Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
by Andrei Frumusanu on April 6, 2021 11:00 AM EST- Posted in
- Servers
- CPUs
- Intel
- Xeon
- Enterprise
- Xeon Scalable
- Ice Lake-SP
SPEC - Multi-Threaded Performance
Picking up from the power efficiency discussion, let’s dive directly into the multi-threaded SPEC results. As usual, because these are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2 (for Zen3 as well due to GCC 10.2 not having znver3).
The new Ice Lake SP parts are using the -march/-mtune=icelake-server target. It’s to be noted that I briefly tested the system with the Skylake binaries, with little differences within margin of error.
I’m limiting the detailed comparison data to the flagship SKUs, to indicate peak performance of each platform. For that reason it’s not exactly as much an architectural comparison as it’s more of a top SKU comparison.
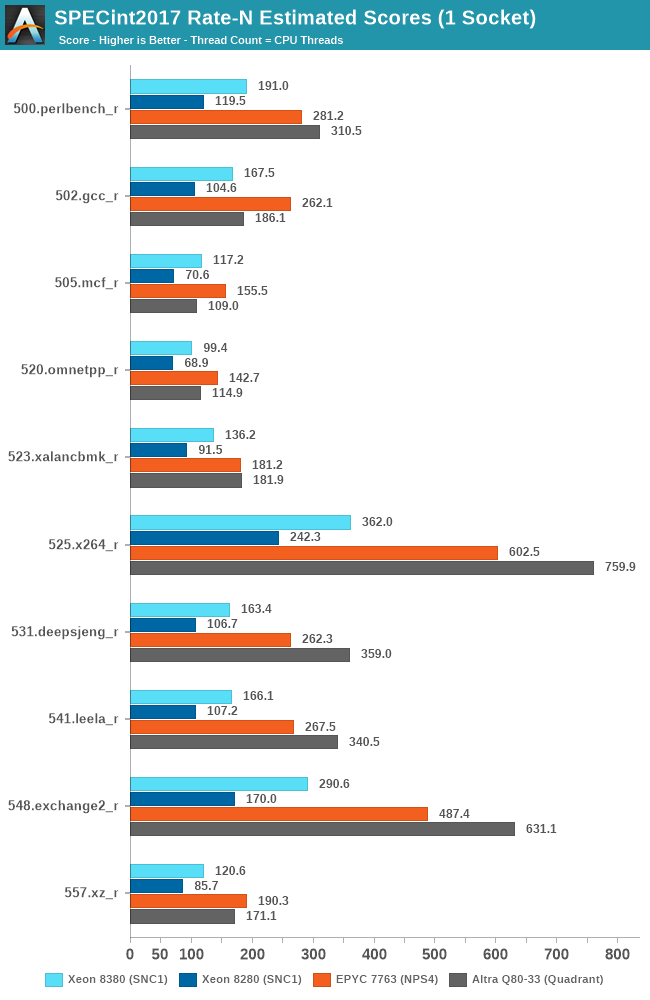
To not large surprise, the Xeon 8380 is posting very impressive performance advancements compared to the Xeon 8280, with large increases across the board for all workloads. The geo-mean increase is +54% with a low of +40% up to a high of +71%.
It’s to be noted that while the new Ice Lake system is a major generational boost, it’s nowhere near enough to catch up with the performance of the AMD Milan or Rome, or Ampere’s Altra when it comes to total throughput.
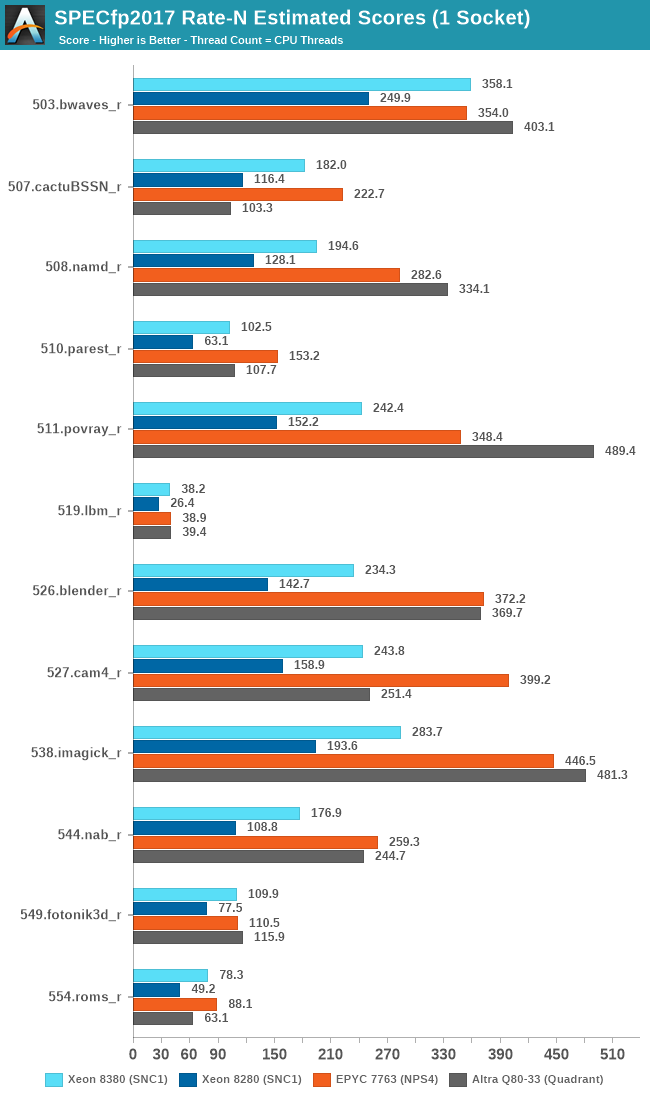
Looking at the FP suite, we have more workloads that are purely memory performance bound, and the Ice Lake Xeon 8380 again is posting significant performance increases compared to its predecessor, with a geo-mean of +53% with a range of +41% to +64%.
