Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
A new CI-700 Coherent Interconnect & NI-700 NoC For SoCs
Finally, the last new announcement of the day is a new interconnect and network-on-chip generation. The last time Arm had announced a mobile/client interconnect was back in in 2015 with the CCI-550. The reason for the large gap between IPs, in Arm’s own words, is that ever since Arm’s introduction of the DSU in its CPU complexes, there really hasn’t been any need for a cache coherent interconnect in the market. While that’s eyebrow-raising from a GPU perspective, it makes perfect sense from a CPU perspective, as coherency between CPU cores was the primary driver for such interconnects until then.
With the advent of new more complex computing platforms, such as NPUs, accelerators, and hopeful more use of GPUs in cache-coherent fashions, Arm saw a need gap in its portfolio and decided to update its client-side interconnect IP.


The new CI-700 is a mobile and client optimised variant of Arm’s infrastructure CMN mesh network, implementing important new interoperability with the new IP announced today, such as the new DSU or CPU cores.
The new mesh interconnect scales up from 1 to 8 DSU clusters, and supports up to 8 memory controllers, and also introduces innovations such as a system level cache.
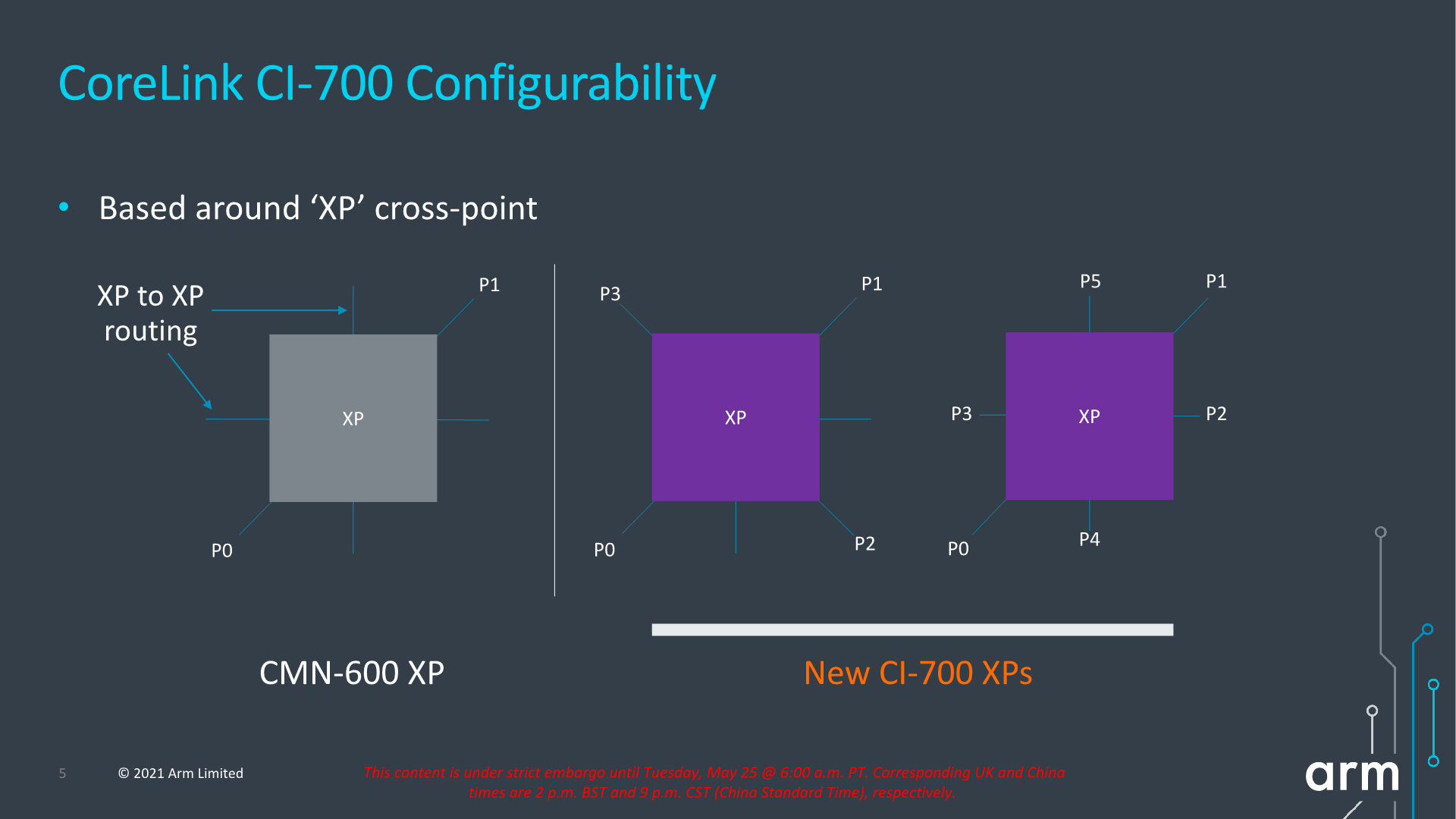

The mesh network topology and building blocks is very similar to what we’ve seen in the CMN infrastructure IP, in that “points” in the mesh are comprised of “cross-points” or “XP”. One differentiation that’s unique to the client mesh implementation is that XPs can have more attached connectivity ports, trading in routing connection paths. The new IP can also be configured as just a sole XP with no real mesh so to speak of, or essentially a 1x1 mesh configuration. This can grow up to a 4x3 mesh in the largest possible configuration.
