Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
The Cortex-A710: More Performance with More Efficiency
While the Cortex-X2 goes for all-out performance while paying the power and area penalties, Arm's Cortex-A710 design goes for a more efficient approach.
First of all, the new product nomenclature now is self-evident in regards to what Arm will be doing going forward- they’re skipping the A79 designation and simply starting fresh with a new three-digit scheme with the A710. Not very important in the grand scheme of things but an interesting marketing tidbit.

The Cortex-A710, much like the X2, is an Armv9 core with all new features that come with the new architecture version. Unlike the X2, the A710 also supports EL0 AArch32 execution, and as mentioned in the intro, this was mostly a design choice demanded by customers in the Chinese market where the ecosystem is still slightly lagging behind in moving all applications over to AArch64.

In terms of front-end enhancements, we’re seeing the same branch prediction improvements as on the X2, with larger structures as well as better accuracy. Other structures such as the L1I TLB have also seen an increase from 32 entries to 48 entries. Other front-end structures such as the macro-OP cache remain the same at 1.5K entries (The X2 also remains at 3K entries).

A very interesting choice for the A710 mid-core is that Arm has reduced the macro-OP cache and dispatch stage throughputs from 6-wide to 5-wide. This was mainly a targeted power and efficiency optimization for this generation, as we’re seeing a more important divergence between the Cortex-A and Cortex-X cores in terms of their specializations and targeted use-cases for performance and power.
The dispatch stage also features the same optimizations as on the X2, removing 1 cycle from the pipeline towards an overall 10-cycle pipeline design.
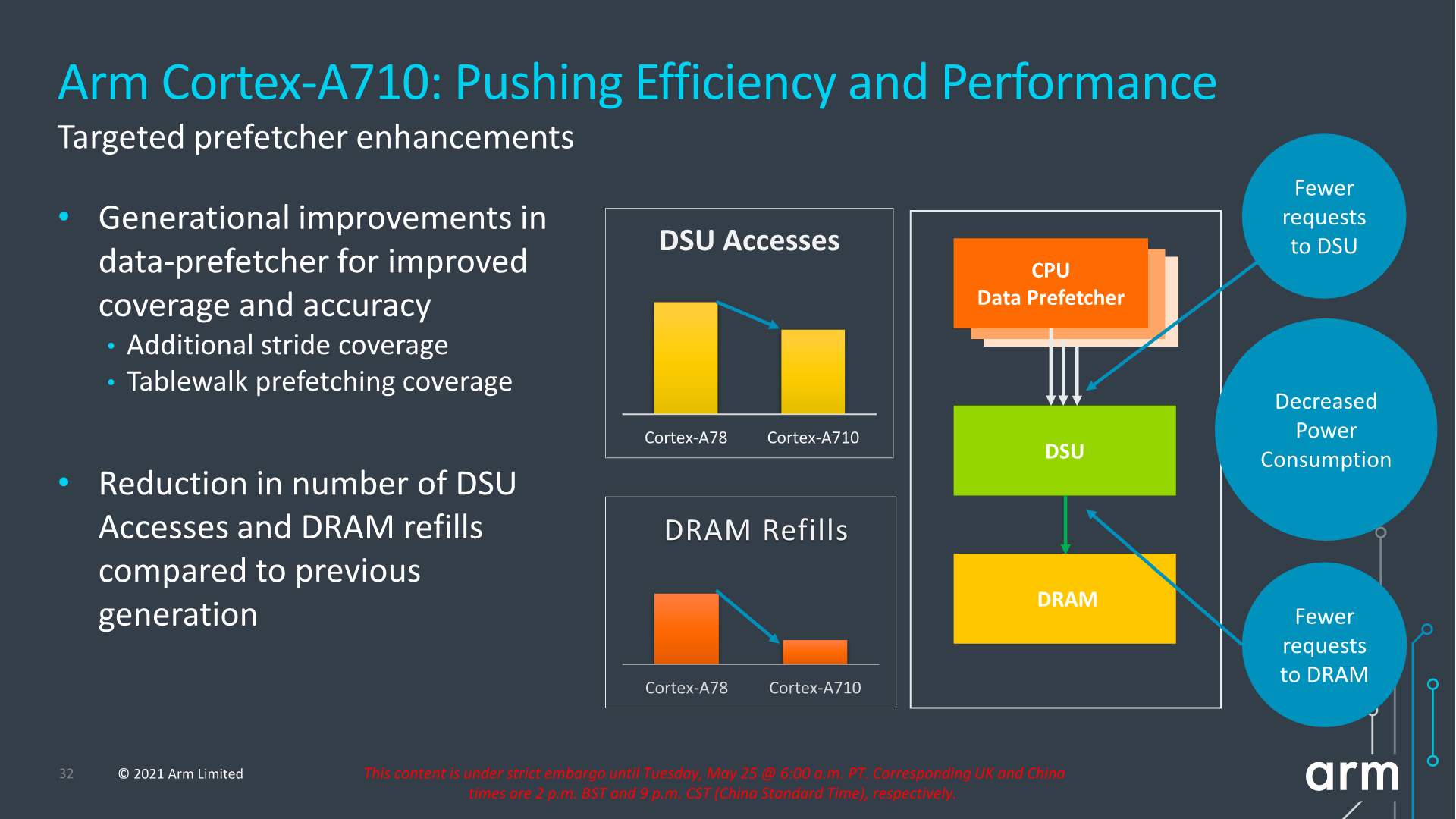