In some of the workloads, the new Xeon now catches up and is on par with AMD’s EPYC 7763 due to the fact that both systems have the same memory configuration with 8-channel DDR4-3200.
In any other workloads that requires more CPU compute power, the Xeon doesn’t hold up nearly as well, falling behind the competition by significant margins.
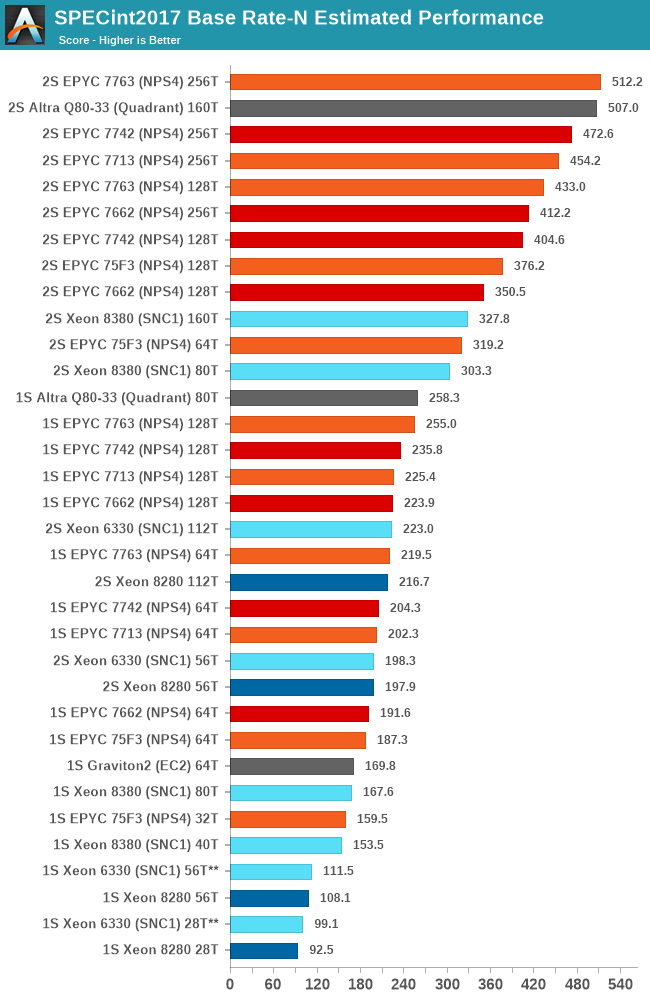
In the aggregate geomean scores, we’re seeing again that the new Xeon 8380 allows Intel to significantly reposition itself in the performance charts. Unfortunately, this is only enough to match the lower core count SKUs from the competition, as AMD and Ampere are still well ahead by massive leads – although admittedly the gap isn’t as embarrassing as it was before.
