Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
A new CI-700 Coherent Interconnect & NI-700 NoC For SoCs
Finally, the last new announcement of the day is a new interconnect and network-on-chip generation. The last time Arm had announced a mobile/client interconnect was back in in 2015 with the CCI-550. The reason for the large gap between IPs, in Arm’s own words, is that ever since Arm’s introduction of the DSU in its CPU complexes, there really hasn’t been any need for a cache coherent interconnect in the market. While that’s eyebrow-raising from a GPU perspective, it makes perfect sense from a CPU perspective, as coherency between CPU cores was the primary driver for such interconnects until then.
With the advent of new more complex computing platforms, such as NPUs, accelerators, and hopeful more use of GPUs in cache-coherent fashions, Arm saw a need gap in its portfolio and decided to update its client-side interconnect IP.


The new CI-700 is a mobile and client optimised variant of Arm’s infrastructure CMN mesh network, implementing important new interoperability with the new IP announced today, such as the new DSU or CPU cores.
The new mesh interconnect scales up from 1 to 8 DSU clusters, and supports up to 8 memory controllers, and also introduces innovations such as a system level cache.
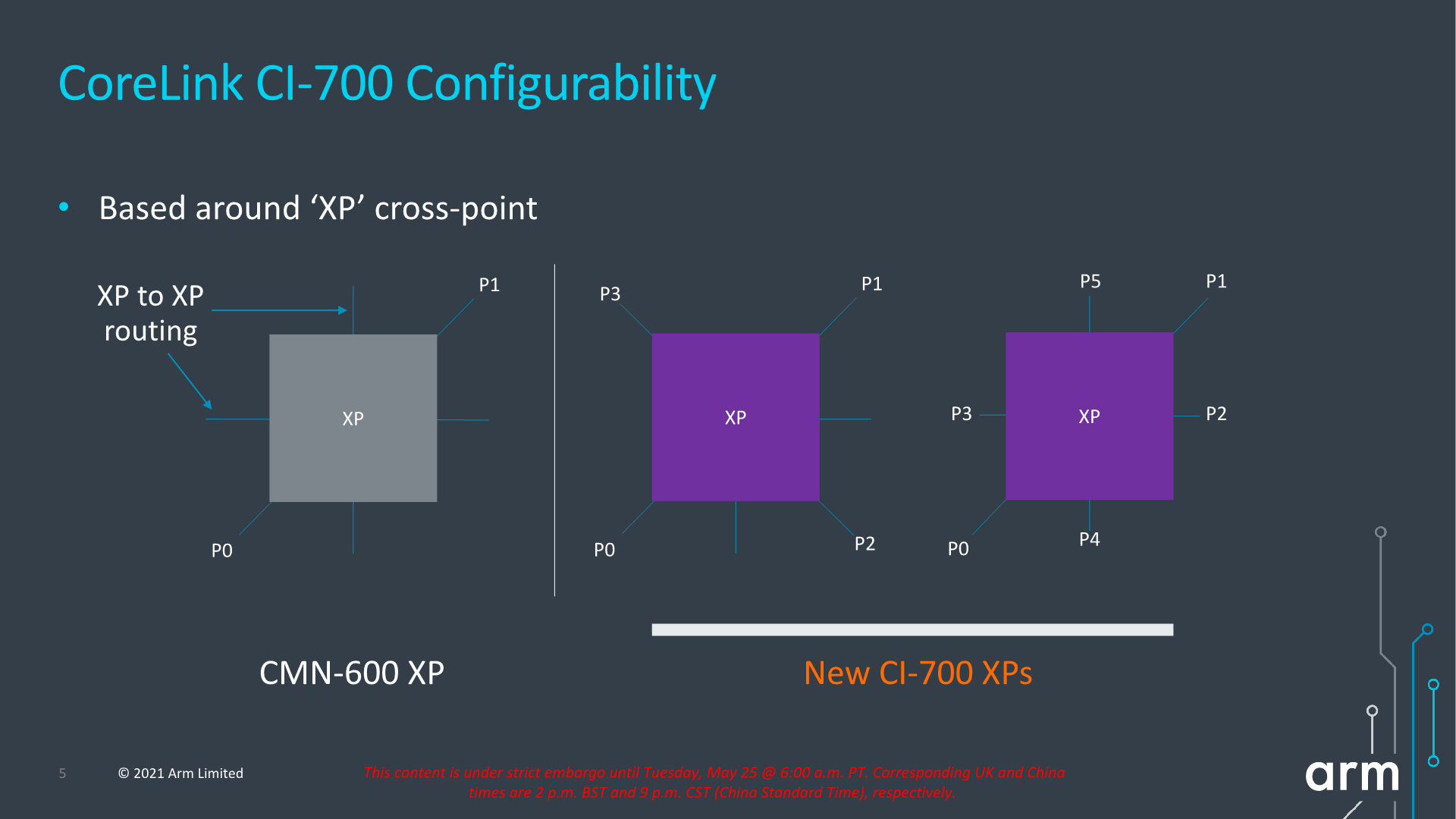

