Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
A new CI-700 Coherent Interconnect & NI-700 NoC For SoCs
Finally, the last new announcement of the day is a new interconnect and network-on-chip generation. The last time Arm had announced a mobile/client interconnect was back in in 2015 with the CCI-550. The reason for the large gap between IPs, in Arm’s own words, is that ever since Arm’s introduction of the DSU in its CPU complexes, there really hasn’t been any need for a cache coherent interconnect in the market. While that’s eyebrow-raising from a GPU perspective, it makes perfect sense from a CPU perspective, as coherency between CPU cores was the primary driver for such interconnects until then.
With the advent of new more complex computing platforms, such as NPUs, accelerators, and hopeful more use of GPUs in cache-coherent fashions, Arm saw a need gap in its portfolio and decided to update its client-side interconnect IP.


The new CI-700 is a mobile and client optimised variant of Arm’s infrastructure CMN mesh network, implementing important new interoperability with the new IP announced today, such as the new DSU or CPU cores.
The new mesh interconnect scales up from 1 to 8 DSU clusters, and supports up to 8 memory controllers, and also introduces innovations such as a system level cache.
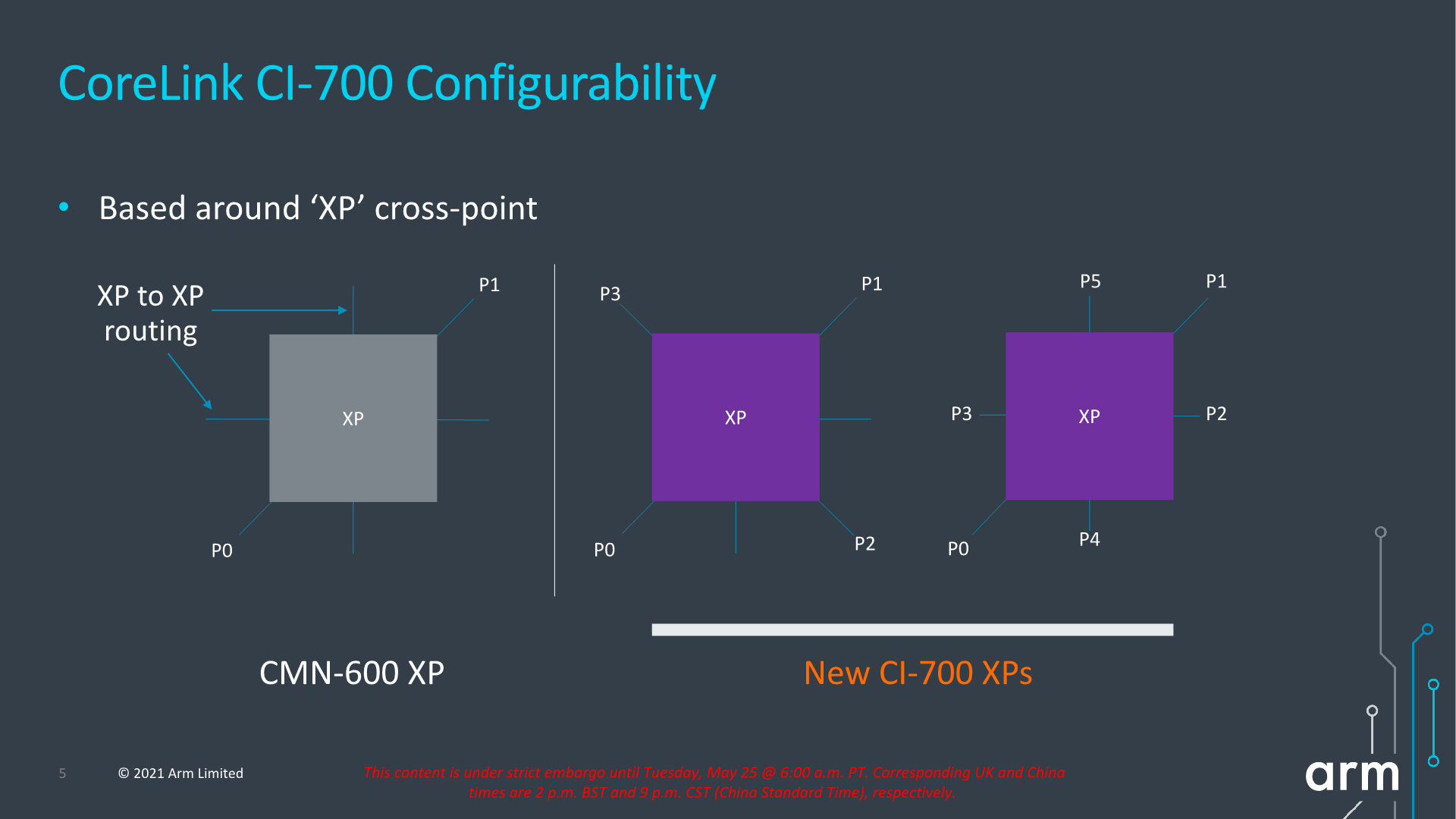

The mesh network topology and building blocks is very similar to what we’ve seen in the CMN infrastructure IP, in that “points” in the mesh are comprised of “cross-points” or “XP”. One differentiation that’s unique to the client mesh implementation is that XPs can have more attached connectivity ports, trading in routing connection paths. The new IP can also