Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
by Andrei Frumusanu on April 6, 2021 11:00 AM EST- Posted in
- Servers
- CPUs
- Intel
- Xeon
- Enterprise
- Xeon Scalable
- Ice Lake-SP
SPEC - Per-Core Performance under Load
A metric that is actually more interesting than isolated single-thread performance, is actually per-thread performance in a fully loaded system. This actually is a measurement and benchmark figure that would greatly interest enterprises and customers which are running software or workloads that are possibly licensed on a per-core basis, or simply workloads that require a certain level of per-thread service level agreement in terms of performance.
This has been a strong-point of Intel SKUs for some time now, even when the chips wouldn’t be competitive in terms of total throughput. With the new Ice Lake SPs SKUs now more notably increasing total throughput, it’ll be interesting to see the per-thread breakdown and resulting performance:
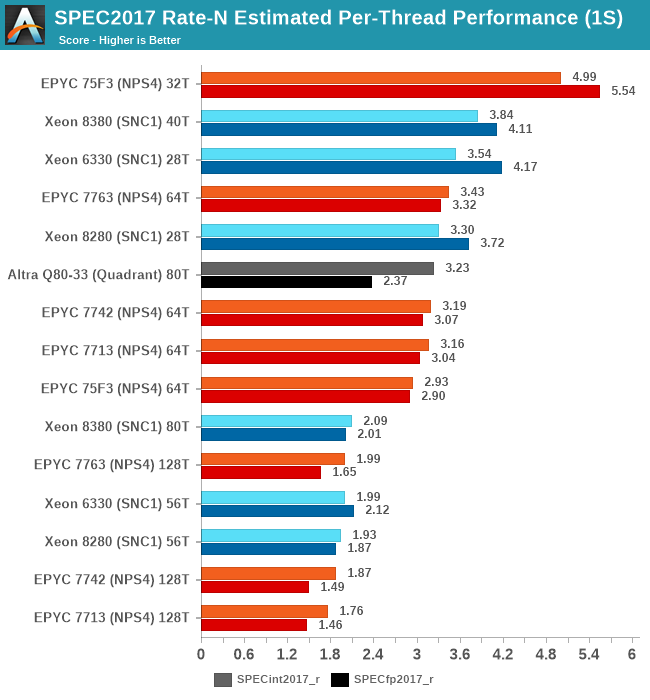
Because the total throughput generational performance increase is larger than the core count increase of the parts, this means that per-thread and per-core performance is higher with this generation. The Xeon 8380 is posting +16.3% and +10.4% per-thread performance versus the Xeon 8280 when only using one thread per core.
Interestingly, these figures are less at +8.2 and +7.4% when using both SMT threads per core. Intel has explained such an increase through the better usage of shared microarchitectural structure usage in the new Sunny Cove cores, essentially diminishing the SMT yield by improving 1/T per core performance.
Generally, Intel is extremely competitive in this benchmark metric, and while AMD easily beats them with the frequency-optimised parts, it’s an advantage that should help Intel in the SLA-centric workloads.








169 Comments
View All Comments
ricebunny - Tuesday, April 6, 2021 - link
See it like it this: the benchmark is a racing track, the CPU is a car and the compiler is the driver. If I want to get the best time for each car on a given track I will not have them driven by the same driver. Rather, I will get the best driver for each car. A single driver will repeat the same mistakes in both cars, but one car may be more forgiving than the other.DigitalFreak - Tuesday, April 6, 2021 - link
Is the compiler called The Stig?Wilco1 - Tuesday, April 6, 2021 - link
Then you are comparing drivers and not cars. A good driver can win a race with a slightly slower car. And I know a much faster driver that can beat your best driver. And he will win even with a much slower car. So does the car really matter as long as you have a really good driver?In the real world we compare cars by subjecting them to identical standardized tests rather than having a grandma drive one car and Lewis Hamilton drive another when comparing their performance/efficiency/acceleration/safety etc.
Makste - Wednesday, April 7, 2021 - link
Well saidricebunny - Wednesday, April 7, 2021 - link
Based on the compiler options that Anandtech used, we already have the situation that Intel and AMD CPUs are executing different code for the same benchmark. From there it’s only a small step further to use the best compiler for each CPU.mode_13h - Wednesday, April 7, 2021 - link
So, you're saying make the situation MORE lopsided? Instead, maybe they SHOULD use the same compiled code!mode_13h - Wednesday, April 7, 2021 - link
This is a dumb analogy. CPUs are not like race cars. They're more like family sedans or maybe 18-wheeler semi trucks (in the case of server CPUs). As such, they should be tested the way most people are going to use them.And almost NOBODY is compiling all their software with ICC. I almost never even hear about ICC, any more.
I'm even working with an Intel applications engineer on a CPU performance problem, and even HE doesn't tell me to build their own Intel-developed software with ICC!
KurtL - Wednesday, April 7, 2021 - link
Using identical compilers is the most unfair option there is to compare CPUs. Hardware and software on a modern system is tightly connected so it only makes sense to use those compilers on each platform that also are best optimised for that particular platform. Using a compiler that is underdeveloped for one platform is what makes an unfair comparison.Makste - Wednesday, April 7, 2021 - link
I think that using one unoptimized compiler for both is the best way to judge their performance. Such a compiler rules out bias and concentrates on pure hardware capabilitiesricebunny - Wednesday, April 7, 2021 - link
You do realize that even the same gcc compiler with the settings that Anandtech used will generate different machine code for Intel and AMD architectures, let alone for ARM? To really make it "apples-to-apples" on Linux x86 they should've used "--with-tune=generic" option: then both CPUs will execute the exact same code.But personally, I would prefer that they generated several binaries for each test, built them with optimal settings for each of the commonly used compilers: gcc, icc, aocc on Linux and perhaps even msvc on Windows. It's a lot more work I know, but I would appreciate it :)