Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
by Andrei Frumusanu on April 6, 2021 11:00 AM EST- Posted in
- Servers
- CPUs
- Intel
- Xeon
- Enterprise
- Xeon Scalable
- Ice Lake-SP
SPEC - Multi-Threaded Performance
Picking up from the power efficiency discussion, let’s dive directly into the multi-threaded SPEC results. As usual, because these are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2 (for Zen3 as well due to GCC 10.2 not having znver3).
The new Ice Lake SP parts are using the -march/-mtune=icelake-server target. It’s to be noted that I briefly tested the system with the Skylake binaries, with little differences within margin of error.
I’m limiting the detailed comparison data to the flagship SKUs, to indicate peak performance of each platform. For that reason it’s not exactly as much an architectural comparison as it’s more of a top SKU comparison.
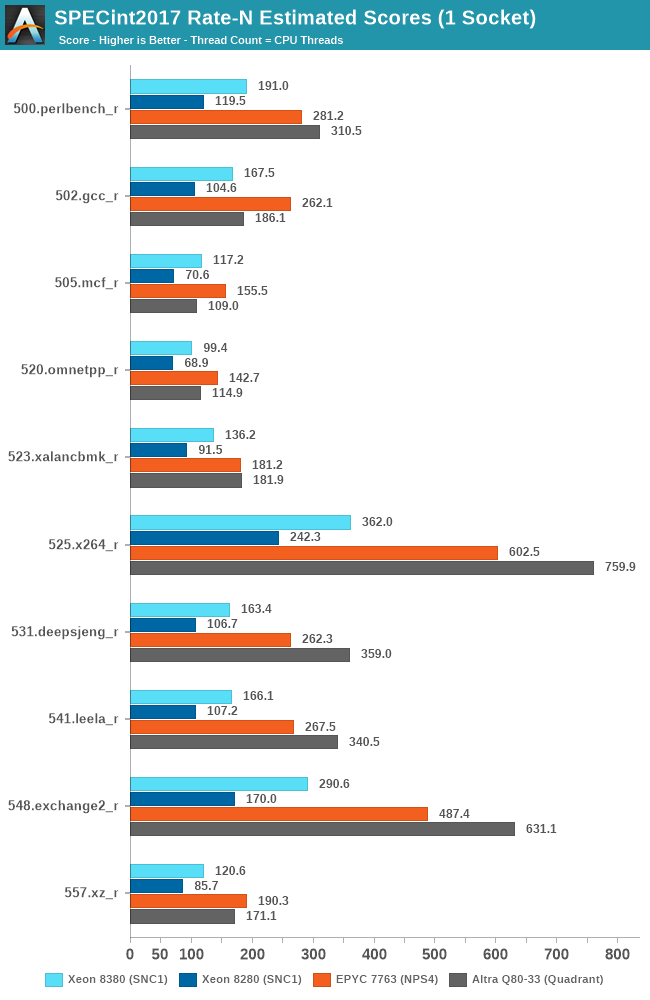
To not large surprise, the Xeon 8380 is posting very impressive performance advancements compared to the Xeon 8280, with large increases across the board for all workloads. The geo-mean increase is +54% with a low of +40% up to a high of +71%.
It’s to be noted that while the new Ice Lake system is a major generational boost, it’s nowhere near enough to catch up with the performance of the AMD Milan or Rome, or Ampere’s Altra when it comes to total throughput.