The mesh supports from 1 to 8 SLC slices, with up to 4MB per slice for a total of 32MB, and snoop filter SRAM with coverage of up to 8MB address space per slice. It’s noted that generally Arm recommends 1.5-2x of coverage of the underlying private cache hierarchies of the mesh clients.
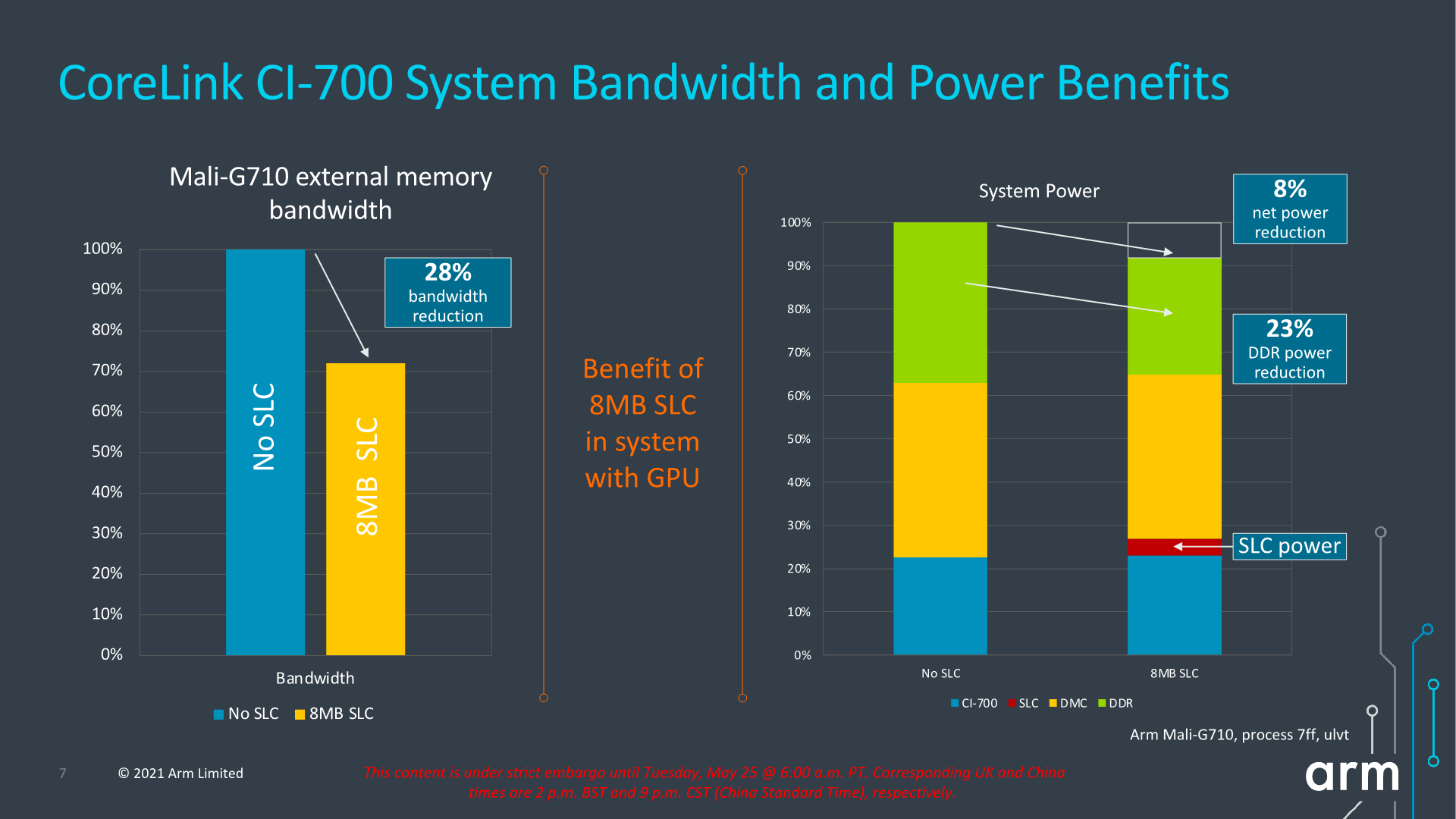
The SLC can server as both a bandwidth amplifier as well as reducing external memory/DRAM transactions, reducing system power reduction.