The mesh network topology and building blocks is very similar to what we’ve seen in the CMN infrastructure IP, in that “points” in the mesh are comprised of “cross-points” or “XP”. One differentiation that’s unique to the client mesh implementation is that XPs can have more attached connectivity ports, trading in routing connection paths. The new IP can also be configured as just a sole XP with no real mesh so to speak of, or essentially a 1x1 mesh configuration. This can grow up to a 4x3 mesh in the largest possible configuration.
The mesh supports from 1 to 8 SLC slices, with up to 4MB per slice for a total of 32MB, and snoop filter SRAM with coverage of up to 8MB address space per slice. It’s noted that generally Arm recommends 1.5-2x of coverage of the underlying private cache hierarchies of the mesh clients.
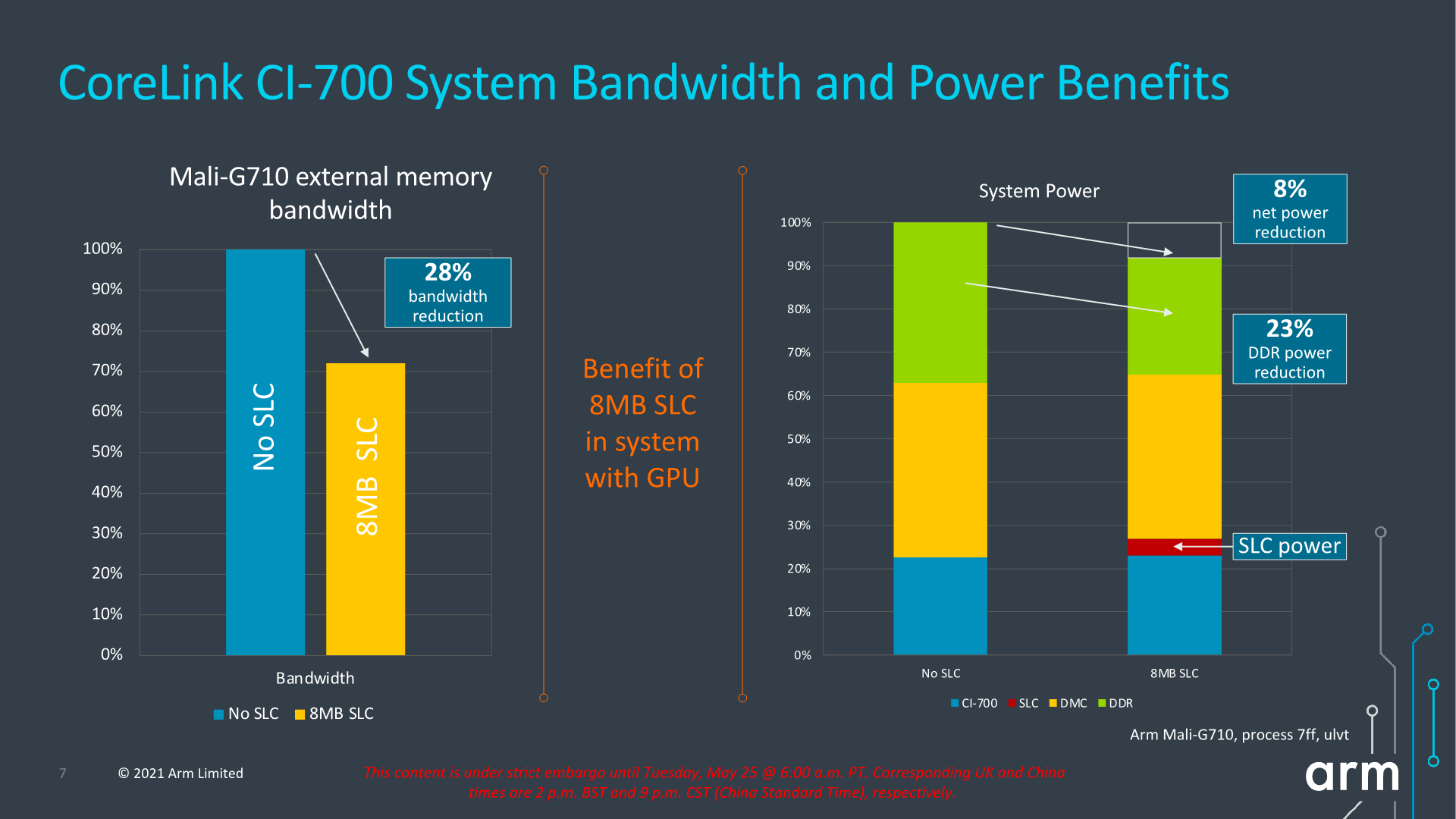
The SLC can server as both a bandwidth amplifier as well as reducing external memory/DRAM transactions, reducing system power reduction.
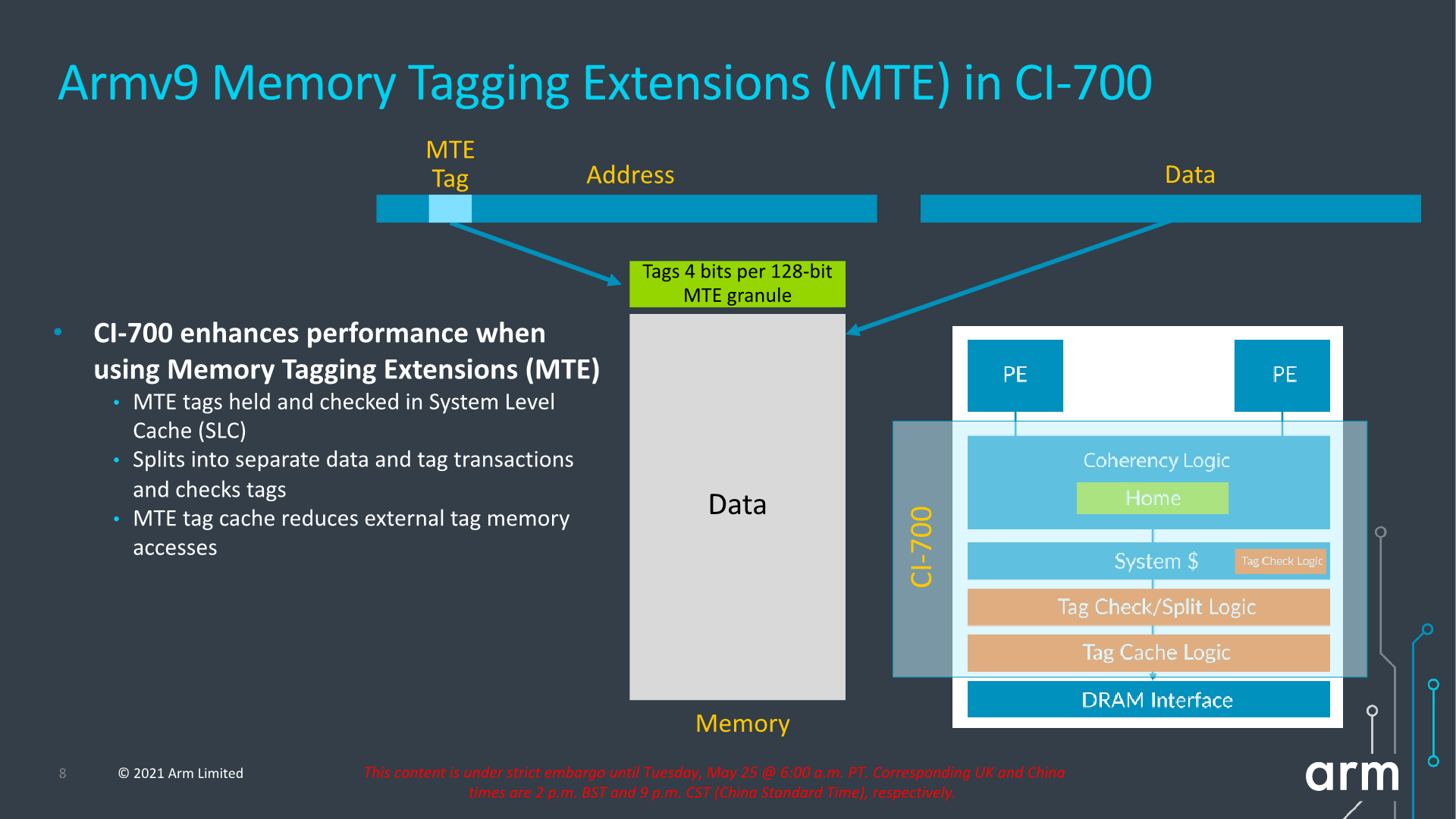
We see a reiteration of the support for MTE, allowing for this generation of IPs to support the feature across the new CPU IP, the DSU, and the new cache coherent interconnect.

Alongside the new CI-700 coherent interconnect, we’re also seeing a new NI-700 network-on-chip for non-coherent data transfers between a SoC’s various IP blocks. The big new improvements here is the introduction of packetization for data transfers, which leads to a reduction of wires and thus improves area efficiency of the NoC on the SoC.