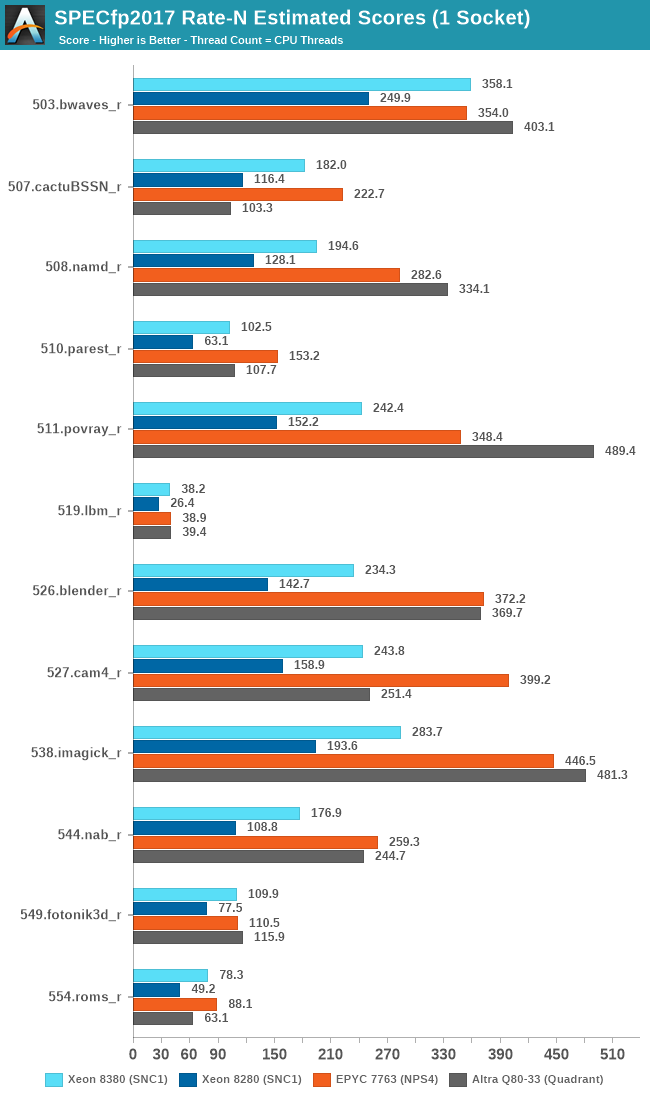
Looking at the FP suite, we have more workloads that are purely memory performance bound, and the Ice Lake Xeon 8380 again is posting significant performance increases compared to its predecessor, with a geo-mean of +53% with a range of +41% to +64%.
In some of the workloads, the new Xeon now catches up and is on par with AMD’s EPYC 7763 due to the fact that both systems have the same memory configuration with 8-channel DDR4-3200.
In any other workloads that requires more CPU compute power, the Xeon doesn’t hold up nearly as well, falling behind the competition by significant margins.
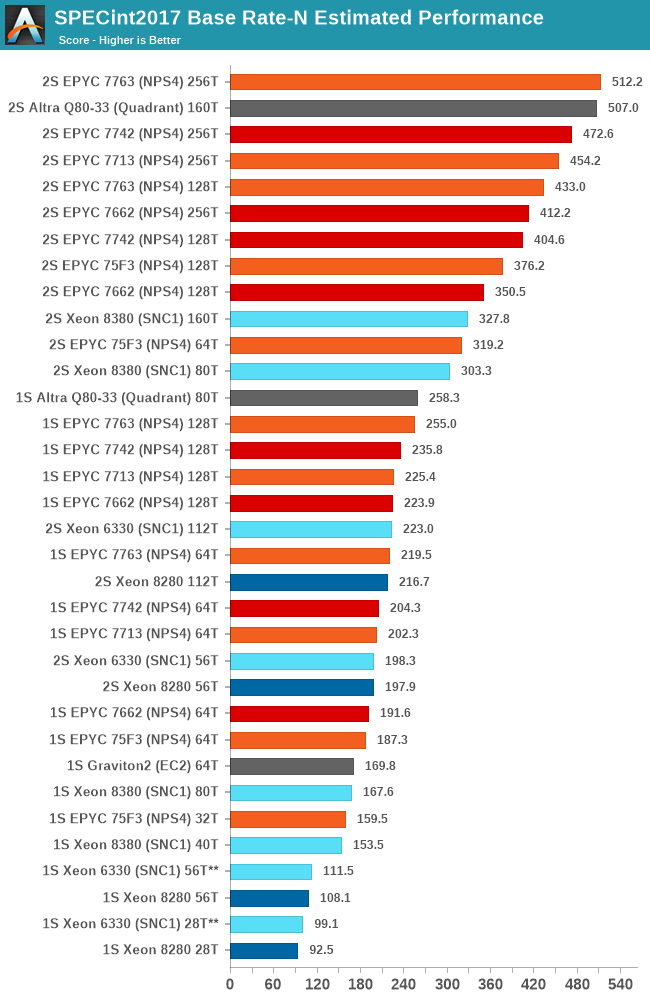
In the aggregate geomean scores, we’re seeing again that the new Xeon 8380 allows Intel to significantly reposition itself in the performance charts. Unfortunately, this is only enough to match the lower core count SKUs from the competition, as AMD and Ampere are still well ahead by massive leads – although admittedly the gap isn’t as embarrassing as it was before.