be configured as just a sole XP with no real mesh so to speak of, or essentially a 1x1 mesh configuration. This can grow up to a 4x3 mesh in the largest possible configuration.
The mesh supports from 1 to 8 SLC slices, with up to 4MB per slice for a total of 32MB, and snoop filter SRAM with coverage of up to 8MB address space per slice. It’s noted that generally Arm recommends 1.5-2x of coverage of the underlying private cache hierarchies of the mesh clients.
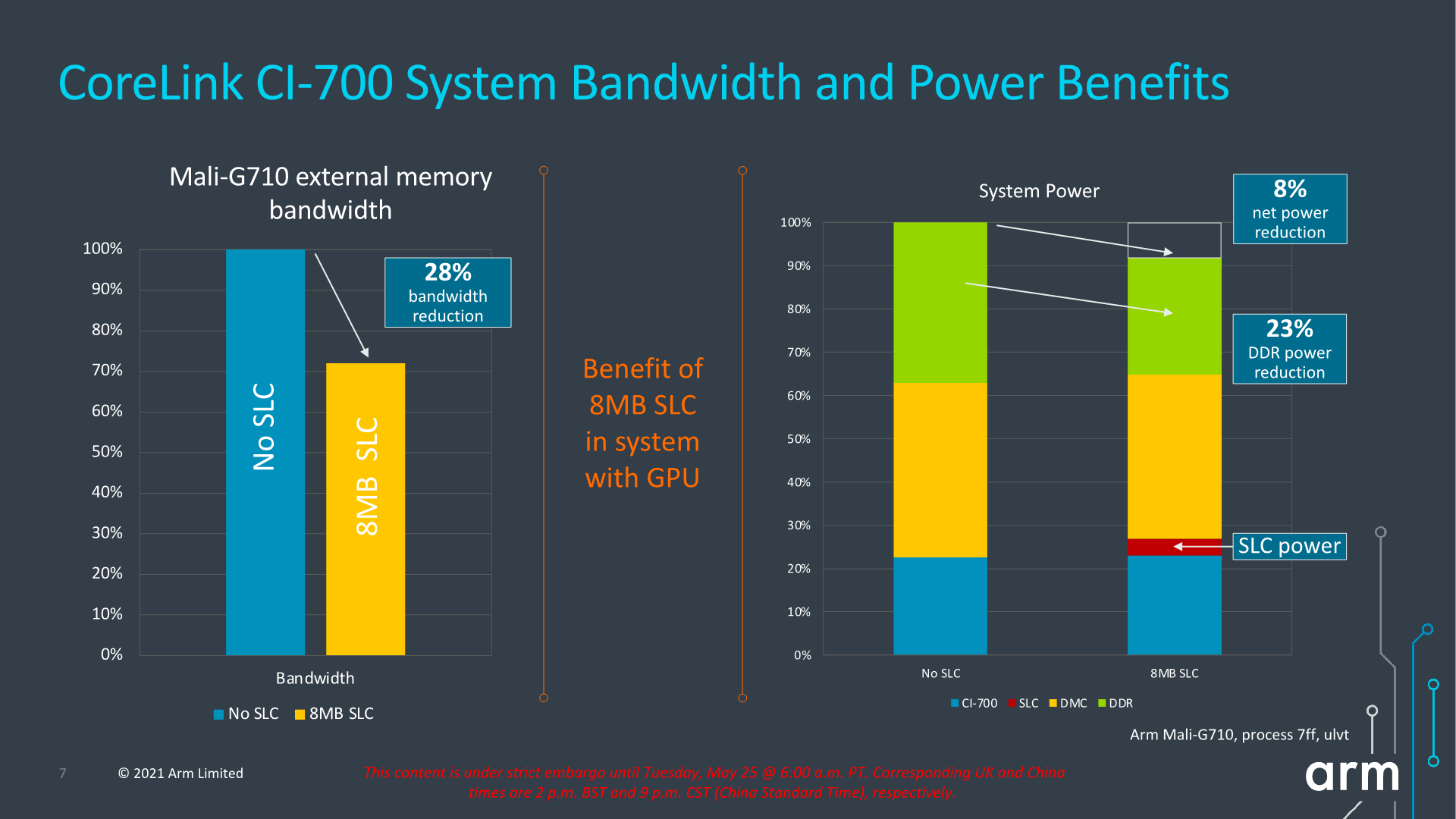
The SLC can server as both a bandwidth amplifier as well as reducing external memory/DRAM transactions, reducing system power reduction.
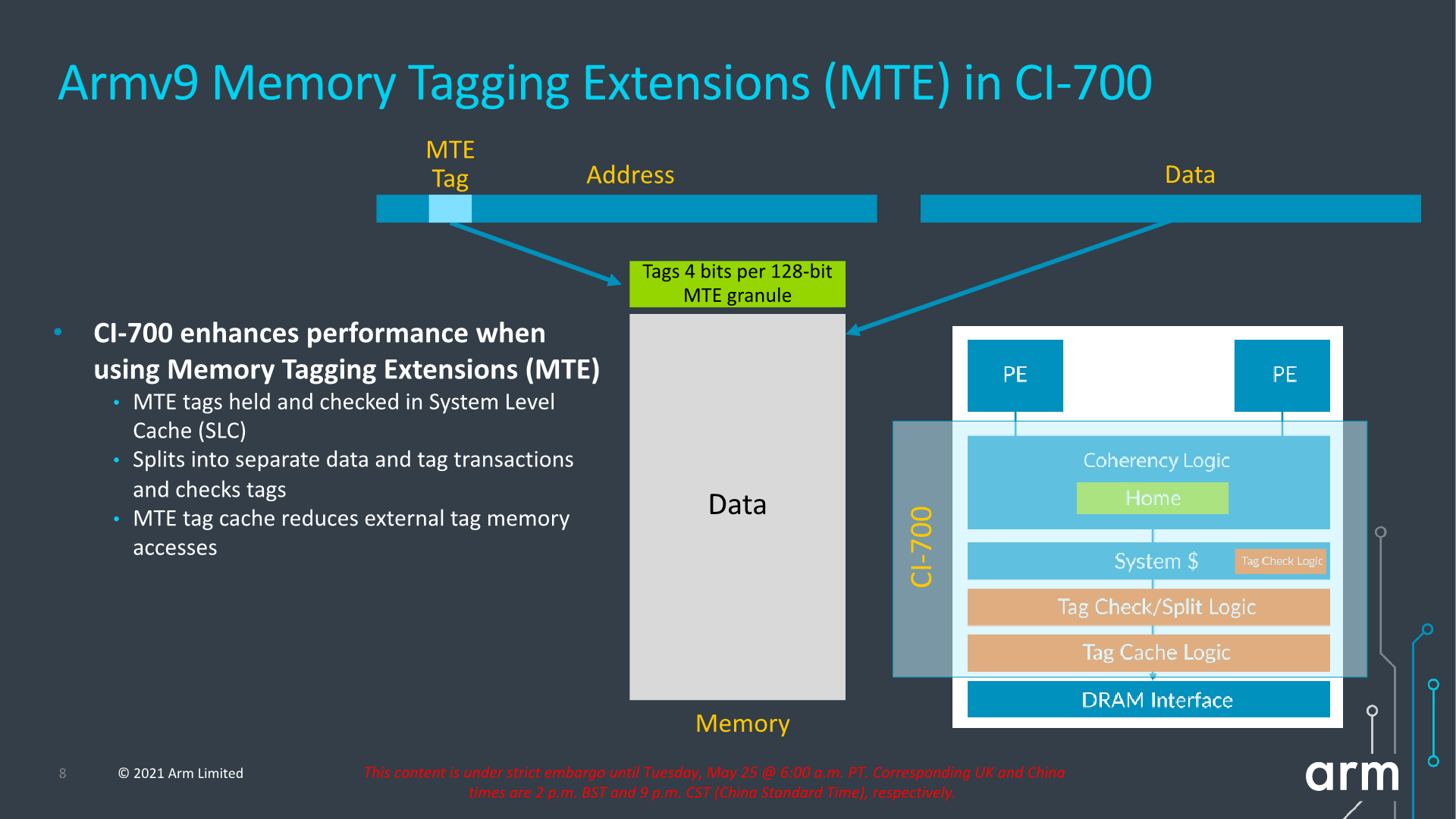
We see a reiteration of the support for MTE, allowing for this generation of IPs to support the feature across the new CPU IP, the DSU, and the new cache coherent interconnect.

