Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
by Andrei Frumusanu on April 6, 2021 11:00 AM EST- Posted in
- Servers
- CPUs
- Intel
- Xeon
- Enterprise
- Xeon Scalable
- Ice Lake-SP
SPEC - Multi-Threaded Performance
Picking up from the power efficiency discussion, let’s dive directly into the multi-threaded SPEC results. As usual, because these are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2 (for Zen3 as well due to GCC 10.2 not having znver3).
The new Ice Lake SP parts are using the -march/-mtune=icelake-server target. It’s to be noted that I briefly tested the system with the Skylake binaries, with little differences within margin of error.
I’m limiting the detailed comparison data to the flagship SKUs, to indicate peak performance of each platform. For that reason it’s not exactly as much an architectural comparison as it’s more of a top SKU comparison.
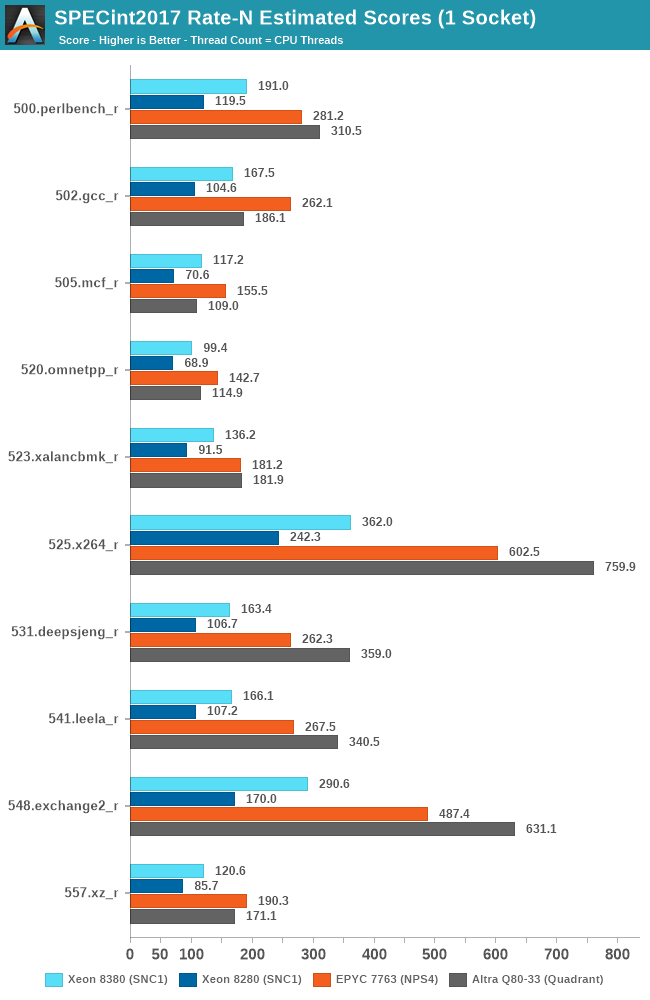
To not large surprise, the Xeon 8380 is posting very impressive performance advancements compared to the Xeon 8280, with large increases across the board for all workloads. The geo-mean increase is +54% with a low of +40% up to a high of +71%.
It’s to be noted that while the new Ice Lake system is a major generational boost, it’s nowhere near enough to catch up with the performance of the AMD Milan or Rome, or Ampere’s Altra when it comes to total throughput.