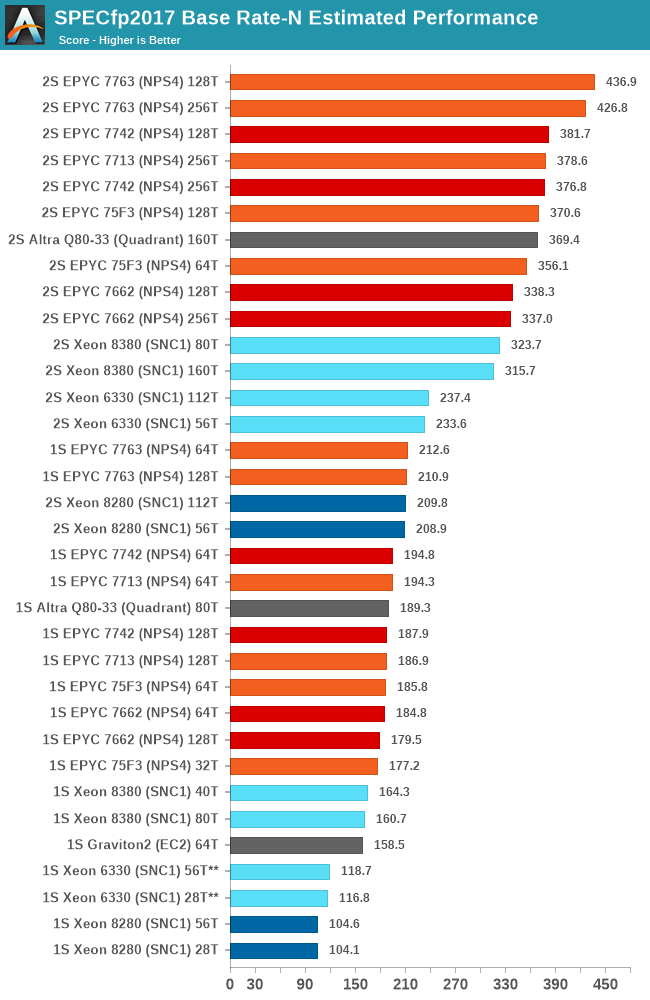
In the floating-point suite, the results are a bit more in favour for the Xeon 8380 compared to the integer suite, as the memory performance is weighed more into the total contribution of the total performance. It’s still not enough to beat the AMD and Ampere parts, but it’s much more competitive than it was before.
The Xeon 6330 is showcasing minor performance improvements over the 8280 and its cheaper equivalent the 6258R, but at least comes at half the cost – so while performance isn’t very impressive, the performance / $ might be more competitive.

Our performance results match Intel’s own marketing materials when it comes to the generational gains, actually even surpassing Intel’s figures by a few percent.
If you would be looking at Intel’s slide above, you could be extremely enthusiastic about Intel’s new generation, as indeed the performance improvements are extremely large compared to a Cascade Lake system.
As impressive as those generational numbers are, they really only help to somewhat narrow the Grand Canyon sized competitive performance gap we’ve had to date, and the 40-core Xeon 8380 still loses out to a 32-core Milan, and from a performance / price comparison, even a premium 75F3 costs 40% less than the Xeon 8380. Lower SKUs in the Ice Lake line-up would probably fare better in perf/$, however would also just lower the performance to an even worse competitive positioning.