Alongside the new CI-700 coherent interconnect, we’re also seeing a new NI-700 network-on-chip for non-coherent data transfers between a SoC’s various IP blocks. The big new improvements here is the introduction of packetization for data transfers, which leads to a reduction of wires and thus improves area efficiency of the NoC on the SoC.
Overall, the new system IP announced today is very interesting, but the one question that’s one has to ask oneself is exactly who these net interconnects are meant for. Over the last few years, we’ve seen essentially every major mobile vendor roll out their own in-house cache-coherent interconnect IP, such as Samsung’s SCI or MediaTek’s MCSI, and other times we don’t see vendors talk about their in-house interconnects at all (Qualcomm). Due to almost everybody having their own IP, I’m not sure what the likelihood would be that any of the big players would jump back to Arm’s own solutions – if somebody were to adopt it, it would rather be amongst the smaller name vendors and newcomers to the market. From a business and IP portfolio perspective, the new designs make a lot of sense and allows to have the building blocks to create a mostly Arm-only SoC, which is an important item to have on the menu for Arm’s more diverse customer base.








181 Comments
View All Comments
RSAUser - Wednesday, May 26, 2021 - link
Basically interesting for cases when you don't want to add an A73, e.g. It's pretty big news in the watch space where it's been the same 4/5yo architecture for a very long time.mode_13h - Thursday, May 27, 2021 - link
> It's pretty big news in the watch spaceI'm actually surprised people are even using A55s in smartwatches, or that ARM is targeting the A510 at them. I'd figured the most they could get away with would be the A35.
I guess pairing a couple A55s with some A35s might be a way to get responsiveness *and* battery life. Is that something people do?
mode_13h - Wednesday, May 26, 2021 - link
It'd be interesting to see how efficient the A73 would be, if you dropped its clock to match the A510's performance.AntonErtl - Thursday, May 27, 2021 - link
Yes. ARM gives some flowery wordings for the lower performance of the A510 compared to A73 (and Andrei reworded in the way ARM wants us to think: "very similar IPC and frequency capabilities whilst consuming a lot less power"; looking at the numbers given by ARM, the A510 has >20% less performance than the A73, at 35% less power. The DVFS stuff I have seen makes me expect that the A73 has the same or lower power at the same performance, if you lower the clock by 20% (or whatever the slowness factor of the A510 is).Andrei already showed us in his Exynos 9820 review that the A75 has better Perf and Perf/W for nearly all of the performance range of the A55. So I find it surprising that ARM went for another in-order design for the little core of ARMv9, instead of something like an ARMv9-enabled A75. For me it will certainly be an interesting microarchitecture to study, but I guess it will take some time until it appears in some Odroid or Raspi board.
mode_13h - Saturday, May 29, 2021 - link
> the A75 has better Perf and Perf/W for nearly all of the performance range of the A55.> So I find it surprising that ARM went for another in-order design for the little core of ARMv9
You're forgetting about PPA, though. The A510 is probably a lot smaller (ISO-process) than the A75.