Arm also focuses on core improvements that affect the uncore parts of the system, which take place thanks to the new improvements in the prefetcher designs and how they interact with the new DSU-110 (which we’ll cover later). The new combination of core and DSU are able to reduce access from the core towards the L3 cache, as well as reducing the costly DRAM accesses thanks to the more efficiency prefetchers and larger L3 cache.
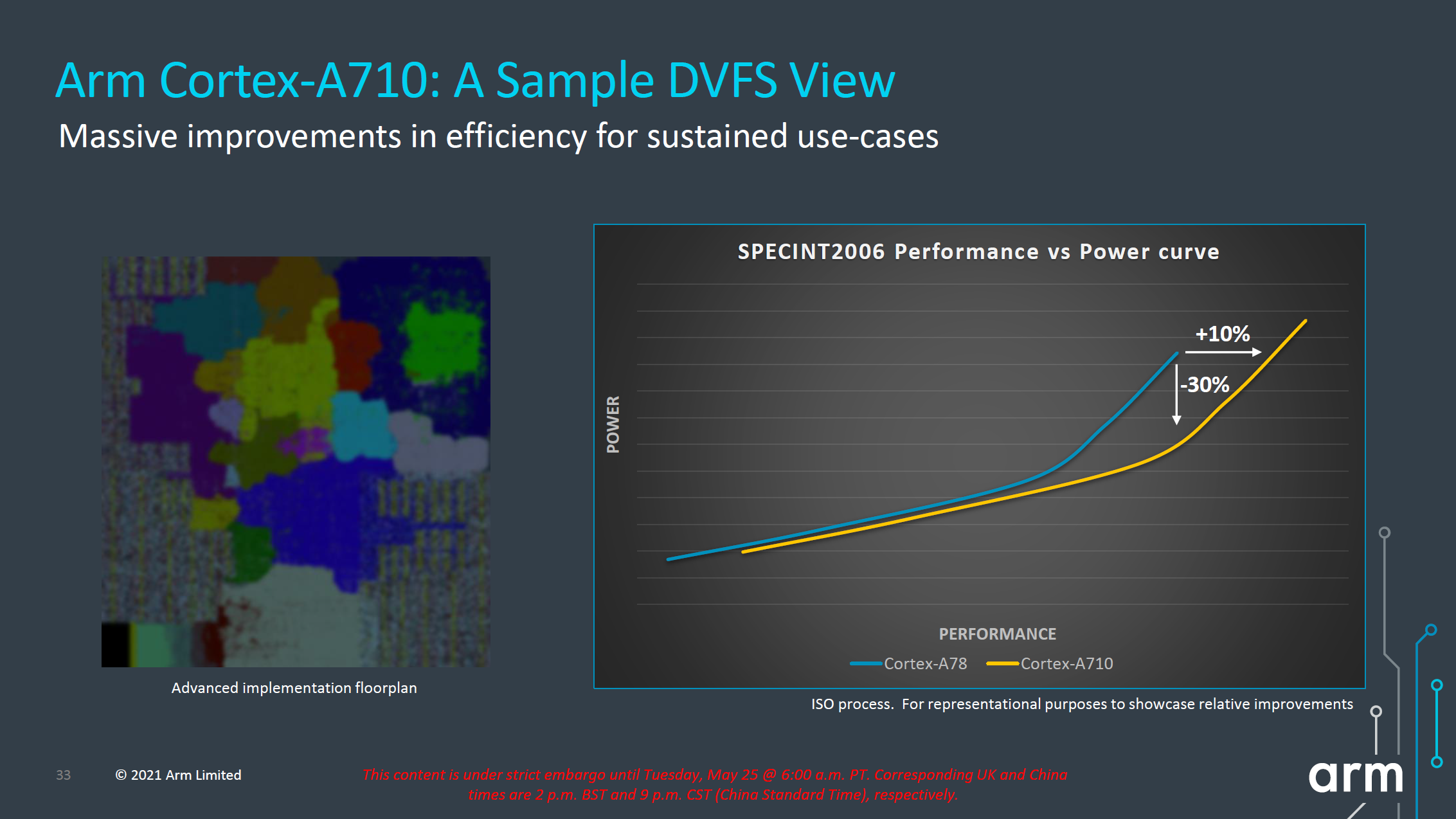
In terms of IPC, Arm advertises +10%, but again the issue with this figure here is that we’re comparing an 8MB L3 cache design to a 4MB L3 cache design. While this is a likely comparison for flagship SoCs next year, because the Cortex-A710 is also a core that would be used in mid-range or lower-end SoCs which might use much smaller L3 caches, it’s unlikely we’ll be seeing such IPC improvements in that sector unless the actual SoCs really do also improve their DSU sizes.
More important than the +10% improvement in performance is that, when backing off slightly in frequency, we can see that the power reduction can be rather large. According to Arm, at iso-performance the A710 consumes up to 30% less power than the Cortex-A78. This is something that would greatly help with sustained performance and power efficiency of more modestly clocked “middle” core implementations of the Cortex-A710.
In general, both the X2 and the A710’s performance and power figures are quite modest, making them the smallest generation-over-generation figures we’ve seen from Arm in quite a few years. Arm explains that due to this generation having made larger architectural changes with the move to Armv9, there has been an impact in regards to the usual efficiency and performance improvements that we’ve seen in prior generations.
Both the X2 and the A710 are also the fourth generation of this Austin microarchitecture family, so we’re hitting a wall of diminishing returns and maturity of the design. A few years ago we were under impression that the Austin family would only go on for three generations before handing things over to a new clean-sheet design from the Sophia team, but that original roadmap has been changed, and now we'll be seeing the new Sophia core with larger leaps in performance being disclosed next year.








181 Comments