169 Comments
View All Comments
mode_13h - Thursday, April 8, 2021 - link
Please tell me you did this test with an ICC released only a couple years ago, or else I feel embarrassed for you polluting this discussion with such irrelevant facts.Oxford Guy - Sunday, April 11, 2021 - link
It wasn't that long ago.If you want to increase the signal to noise ratio you should post something substantive.
For instance, if you think think ICC no longer produces faster Blender builds why not post some evidence to that effect?
eastcoast_pete - Tuesday, April 6, 2021 - link
This Xeon generation exists primarily because Intel had to come through and deliver something in 10 nm, after announcing the heck out of it for years. As an actual processor, they are not bad as far as Xeons are concerned, but clearly inferior to AMD's current EPYC line, especially on price/performance. Plus, we and the world know that the real update is around the corner within a year: Sapphire Rapids. That one promises a lot of performance uplift, not the least by having PCI-5 and at least the option of directly linked HBM for RAM. Lastly, if Intel would have managed to make this line compatible with the older socket (it's not), one could at least have used these Ice Lake Xeons to update Cooper Lake systems via a CPU swap. As it stands, I don't quite see the value proposition, unless you're in an Intel shop and need capacity very badly right now.Limadanilo2022 - Tuesday, April 6, 2021 - link
Agreed. Both Ice Lake and Rocket lake are just placeholders to try to make something before the real improvement comes with Saphire rapids and Alder Make respectively... I'm one that says that AMD really needs the competition right now to not get sloppy and become "2017-2020 Intel". I want to see both competing hard in the next years aheaddrothgery - Wednesday, April 7, 2021 - link
Rocket Lake is a stopgap. Ice Lake (and Ice Lake SP) were just late; they would have been unquestioned market leaders if launched on time and even now mostly just run into problems when the competition is throwing way more cores at the problem.AdrianBc - Wednesday, April 7, 2021 - link
No, Ice Lake Server cores have a much lower clock frequency and a much smaller L3 cache than Epyc 7xx3, so they are much slower core per core than AMD Milan for any general purpose application, e.g. software compilation.The Ice Lake Server cores have a double number of floating-point multipliers that can be used by AVX-512 programs, so they are faster (despite their clock frequency deficit) for the applications that are limited by FP multiplication throughput or that can use other special AVX-512 features, e.g. the instructions useful for machine learning.
Oxford Guy - Wednesday, April 7, 2021 - link
'limited by FP multiplication throughput or that can use other special AVX-512 features, e.g. the instructions useful for machine learning.'How do they compare with Power?
How do they compare with GPUs? (I realize that a GPU is very good at a much more limited palette of work types versus a general-purpose CPU. However... how much overlap there is between a GPU and AVX-512 is something at least non-experts will wonder about.)
AdrianBc - Thursday, April 8, 2021 - link
The best GPUs from NVIDIA and AMD can provide between 3 and 4 times more performance per watt than the best Intel Xeons with AVX-512.However most GPUs are usable only in applications where low precision is appropriate, i.e. graphics and machine learning.
The few GPUs that can be used for applications that need higher precision (e.g. NVIDIA A100 or Radeon Instinct) are extremely expensive, much more than Xeons or Epycs, and individuals or small businesses have very little chances to be able to buy them.
mode_13h - Friday, April 9, 2021 - link
Please re-check the price list. The top-end A100 does sell for a bit more than the $8K list price of the top Xeon and EPYC, however MI100 seems to be pretty close. perf/$ is still wildly in favor of GPUs.Unfortunately, if you're only looking at the GPUs' ordinary compute specs, you're missing their real point of differentiation, which is their low-precision tensor performance. That's far beyond what the CPUs can dream of!
Trust there are good reasons why Intel scrapped Xeon Phi, after flogging it for 2 generations (plus a few prior unreleased iterations), and adopted a pure GPU approach to compute!
mode_13h - Thursday, April 8, 2021 - link
"woulda, coulda, shoulda"Ice Lake SP is not even competitive with Rome. So, they missed their market window by quite a lot!