> I guess it will take some time until it appears in some Odroid or Raspi board.
Look for A76-enabled SBCs late this year or early next. Rockchip's RK3588 will have 4x A76.
Raspberry Pi will probably be stuck on A72 or A73 for a couple more generations, since they plan to stay on 28 nm, for a while. Meanwhile, the Allwinner SoC in ODROID's N2 is made on 12 nm.
AntonErtl - Sunday, May 30, 2021 - link
Looking at the Exynos 9820 die shot, te A55 is ~3.4 times smaller than the A75, but it also has ~3.4 times lower top performance and a similar factor at the lowest common perf/W point, and from the looks of the line, in between. I doubt that the A510 is better in perf/area. But maybe it's the difference that ARM is claiming between the workloads Andrei used for evaluating performance (SPEC CPU2006) and what the A55 and A510 are doing in practice; if they mainly wait for peripherals, I can believe that their performance does not matter much.Thanks for the info on SBCs to be expected.
Wereweeb - Wednesday, May 26, 2021 - link
I'll ignore all the warfare in the comments, and just say this: imagine a 16-'core' A510 SoC. Sorry.mode_13h - Wednesday, May 26, 2021 - link
So, if you built a HPC CPU with A510 @ one core per complex, 2x 128-bit SVE2, and max L2 cache, how would area-efficiency (PPA) and power-efficiency (PPW) compare with a V1-based chip on the same node?Let's assume the workload has enough concurrency to scale up to all the A510 cores, and that there's enough ILP that the A510's lack of OoO isn't a significant impediment.
Shakal - Thursday, May 27, 2021 - link
Pardon my ignorance but what exactly is an "Alternate path predictor"? They mention that for the X2 core but I've not found any reference to what it is. I've heard of path based predictors but how does the alternate come into play?ballsystemlord - Friday, May 28, 2021 - link
Spelling and grammar errors (there are lots!):I read through everything but the conclusion.
"From a microarchitectural standpoint this is interesting as it means Arm will have been able to kick out some cruft in the design."
"has", not "have" and subtract "will":
"From a microarchitectural standpoint this is interesting as it means Arm has been able to kick out some cruft in the design."
"Even though it's a in-order core,..."
"an" not "a":
"Even though it's an in-order core,..."
"...and since then we haven't had seen any updates to Arm's little cores, to the point of it being seen as large weakness of last few generations of mobile SoCs."
You need an "a" and subtract "had":
"...and since then we haven't seen any updates to Arm's little cores, to the point of it being seen as a large weakness of last few generations of mobile SoCs."
"The new design if a clean-sheet microarchitecture from Arm's Cambridge team which the engineers had been working on the past 4 years, ..."
"is" not "if":
"The new design is a clean-sheet microarchitecture from Arm's Cambridge team which the engineers had been working on the past 4 years, ..."
"... the performance impact and deficit is said to only a few percent versus having a pipeline dedicated for each core."
Add a "be":
"... the performance impact and deficit is said to be only a few percent versus having a pipeline dedicated for each core."
"The dual-ring structure is used to reduce the latencies and hops between ring-stops and in shorten the paths between the cache slices and cores."
"to", not "in":
"The dual-ring structure is used to reduce the latencies and hops between ring-stops and to shorten the paths between the cache slices and cores."
"Architecturally, one important change to the capabilities of the DSU-110 is support for MTE tags, a upcoming security and debugging feature promising to greatly help with memory safety issues."
"an" not "a":
"Architecturally, one important change to the capabilities of the DSU-110 is support for MTE tags, an upcoming security and debugging feature promising to greatly help with memory safety issues."
"The SLC can server as both a bandwidth amplifier as well as reducing external memory/DRAM transactions, reducing system power reduction."
"serve", not "server" and "consumption", not "reduction":
"The SLC can serve as both a bandwidth amplifier as well as reducing external memory/DRAM transactions, reducing system power consumption."
"Overall, the new system IP announced today is very interesting, but the one question that's one has to ask oneself is exactly who these net interconnects are meant for."
Excess "'s". Refactoring makes more sense.
"Overall, the new system IP announced today is very interesting, but we have to ask who exactly these net interconnects are meant for."