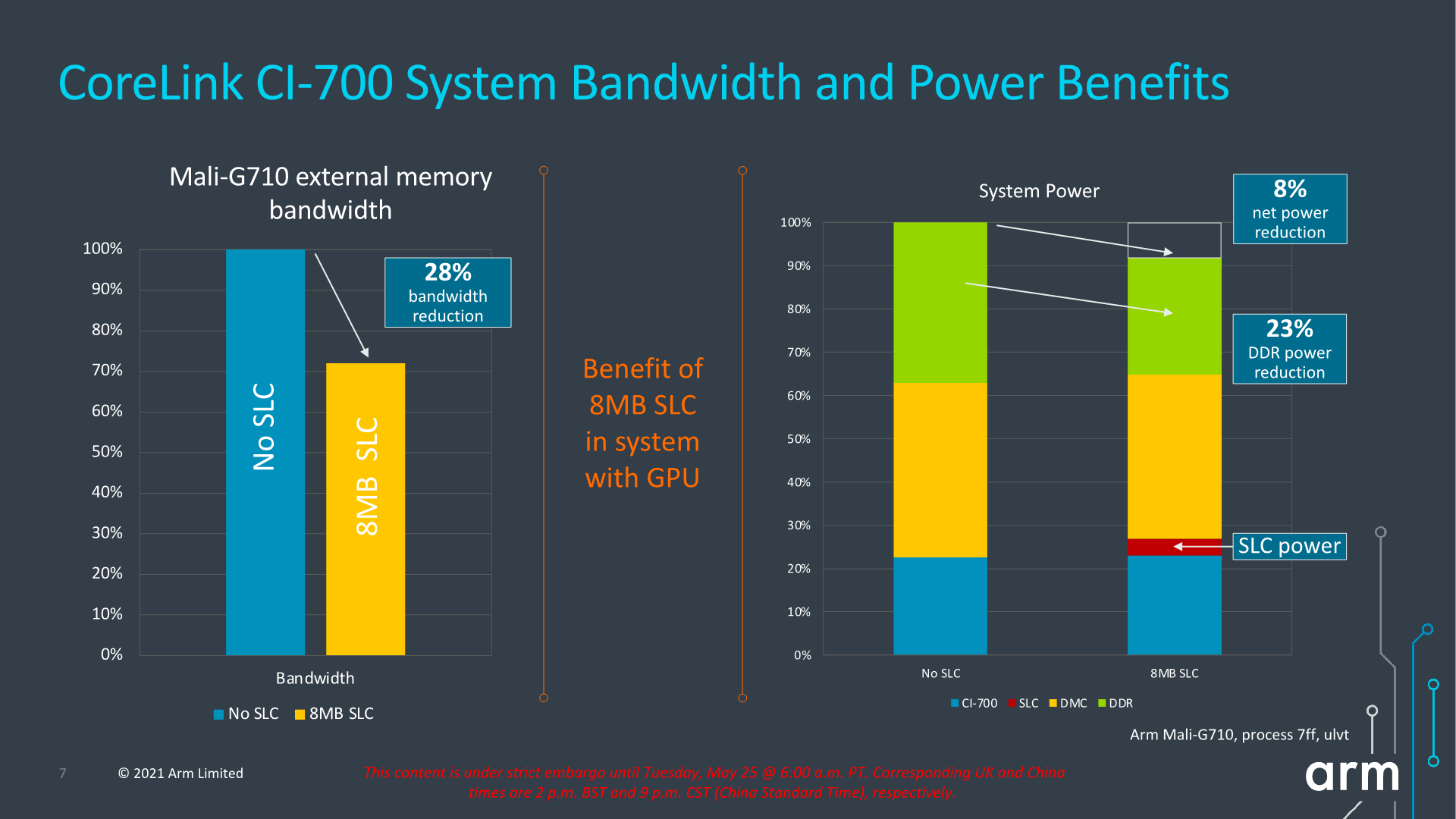
The SLC can server as both a bandwidth amplifier as well as reducing external memory/DRAM transactions, reducing system power reduction.