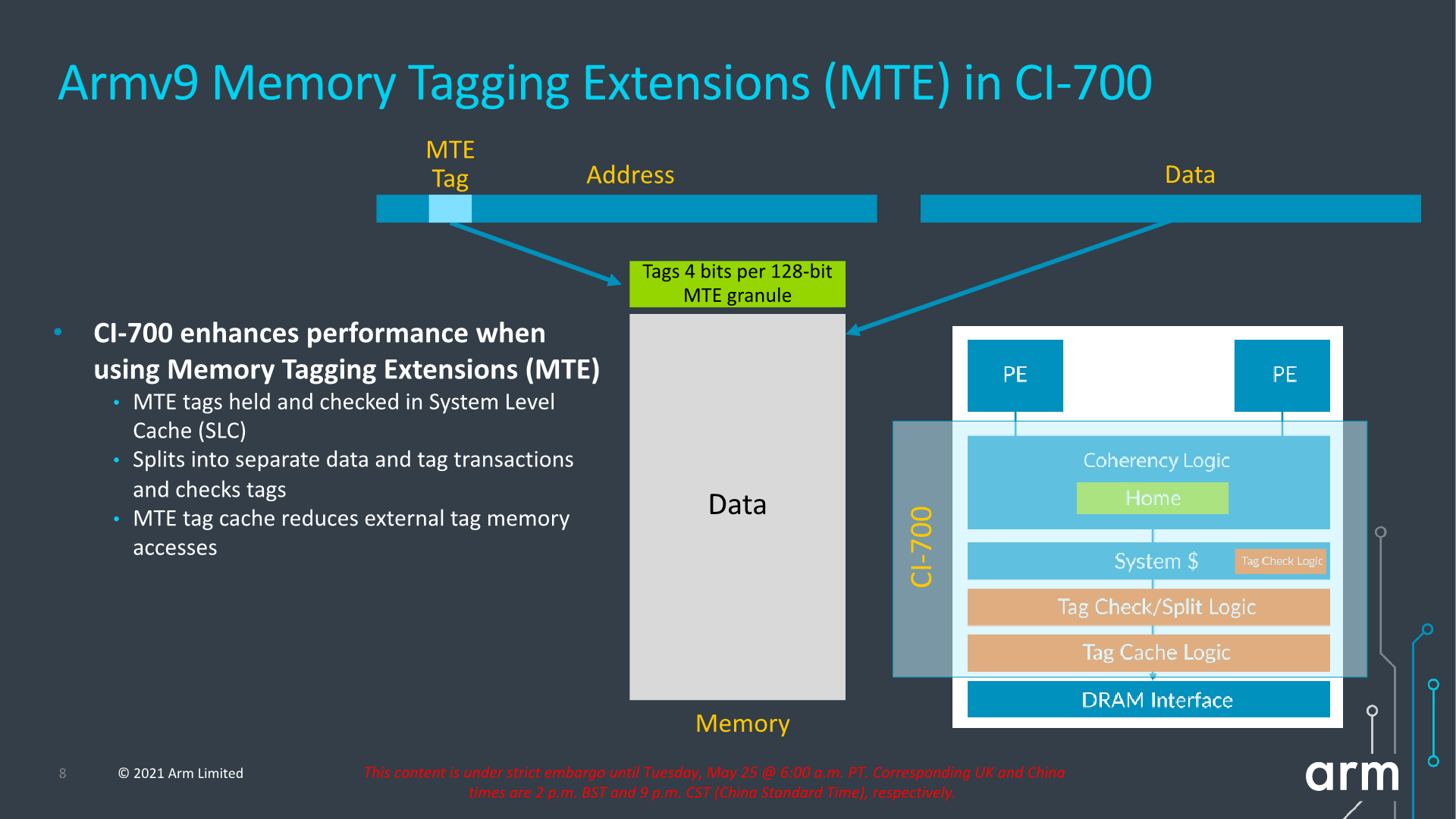
We see a reiteration of the support for MTE, allowing for this generation of IPs to support the feature across the new CPU IP, the DSU, and the new cache coherent interconnect.