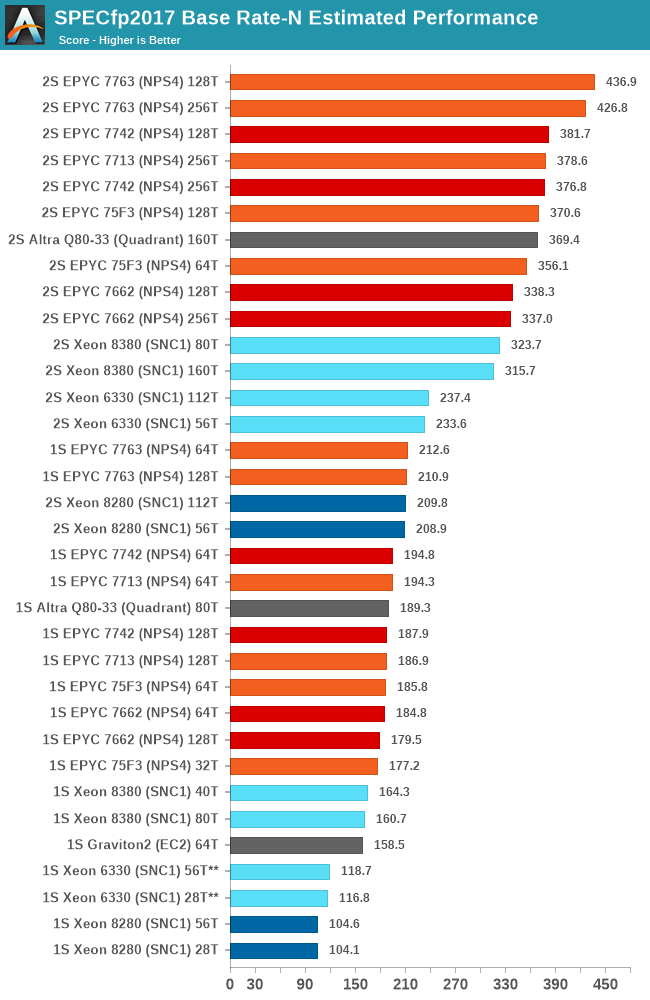
In the floating-point suite, the results are a bit more in favour for the Xeon 8380 compared to the integer suite, as the memory performance is weighed more into the total contribution of the total performance. It’s still not enough to beat the AMD and Ampere parts, but it’s much more competitive than it was before.
The Xeon 6330 is showcasing minor performance improvements over the 8280 and its cheaper equivalent the 6258R, but at least comes at half the cost – so while performance isn’t very impressive, the performance / $ might be more competitive.

Our performance results match Intel’s own marketing materials when it comes to the generational gains, actually even surpassing Intel’s figures by a few percent.
If you would be looking at Intel’s slide above, you could be extremely enthusiastic about Intel’s new generation, as indeed the performance improvements are extremely large compared to a Cascade Lake system.
As impressive as those generational numbers are, they really only help to somewhat narrow the Grand Canyon sized competitive performance gap we’ve had to date, and the 40-core Xeon 8380 still loses out to a 32-core Milan, and from a performance / price comparison, even a premium 75F3 costs 40% less than the Xeon 8380. Lower SKUs in the Ice Lake line-up would probably fare better in perf/$, however would also just lower the performance to an even worse competitive positioning.








169 Comments
View All Comments
ricebunny - Tuesday, April 6, 2021 - link
See it like it this: the benchmark is a racing track, the CPU is a car and the compiler is the driver. If I want to get the best time for each car on a given track I will not have them driven by the same driver. Rather, I will get the best driver for each car. A single driver will repeat the same mistakes in both cars, but one car may be more forgiving than the other.DigitalFreak - Tuesday, April 6, 2021 - link
Is the compiler called The Stig?Wilco1 - Tuesday, April 6, 2021 - link
Then you are comparing drivers and not cars. A good driver can win a race with a slightly slower car. And I know a much faster driver that can beat your best driver. And he will win even with a much slower car. So does the car really matter as long as you have a really good driver?In the real world we compare cars by subjecting them to identical standardized tests rather than having a grandma drive one car and Lewis Hamilton drive another when comparing their performance/efficiency/acceleration/safety etc.
Makste - Wednesday, April 7, 2021 - link
Well saidricebunny - Wednesday, April 7, 2021 - link
Based on the compiler options that Anandtech used, we already have the situation that Intel and AMD CPUs are executing different code for the same benchmark. From there it’s only a small step further to use the best compiler for each CPU.mode_13h - Wednesday, April 7, 2021 - link
So, you're saying make the situation MORE lopsided? Instead, maybe they SHOULD use the same compiled code!mode_13h - Wednesday, April 7, 2021 - link
This is a dumb analogy. CPUs are not like race cars. They're more like family sedans or maybe 18-wheeler semi trucks (in the case of server CPUs). As such, they should be tested the way most people are going to use them.And almost NOBODY is compiling all their software with ICC. I almost never even hear about ICC, any more.
I'm even working with an Intel applications engineer on a CPU performance problem, and even HE doesn't tell me to build their own Intel-developed software with ICC!
KurtL - Wednesday, April 7, 2021 - link
Using identical compilers is the most unfair option there is to compare CPUs. Hardware and software on a modern system is tightly connected so it only makes sense to use those compilers on each platform that also are best optimised for that particular platform. Using a compiler that is underdeveloped for one platform is what makes an unfair comparison.Makste - Wednesday, April 7, 2021 - link
I think that using one unoptimized compiler for both is the best way to judge their performance. Such a compiler rules out bias and concentrates on pure hardware capabilitiesricebunny - Wednesday, April 7, 2021 - link
You do realize that even the same gcc compiler with the settings that Anandtech used will generate different machine code for Intel and AMD architectures, let alone for ARM? To really make it "apples-to-apples" on Linux x86 they should've used "--with-tune=generic" option: then both CPUs will execute the exact same code.But personally, I would prefer that they generated several binaries for each test, built them with optimal settings for each of the commonly used compilers: gcc, icc, aocc on Linux and perhaps even msvc on Windows. It's a lot more work I know, but I would appreciate it :)