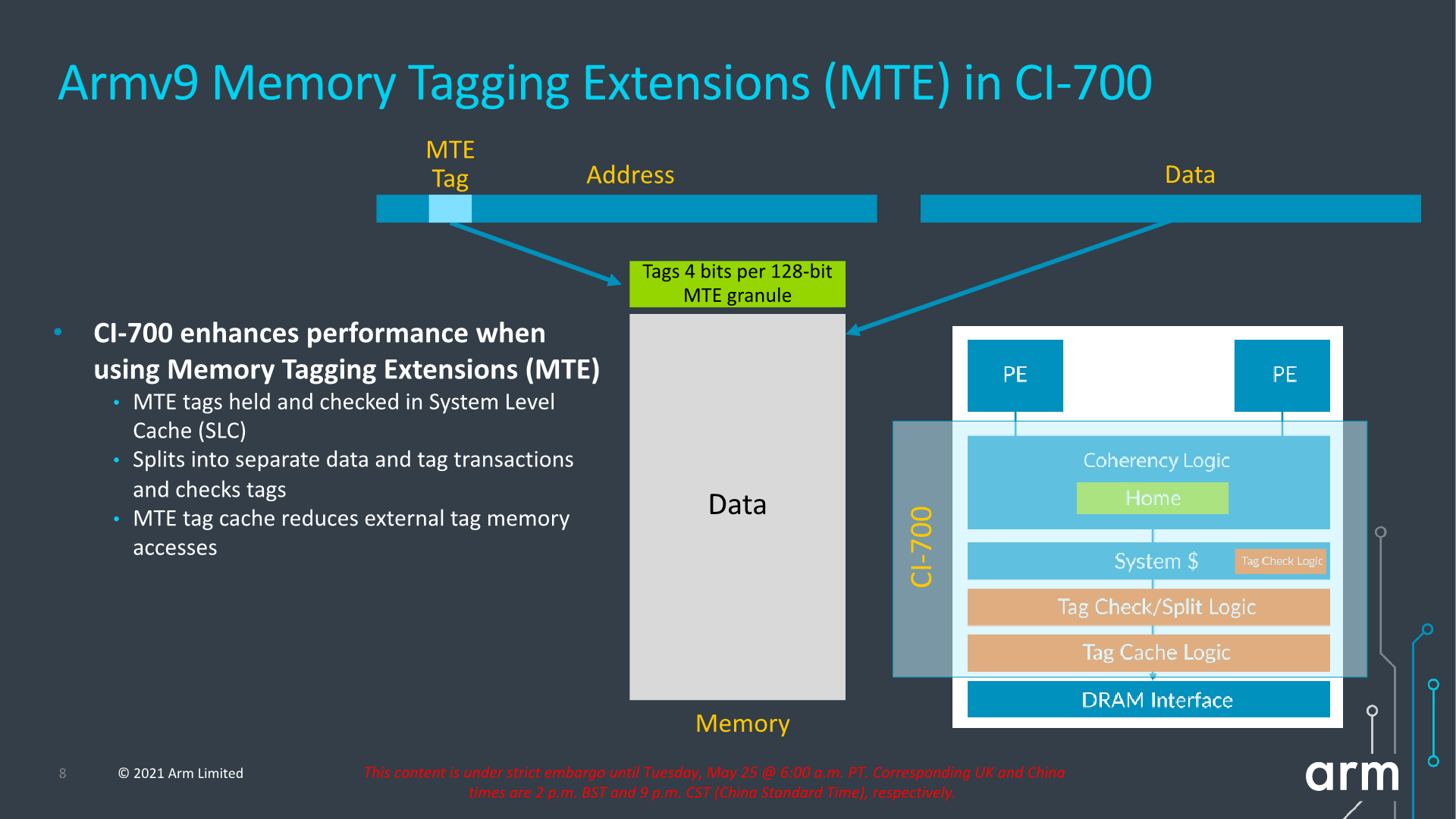
We see a reiteration of the support for MTE, allowing for this generation of IPs to support the feature across the new CPU IP, the DSU, and the new cache coherent interconnect.

Alongside the new CI-700 coherent interconnect, we’re also seeing a new NI-700 network-on-chip for non-coherent data transfers between a SoC’s various IP blocks. The big new improvements here is the introduction of packetization for data transfers, which leads to a reduction of wires and thus improves area efficiency of the NoC on the SoC.