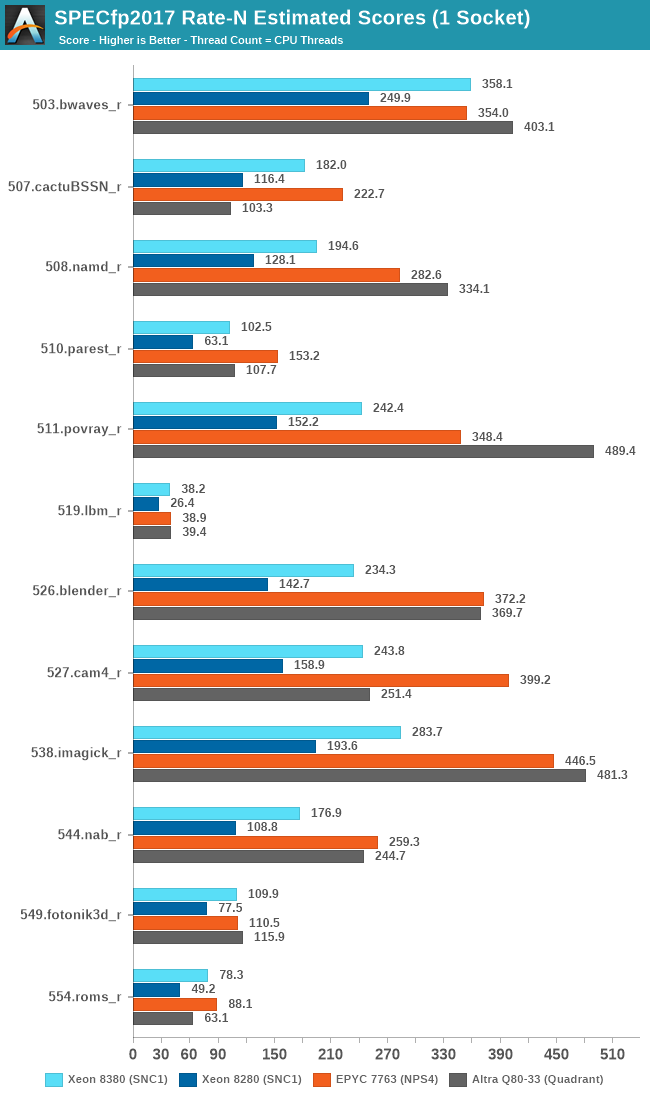
Looking at the FP suite, we have more workloads that are purely memory performance bound, and the Ice Lake Xeon 8380 again is posting significant performance increases compared to its predecessor, with a geo-mean of +53% with a range of +41% to +64%.
In some of the workloads, the new Xeon now catches up and is on par with AMD’s EPYC 7763 due to the fact that both systems have the same memory configuration with 8-channel DDR4-3200.
In any other workloads that requires more CPU compute power, the Xeon doesn’t hold up nearly as well, falling behind the competition by significant margins.
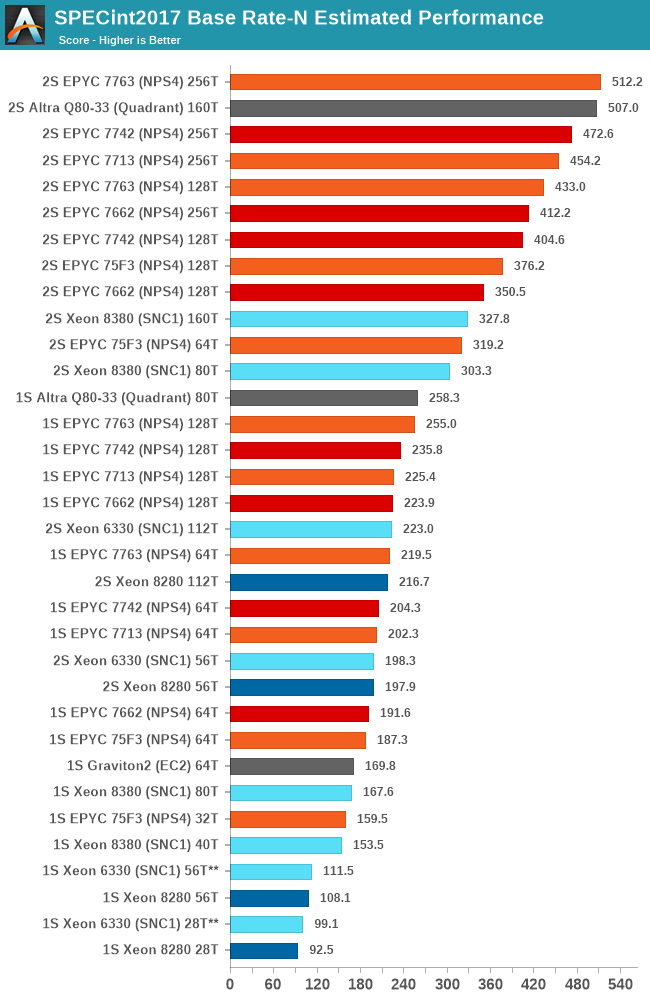
In the aggregate geomean scores, we’re seeing again that the new Xeon 8380 allows Intel to significantly reposition itself in the performance charts. Unfortunately, this is only enough to match the lower core count SKUs from the competition, as AMD and Ampere are still well ahead by massive leads – although admittedly the gap isn’t as embarrassing as it was before.
