Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
The Cortex-A710: More Performance with More Efficiency
While the Cortex-X2 goes for all-out performance while paying the power and area penalties, Arm's Cortex-A710 design goes for a more efficient approach.
First of all, the new product nomenclature now is self-evident in regards to what Arm will be doing going forward- they’re skipping the A79 designation and simply starting fresh with a new three-digit scheme with the A710. Not very important in the grand scheme of things but an interesting marketing tidbit.

The Cortex-A710, much like the X2, is an Armv9 core with all new features that come with the new architecture version. Unlike the X2, the A710 also supports EL0 AArch32 execution, and as mentioned in the intro, this was mostly a design choice demanded by customers in the Chinese market where the ecosystem is still slightly lagging behind in moving all applications over to AArch64.

In terms of front-end enhancements, we’re seeing the same branch prediction improvements as on the X2, with larger structures as well as better accuracy. Other structures such as the L1I TLB have also seen an increase from 32 entries to 48 entries. Other front-end structures such as the macro-OP cache remain the same at 1.5K entries (The X2 also remains at 3K entries).

A very interesting choice for the A710 mid-core is that Arm has reduced the macro-OP cache and dispatch stage throughputs from 6-wide to 5-wide. This was mainly a targeted power and efficiency optimization for this generation, as we’re seeing a more important divergence between the Cortex-A and Cortex-X cores in terms of their specializations and targeted use-cases for performance and power.
The dispatch stage also features the same optimizations as on the X2, removing 1 cycle from the pipeline towards an overall 10-cycle pipeline design.
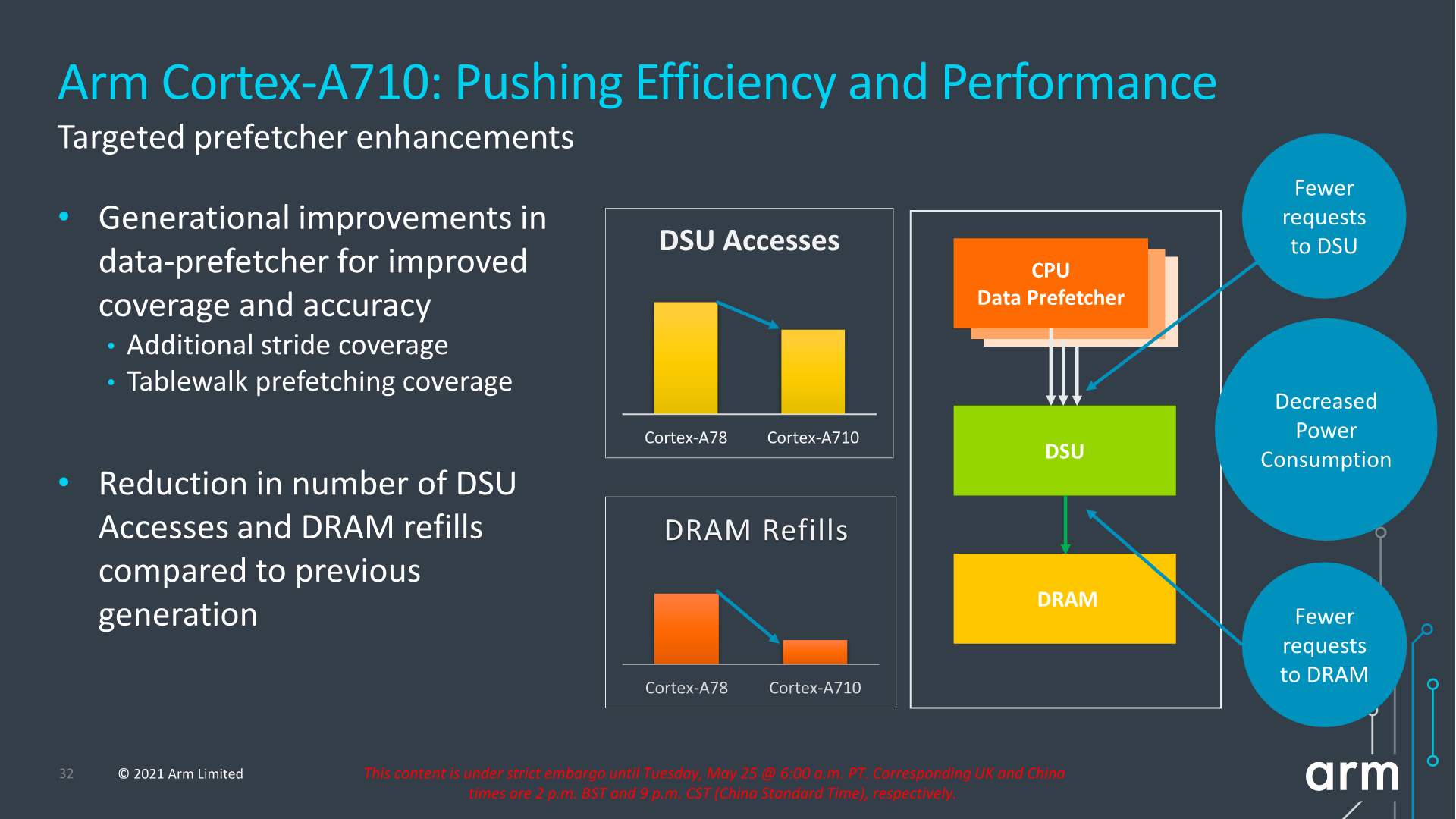
Arm also focuses on core improvements that affect the uncore parts of the system, which take place thanks to the new improvements in the prefetcher designs and how they interact with the new DSU-110 (which we’ll cover later). The new combination of core and DSU are able to reduce access from the core towards the L3 cache, as well as reducing the costly DRAM accesses thanks to the more efficiency prefetchers and larger L3 cache.