Overall, the new system IP announced today is very interesting, but the one question that’s one has to ask oneself is exactly who these net interconnects are meant for. Over the last few years, we’ve seen essentially every major mobile vendor roll out their own in-house cache-coherent interconnect IP, such as Samsung’s SCI or MediaTek’s MCSI, and other times we don’t see vendors talk about their in-house interconnects at all (Qualcomm). Due to almost everybody having their own IP, I’m not sure what the likelihood would be that any of the big players would jump back to Arm’s own solutions – if somebody were to adopt it, it would rather be amongst the smaller name vendors and newcomers to the market. From a business and IP portfolio perspective, the new designs make a lot of sense and allows to have the building blocks to create a mostly Arm-only SoC, which is an important item to have on the menu for Arm’s more diverse customer base.








181 Comments
View All Comments
Thala - Tuesday, May 25, 2021 - link
You compare only peak performance. ARM has demonstrated that SVE2 can have big advantages over NEON, in particular for computational kernel, which does not parallelize well for NEON.WorBlux - Thursday, May 27, 2021 - link
>If they are sticking with in-order, I hoped the A510 could’ve done something more over four years.In order is hard. The A55 was pretty cool in allowing certain instruction dependencies to be issued together. The traditional way to get more IPC out of in-order is VLIW, but would require an ABI break or at least a special sort of compiler optimization and quasi-long-words that in the end wouldn't do any better than the A55/A510 on legacy and non-optimized code.
mode_13h - Tuesday, May 25, 2021 - link
x86 is indeed on the way out, but your analysis is too facile.SarahKerrigan - Tuesday, May 25, 2021 - link
Essentially agreed.yeeeeman - Tuesday, May 25, 2021 - link
x86 maybe dead if you don't understand how and why things stand like they do.First of all, Apple is in a very very special situation where they control everything. Hardware, software, product. Plus they use the best process there is at the moment. All of this, contributes to their results. Which are very good, but they stem from what I told you.
Now, a better picture of what ARM is actually capable of in ... real life is the snapdragon 8cx, which for all intents and purposes is still alive only because qualcomm has a ton of money and can throw it away for projects that don't really sell.
Apple is using just ARM ISA. If Apple has great performance and great efficiency, it doesn't mean automatically that ARM and the companies that work with them will also reach that point. The truth is, Apple has put a LOT of money and R&D and got the best talents there are to get where they are today. Their cores are not exactly suited for the plethora of android devices that range from 50 bucks to 2000+.
Now, regarding x86, if you compare amd's zen 3 with m1, you'll see that they are not that far off, in perf and in efficiency. And AMD is using 7nm, not 5nm! Also, nowdays, all the cpus are risc inside, so x86 cpus are very similar inside to arm cpus, with the addition of the extra decoding and micro ops.
x86 main weakness is also its greatest advantage. Backwards compatibility is very important and needs to stay. ARM cpus lose compatibility totally once in a while, which is not something that will work in the long run.
Also, don't forget that Intel hasn't introduced anything major since 2015! Ice Lake/Tigerlake are just a bump in execution units over skylake, which on its own brings 20% better IPC. But Intel has stayed still for so many years, that is why ARM has got the chance to close the gap.
SarahKerrigan - Tuesday, May 25, 2021 - link
What? SNC is not merely a bump in execution units from SKL at all. It's a new, wider, more aggressive uarch across the board. SNC is a larger change than SKL itself was, and not by a small margin.boredsysadmin - Tuesday, May 25, 2021 - link
@yeeeeman - "Also, nowdays, all the cpus are risc inside, so x86 cpus are very similar inside to arm cpus, with the addition of the extra decoding and micro ops."Excuse, where did you get this BS? Only Arm, Risk-V, MIPS, and PowerPC are using RISC. x86 from both Intel and AMD are very much still CISC. So, no they aren't very similar in any share and form.
Drumsticks - Tuesday, May 25, 2021 - link
All x86 CPUs crack CISC macro instructions into smaller RISC like operations. The actual execution of the CPU operates on these smaller micro ops. Beyond the initial decode/cracking stage, it's pretty much a RISC operation.They are CISC from an architectural perspective, but they've been RISC in execution for some time.
vvid - Tuesday, May 25, 2021 - link
>> All x86 CPUs crack CISC macro instructions into smaller RISC like operations.RISC-like is not RISC. It is like saying that a woman with pear-like figure shape is actually a pear.
x86 uops are pretty much corresponding to CISC ISA now.
>> but they've been RISC in execution for some time
RISC-like.
mode_13h - Wednesday, May 26, 2021 - link
> they've been RISC in execution for some time.And sadly, Internet Oversimplification Syndrome claims another victim.