Overall, the new system IP announced today is very interesting, but the one question that’s one has to ask oneself is exactly who these net interconnects are meant for. Over the last few years, we’ve seen essentially every major mobile vendor roll out their own in-house cache-coherent interconnect IP, such as Samsung’s SCI or MediaTek’s MCSI, and other times we don’t see vendors talk about their in-house interconnects at all (Qualcomm). Due to almost everybody having their own IP, I’m not sure what the likelihood would be that any of the big players would jump back to Arm’s own solutions – if somebody were to adopt it, it would rather be amongst the smaller name vendors and newcomers to the market. From a business and IP portfolio perspective, the new designs make a lot of sense and allows to have the building blocks to create a mostly Arm-only SoC, which is an important item to have on the menu for Arm’s more diverse customer base.








181 Comments
View All Comments
mode_13h - Wednesday, May 26, 2021 - link
> Android needs to get their developers to stop using Java and use C/C++/Rust for their apps to eek out the max performance possible.No, I'm sure Google would rather they use Go.
Also, unless you compile your C++ to web asm, it has the disadvantage of leaving out users on newer devices not supported by the NDK version where you built your app. Like RISC V, for instance. Interpreted languages and those that compile into a portable intermediate representation don't have this problem.
> it's a long time nagging issue that I wish the Android community would solve.
Your best hope is that Web Assembly takes over, then.
hlovatt - Thursday, May 27, 2021 - link
> Android needs to get their developers to stop using Java and use C/C++/Rust for their apps to eek out the max performance possible.> Apple's App code base is generally C/C++, that's why they have the performance
Apple code is mainly Objective-C and Swift (neither are particularly fast).
> https://benchmarksgame-team.pages.debian.net/bench...
These benchmarks are largely discredited because they include the start up time in the measurements, which unrealistically hampers virtual machines as used by Java. Its like opening your mailer, typing a couple of characters, and then shutting down your mailer, opening your mailer again, another couple of characters, repeat. Then saying you mailer is slow. Most apps are long running and counting the opening and closing down of the virtual machine for a small task doesn't give useful results.
mode_13h - Wednesday, May 26, 2021 - link
> Apple is in a very very special situation where they control everything. Hardware,> software, product. Plus they use the best process there is at the moment.