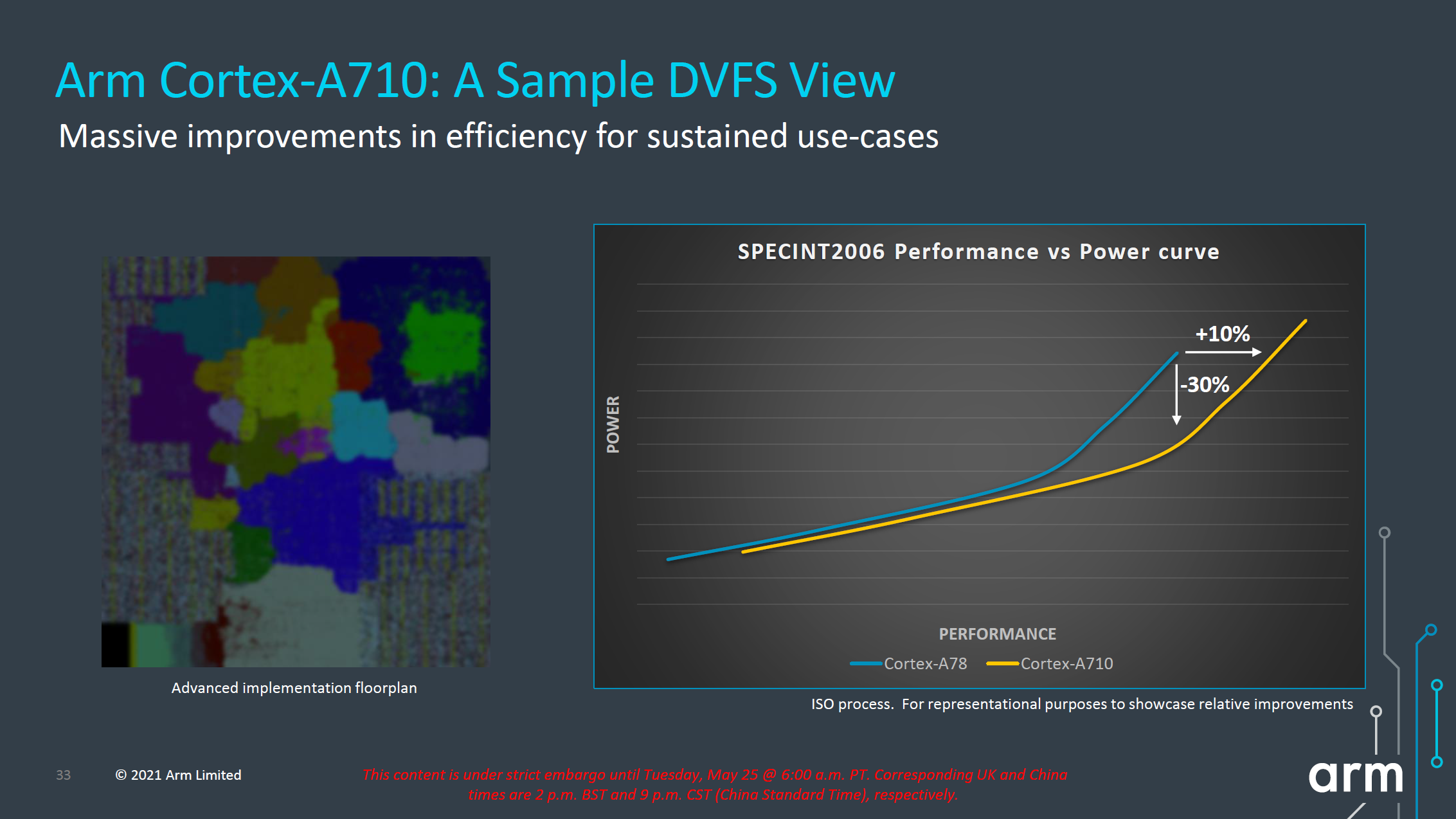
In terms of IPC, Arm advertises +10%, but again the issue with this figure here is that we’re comparing an 8MB L3 cache design to a 4MB L3 cache design. While this is a likely comparison for flagship SoCs next year, because the Cortex-A710 is also a core that would be used in mid-range or lower-end SoCs which might use much smaller L3 caches, it’s unlikely we’ll be seeing such IPC improvements in that sector unless the actual SoCs really do also improve their DSU sizes.