View All Comments
RSAUser - Wednesday, May 26, 2021 - link
Basically interesting for cases when you don't want to add an A73, e.g. It's pretty big news in the watch space where it's been the same 4/5yo architecture for a very long time.mode_13h - Thursday, May 27, 2021 - link
> It's pretty big news in the watch spaceI'm actually surprised people are even using A55s in smartwatches, or that ARM is targeting the A510 at them. I'd figured the most they could get away with would be the A35.
I guess pairing a couple A55s with some A35s might be a way to get responsiveness *and* battery life. Is that something people do?
mode_13h - Wednesday, May 26, 2021 - link
It'd be interesting to see how efficient the A73 would be, if you dropped its clock to match the A510's performance.AntonErtl - Thursday, May 27, 2021 - link
Yes. ARM gives some flowery wordings for the lower performance of the A510 compared to A73 (and Andrei reworded in the way ARM wants us to think: "very similar IPC and frequency capabilities whilst consuming a lot less power"; looking at the numbers given by ARM, the A510 has >20% less performance than the A73, at 35% less power. The DVFS stuff I have seen makes me expect that the A73 has the same or lower power at the same performance, if you lower the clock by 20% (or whatever the slowness factor of the A510 is).Andrei already showed us in his Exynos 9820 review that the A75 has better Perf and Perf/W for nearly all of the performance range of the A55. So I find it surprising that ARM went for another in-order design for the little core of ARMv9, instead of something like an ARMv9-enabled A75. For me it will certainly be an interesting microarchitecture to study, but I guess it will take some time until it appears in some Odroid or Raspi board.
mode_13h - Saturday, May 29, 2021 - link
> the A75 has better Perf and Perf/W for nearly all of the performance range of the A55.> So I find it surprising that ARM went for another in-order design for the little core of ARMv9
You're forgetting about PPA, though. The A510 is probably a lot smaller (ISO-process) than the A75.