Alongside the new CI-700 coherent interconnect, we’re also seeing a new NI-700 network-on-chip for non-coherent data transfers between a SoC’s various IP blocks. The big new improvements here is the introduction of packetization for data transfers, which leads to a reduction of wires and thus improves area efficiency of the NoC on the SoC.
Overall, the new system IP announced today is very interesting, but the one question that’s one has to ask oneself is exactly who these net interconnects are meant for. Over the last few years, we’ve seen essentially every major mobile vendor roll out their own in-house cache-coherent interconnect IP, such as Samsung’s SCI or MediaTek’s MCSI, and other times we don’t see vendors talk about their in-house interconnects at all (Qualcomm). Due to almost everybody having their own IP, I’m not sure what the likelihood would be that any of the big players would jump back to Arm’s own solutions – if somebody were to adopt it, it would rather be amongst the smaller name vendors and newcomers to the market. From a business and IP portfolio perspective, the new designs make a lot of sense and allows to have the building blocks to create a mostly Arm-only SoC, which is an important item to have on the menu for Arm’s more diverse customer base.








181 Comments
View All Comments
Silver5urfer - Tuesday, May 25, 2021 - link
Forgot that 32bit only thing. Apple does it everyone follows lol, on Phones the apps may be very limited for 32bit I do not know how many but some useful software might still be not updated but it might work, there is an app called DiskUsage that makes the WinDirStat type look and it's blazing fast plus works with root too. unfortunately that might be not working in the latest garbage Android 12 since it won't have storage access with SAF and Scoped disaster. There could be others..Thankfully it's not Windows which has a ton of applications on 32Bit. So pretty much some of the phones are getting outdated with this 64Bit only bs change, but since it's anyways planned obsolescence it won't matter by the time 64Bit only CPUs come like this phones which support 32bit would be dead, barring those amazing phones which have custom rom with removable batteries, they should be used for nice souvenirs if there's a DAC then like a DAP.
GeoffreyA - Thursday, May 27, 2021 - link
"Apple does it everyone follows"Popular opinion (more so when led by Apple) is like a wildfire, sweeping everything in its path.
mode_13h - Wednesday, May 26, 2021 - link
Blame consumers. Serviceable devices are more bulky and add some cost. In particular, the modular phone concept has been pursued a couple times, but never got traction.I don't like disposable hardware, but that's a sad reality of phones, tablets, and ultra-portables. I wanted to do the next best thing and use a phone with open software, but MeeGo and Firefox Phone both failed and none of the current Linux-based phone projects seem to be gaining much traction.
FWIW, my current phone does have a replaceable battery, which I had to do after the original one started swelling. It's not *easily* replaceable, but you can still do it or pay someone a little money to do it for you.
melgross - Thursday, May 27, 2021 - link
Serviceable mobile devices are also less reliable, and have smaller batteries.del42sa - Wednesday, May 26, 2021 - link
Bulldozer strikes back . LoLPS: it´s interesting design though
GeoffreyA - Thursday, May 27, 2021 - link
Shows that AMD wasn't completely bonkers.del42sa - Thursday, May 27, 2021 - link
it wasn´t a bad idea or bad arch. it was just very bad implementedusiname - Wednesday, May 26, 2021 - link
a510 vs a73 - 25% slower with 35% better power efficiency, 4 years of inovations for you.ET - Wednesday, May 26, 2021 - link
I think it's clear from the DVFS slide on the A510 page of the article that the main difference between the A55 and A510 is that the A510 can reach much higher performance with much higher power use.So yes, anyone expecting much better efficiency will be disappointed.
A510 does lead the way to pure "small core" designs that reach reasonable performance on one hand and low power on the other hand.
Still, I haven't seen a figure comparing core size, and that would be a very important measure.
mode_13h - Thursday, May 27, 2021 - link
> anyone expecting much better efficiency will be disappointed.Efficiency can come from a smaller process node. The A55 and A510 were compared at ISO-process.