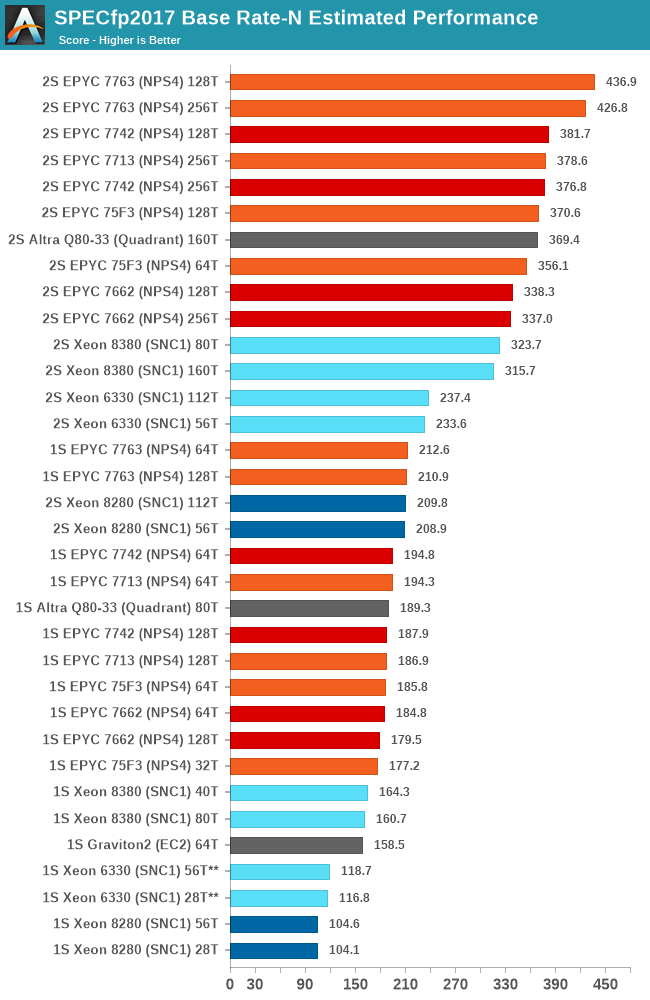
In the floating-point suite, the results are a bit more in favour for the Xeon 8380 compared to the integer suite, as the memory performance is weighed more into the total contribution of the total performance. It’s still not enough to beat the AMD and Ampere parts, but it’s much more competitive than it was before.
The Xeon 6330 is showcasing minor performance improvements over the 8280 and its cheaper equivalent the 6258R, but at least comes at half the cost – so while performance isn’t very impressive, the performance / $ might be more competitive.

Our performance results match Intel’s own marketing materials when it comes to the generational gains, actually even surpassing Intel’s figures by a few percent.