> I guess it will take some time until it appears in some Odroid or Raspi board.
Look for A76-enabled SBCs late this year or early next. Rockchip's RK3588 will have 4x A76.
Raspberry Pi will probably be stuck on A72 or A73 for a couple more generations, since they plan to stay on 28 nm, for a while. Meanwhile, the Allwinner SoC in ODROID's N2 is made on 12 nm.
AntonErtl - Sunday, May 30, 2021 - link
Looking at the Exynos 9820 die shot, te A55 is ~3.4 times smaller than the A75, but it also has ~3.4 times lower top performance and a similar factor at the lowest common perf/W point, and from the looks of the line, in between. I doubt that the A510 is better in perf/area. But maybe it's the difference that ARM is claiming between the workloads Andrei used for evaluating performance (SPEC CPU2006) and what the A55 and A510 are doing in practice; if they mainly wait for peripherals, I can believe that their performance does not matter much.Thanks for the info on SBCs to be expected.
Wereweeb - Wednesday, May 26, 2021 - link
I'll ignore all the warfare in the comments, and just say this: imagine a 16-'core' A510 SoC. Sorry.mode_13h - Wednesday, May 26, 2021 - link
So, if you built a HPC CPU with A510 @ one core per complex, 2x 128-bit SVE2, and max L2 cache, how would area-efficiency (PPA) and power-efficiency (PPW) compare with a V1-based chip on the same node?Let's assume the workload has enough concurrency to scale up to all the A510 cores, and that there's enough ILP that the A510's lack of OoO isn't a significant impediment.
Shakal - Thursday, May 27, 2021 - link
Pardon my ignorance but what exactly is an "Alternate path predictor"? They mention that for the X2 core but I've not found any reference to what it is. I've heard of path based predictors but how does the alternate come into play?ballsystemlord - Friday, May 28, 2021 - link
Spelling and grammar errors (there are lots!):I read through everything but the conclusion.
"From a microarchitectural standpoint this is interesting as it means Arm will have been able to kick out some cruft in the design."
"has", not "have" and subtract "will":
"From a microarchitectural standpoint this is interesting as it means Arm has been able to kick out some cruft in the design."
"Even though it's a in-order core,..."
"an" not "a":
"Even though it's an in-order core,..."
"...and since then we haven't had seen any updates to Arm's little cores, to the point of it being seen as large weakness of last few generations of mobile SoCs."
You need an "a" and subtract "had":
"...and since then we haven't seen any updates to Arm's little cores, to the point of it being seen as a large weakness of last few generations of mobile SoCs."
"The new design if a clean-sheet microarchitecture from Arm's Cambridge team which the engineers had been working on the past 4 years, ..."
"is" not "if":
"The new design is a clean-sheet microarchitecture from Arm's Cambridge team which the engineers had been working on the past 4 years, ..."
"... the performance impact and deficit is said to only a few percent versus having a pipeline dedicated for each core."
Add a "be":
"... the performance impact and deficit is said to be only a few percent versus having a pipeline dedicated for each core."
"The dual-ring structure is used to reduce the latencies and hops between ring-stops and in shorten the paths between the cache slices and cores."
"to", not "in":
"The dual-ring structure is used to reduce the latencies and hops between ring-stops and to shorten the paths between the cache slices and cores."
"Architecturally, one important change to the capabilities of the DSU-110 is support for MTE tags, a upcoming security and debugging feature promising to greatly help with memory safety issues."
"an" not "a":
"Architecturally, one important change to the capabilities of the DSU-110 is support for MTE tags, an upcoming security and debugging feature promising to greatly help with memory safety issues."
"The SLC can server as both a bandwidth amplifier as well as reducing external memory/DRAM transactions, reducing system power reduction."
"serve", not "server" and "consumption", not "reduction":
"The SLC can serve as both a bandwidth amplifier as well as reducing external memory/DRAM transactions, reducing system power consumption."
"Overall, the new system IP announced today is very interesting, but the one question that's one has to ask oneself is exactly who these net interconnects are meant for."
Excess "'s". Refactoring makes more sense.
"Overall, the new system IP announced today is very interesting, but we have to ask who exactly these net interconnects are meant for."