> All of this, contributes to their results. Which are very good, but they stem from
> what I told you.
They get a benefit from using the latest process, but that doesn't help them relative to anyone else on that same process node. ARM probably does as much work or more to port their IP to a process node & libraries as Apple does.
They *do* get a benefit from controlling the OS. I'll grant you that. The main thing that can probably help is dialing in clockspeed & thermal management, as well as how load-balancing with the low-power cores is managed.
However, the rest of it is irrelevant for SPEC scores, because the Anandtech team uses the same compilers and the SPEC source is also the same.
> Their cores are not exactly suited for the plethora of android devices that range from 50 bucks to 2000+.
Well, the upper end of that range, yes. That's the biggest thing Apple has in their favor: bigger budgets for bigger cores on newer nodes.
> ARM cpus lose compatibility totally once in a while, which is not something that will work in the long run.
Seems like little-to-no burden for ARMv9 CPUs to retain ARMv8 compatibility, though. When they go to ARMv10, that might be a different story.
> Intel hasn't introduced anything major since 2015!
If Sunny Cove doesn't count as something new, then I think your standards are unrealistic.
BTW, if you want bigger micro-architectural changes, try Gracemont.
Silma - Tuesday, May 25, 2021 - link
Apple & ARM benefit from the best foundries in the world, which has not been the case for Intel for at least 3 years.If Intel catches up in production tech or gets access to the same process than Apple and Co, we'll see who has the better designs for which workloads.
melgross - Tuesday, May 25, 2021 - link
I do think that Intel’s designs are better than AMD designs. They’re not that much s,owner, when they are, and and is on a smaller, faster node. But as far as Apple’s designs, I doubt it. The designs are too different to make that claim. Additionally, and SoC is far more than just CPU cores. That just a fifth of Apple’s SoC.igor velky - Tuesday, May 25, 2021 - link
AMD didnt invent multichip modules, those are lies !IBM had servers with multichip cpus in like 1985ish
Intel Core2 had some cpus which were MCM, too.
ten or so years ago.
mode_13h - Wednesday, May 26, 2021 - link
> Intel Core2 had some cpus which were MCMThe Pentium Pro had its L2 cache on a separate die.
kgardas - Tuesday, May 25, 2021 - link
x86 is dead? Well, it is, welcome amd64.Anyway, I would not consider latest Zen or Sunny Cove/Willow Cove cores as non-competitive even with the latest Apple Mx designs. IMHO they are doing fine. Now, do you know that Alder Lake/Sapphire Rappids will have Golden Cove? And that should arrive this and early next year probably. The core should again provide quite nice bump in IPC. So both ARM and even Apple will have again more than adequate competition. No, neither intel nor amd are dead. Pretty exciting times ahead...
GeoffreyA - Tuesday, May 25, 2021 - link
Oh boy, here we go again. x86, dead. Apple M1, enchanted stuff. Intel/AMD, rubbish for the dump. All hail, Apple!Silver5urfer - Wednesday, May 26, 2021 - link
Logically their tunnel vision has only 2 possible reasonsOne - Apple hardcore fans and somehow their daily tasks and lives rely only on Mac OS or iOS, ignorant on the reality and dumb to believe SPEC and Apple marketing PR.
Two - They hate Intel a lot and also PC platform a lot, have a console probably and a Macbook BGA junk.
I do not know what else and why would anyone hate x86 processors from Intel and AMD, I do not see any point since they are the PCs we can own today and they will last literally for decades. People are using old school Xeon for home server and old school pre SSE4.2, basically Phenom II and Intel Core 2 Quad Q6600 Processors to play damn latest games with community patches for .exes, then we have the latest HW for PC in HEDT and Mainstream for multiple use cases.
Why would anyone hate the only processing standard which has excellent backwards compat full blown parts system for DIY and repair etc, and literally choice of your own OS - Linux, Windows and some Intel HW for Hackintosh. Yep they are dumb and ignorant for sure.