If you would be looking at Intel’s slide above, you could be extremely enthusiastic about Intel’s new generation, as indeed the performance improvements are extremely large compared to a Cascade Lake system.
As impressive as those generational numbers are, they really only help to somewhat narrow the Grand Canyon sized competitive performance gap we’ve had to date, and the 40-core Xeon 8380 still loses out to a 32-core Milan, and from a performance / price comparison, even a premium 75F3 costs 40% less than the Xeon 8380. Lower SKUs in the Ice Lake line-up would probably fare better in perf/$, however would also just lower the performance to an even worse competitive positioning.








169 Comments
View All Comments
mode_13h - Monday, April 12, 2021 - link
With regard specifically to testing AVX-512, perhaps the best method is to include results both with and without it. This serves the dual-role of informing customers of the likely performance for software compiled with more typical options, as well as showing how much further performance is to be gained by using an AVX-512 optimized build.KurtL - Wednesday, April 7, 2021 - link
GCC the industry standard in real world? Maybe in that part of the world where you live, but not everywhere. It is only true in a part of the world. HPC centres have relied on icc for ages for much of the performance-critical code, though GCC is slowly catching up, at least for C and C++ but not at all for Fortran, an important language in HPC (I just read it made it back in the top-20 of most used languages after falling back to position 34 a year or so ago). In embedded systems and the non-x86-world in general, LLVM derived compilers have long been the norm. Commercial compiler vendors and CPU manufacturers are all moving to LLVM-based compilers or have been there for years already.Wilco1 - Wednesday, April 7, 2021 - link
Yes GCC is the industry standard for Linux. That's a simple fact, not something you can dispute.In HPC people are willing to use various compilers to get best performance, so it's certainly not purely ICC. And HPC isn't exclusively Intel or x86 based either. LLVM is increasing in popularity in the wider industry but it still needs to catch up to GCC in performance.
mode_13h - Wednesday, April 7, 2021 - link
GCC is the only supported compiler for building the Linux kernel, although Google is working hard to make it build with LLVM. They seem to believe it's better for security.From the benchmarks that Phoronix routinely publishes, each has its strengths and weaknesses. I think neither is a clear winner.
Wilco1 - Thursday, April 8, 2021 - link
Plus almost all distros use GCC - there is only one I know that uses LLVM. LLVM is slowly gaining popularity though.They are fairly close for general code, however recent GCC versions significantly improved vectorization, and that helps SPEC.
Wilco1 - Tuesday, April 6, 2021 - link
ICC and AMD's AOCC are SPEC trick compilers. Neither is used much in the real world since for real code they are typically slower than GCC or LLVM.Btw are you equally happy if I propose to use a compiler which replaces critical inner loops of the benchmarks with hand-optimized assembler code? It would be foolish not to take advantage of the extra performance you get only on those benchmarks...
ricebunny - Tuesday, April 6, 2021 - link
They are not SPEC tricks. You can use these compilers for any compliant C++ code that you have. In the last 10 years, the only time I didn’t use icc with Intel chips was on systems where I had no control over the sw ecosystem.Wilco1 - Tuesday, April 6, 2021 - link
They only exist because of SPEC. The latest ICC is now based on LLVM since it was falling further behind on typical code.ricebunny - Tuesday, April 6, 2021 - link
From my experience icc consistently produced better vectorized code.Anandtech again didn’t publicize the compiler flags they used to build the benchmark code. By default, gcc will not generate avx512 optimized code.
Wilco1 - Tuesday, April 6, 2021 - link
Maybe compared to old GCC/LLVM versions, but things have changed. There is now little difference between ICC and GCC when running SPEC in terms of vectorized performance. Note the amount of code that can benefit from AVX-512 is absolutely tiny, and the speedups in the real world are smaller than expected (see eg. SIMDJson results with hand-optimized AVX-512).And please read the article - the setup is clearly explained in every review: "We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2 (for Zen3 as well due to GCC 10.2 not having znver3). "