More important than the +10% improvement in performance is that, when backing off slightly in frequency, we can see that the power reduction can be rather large. According to Arm, at iso-performance the A710 consumes up to 30% less power than the Cortex-A78. This is something that would greatly help with sustained performance and power efficiency of more modestly clocked “middle” core implementations of the Cortex-A710.
In general, both the X2 and the A710’s performance and power figures are quite modest, making them the smallest generation-over-generation figures we’ve seen from Arm in quite a few years. Arm explains that due to this generation having made larger architectural changes with the move to Armv9, there has been an impact in regards to the usual efficiency and performance improvements that we’ve seen in prior generations.
Both the X2 and the A710 are also the fourth generation of this Austin microarchitecture family, so we’re hitting a wall of diminishing returns and maturity of the design. A few years ago we were under impression that the Austin family would only go on for three generations before handing things over to a new clean-sheet design from the Sophia team, but that original roadmap has been changed, and now we'll be seeing the new Sophia core with larger leaps in performance being disclosed next year.








181 Comments
View All Comments
Thala - Tuesday, May 25, 2021 - link
You compare only peak performance. ARM has demonstrated that SVE2 can have big advantages over NEON, in particular for computational kernel, which does not parallelize well for NEON.WorBlux - Thursday, May 27, 2021 - link
>If they are sticking with in-order, I hoped the A510 could’ve done something more over four years.In order is hard. The A55 was pretty cool in allowing certain instruction dependencies to be issued together. The traditional way to get more IPC out of in-order is VLIW, but would require an ABI break or at least a special sort of compiler optimization and quasi-long-words that in the end wouldn't do any better than the A55/A510 on legacy and non-optimized code.
mode_13h - Tuesday, May 25, 2021 - link
x86 is indeed on the way out, but your analysis is too facile.SarahKerrigan - Tuesday, May 25, 2021 - link
Essentially agreed.yeeeeman - Tuesday, May 25, 2021 - link
x86 maybe dead if you don't understand how and why things stand like they do.First of all, Apple is in a very very special situation where they control everything. Hardware, software, product. Plus they use the best process there is at the moment. All of this, contributes to their results. Which are very good, but they stem from what I told you.
Now, a better picture of what ARM is actually capable of in ... real life is the snapdragon 8cx, which for all intents and purposes is still alive only because qualcomm has a ton of money and can throw it away for projects that don't really sell.
Apple is using just ARM ISA. If Apple has great performance and great efficiency, it doesn't mean automatically that ARM and the companies that work with them will also reach that point. The truth is, Apple has put a LOT of money and R&D and got the best talents there are to get where they are today. Their cores are not exactly suited for the plethora of android devices that range from 50 bucks to 2000+.
Now, regarding x86, if you compare amd's zen 3 with m1, you'll see that they are not that far off, in perf and in efficiency. And AMD is using 7nm, not 5nm! Also, nowdays, all the cpus are risc inside, so x86 cpus are very similar inside to arm cpus, with the addition of the extra decoding and micro ops.
x86 main weakness is also its greatest advantage. Backwards compatibility is very important and needs to stay. ARM cpus lose compatibility totally once in a while, which is not something that will work in the long run.
Also, don't forget that Intel hasn't introduced anything major since 2015! Ice Lake/Tigerlake are just a bump in execution units over skylake, which on its own brings 20% better IPC. But Intel has stayed still for so many years, that is why ARM has got the chance to close the gap.
SarahKerrigan - Tuesday, May 25, 2021 - link
What? SNC is not merely a bump in execution units from SKL at all. It's a new, wider, more aggressive uarch across the board. SNC is a larger change than SKL itself was, and not by a small margin.boredsysadmin - Tuesday, May 25, 2021 - link
@yeeeeman - "Also, nowdays, all the cpus are risc inside, so x86 cpus are very similar inside to arm cpus, with the addition of the extra decoding and micro ops."Excuse, where did you get this BS? Only Arm, Risk-V, MIPS, and PowerPC are using RISC. x86 from both Intel and AMD are very much still CISC. So, no they aren't very similar in any share and form.
Drumsticks - Tuesday, May 25, 2021 - link
All x86 CPUs crack CISC macro instructions into smaller RISC like operations. The actual execution of the CPU operates on these smaller micro ops. Beyond the initial decode/cracking stage, it's pretty much a RISC operation.They are CISC from an architectural perspective, but they've been RISC in execution for some time.
vvid - Tuesday, May 25, 2021 - link
>> All x86 CPUs crack CISC macro instructions into smaller RISC like operations.RISC-like is not RISC. It is like saying that a woman with pear-like figure shape is actually a pear.
x86 uops are pretty much corresponding to CISC ISA now.
>> but they've been RISC in execution for some time
RISC-like.
mode_13h - Wednesday, May 26, 2021 - link
> they've been RISC in execution for some time.And sadly, Internet Oversimplification Syndrome claims another victim.