Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
by Andrei Frumusanu on April 6, 2021 11:00 AM EST- Posted in
- Servers
- CPUs
- Intel
- Xeon
- Enterprise
- Xeon Scalable
- Ice Lake-SP
Compiling LLVM, NAMD Performance
As we’re trying to rebuild our server test suite piece by piece – and there’s still a lot of work go ahead to get a good representative “real world” set of workloads, one more highly desired benchmark amongst readers was a more realistic compilation suite. Chrome and LLVM codebases being the most requested, I landed on LLVM as it’s fairly easy to set up and straightforward.
git clone https://github.com/llvm/llvm-project.gitcd llvm-projectgit checkout release/11.xmkdir ./buildcd ..mkdir llvm-project-tmpfssudo mount -t tmpfs -o size=10G,mode=1777 tmpfs ./llvm-project-tmpfscp -r llvm-project/* llvm-project-tmpfscd ./llvm-project-tmpfs/buildcmake -G Ninja \ -DLLVM_ENABLE_PROJECTS="clang;libcxx;libcxxabi;lldb;compiler-rt;lld" \ -DCMAKE_BUILD_TYPE=Release ../llvmtime cmake --build .We’re using the LLVM 11.0.0 release as the build target version, and we’re compiling Clang, libc++abi, LLDB, Compiler-RT and LLD using GCC 10.2 (self-compiled). To avoid any concerns about I/O we’re building things on a ramdisk. We’re measuring the actual build time and don’t include the configuration phase as usually in the real world that doesn’t happen repeatedly.
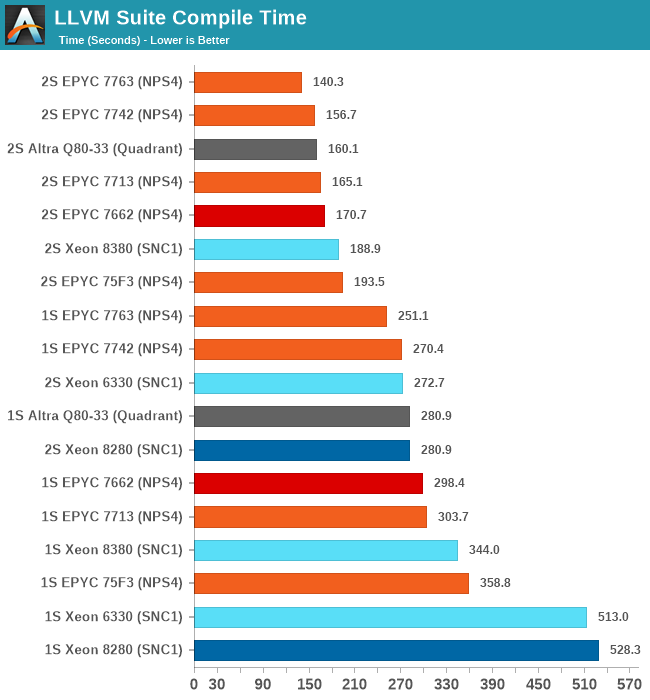
Starting off with the Xeon 8380, we’re looking at large generational improvements for the new Ice Lake SP chip. A 33-35% improvement in compile time depending on whether we’re looking at 2S or 1S figures is enough to reposition Intel’s flagship CPU in the rankings by notable amounts, finally no longer lagging behind as drastically as some of the competition.
It’s definitely not sufficient to compete with AMD and Ampere, both showcasing figures that are still 25 and 15% ahead of the Xeon 8380.
The Xeon 6330 is falling in line with where we benchmarked it in previous tests, just slightly edging out the Xeon 8280 (6258R equivalent), meaning we’re seeing minor ISO-core ISO-power generational improvements (again I have to mention that the 6330 is half the price of a 6258R).
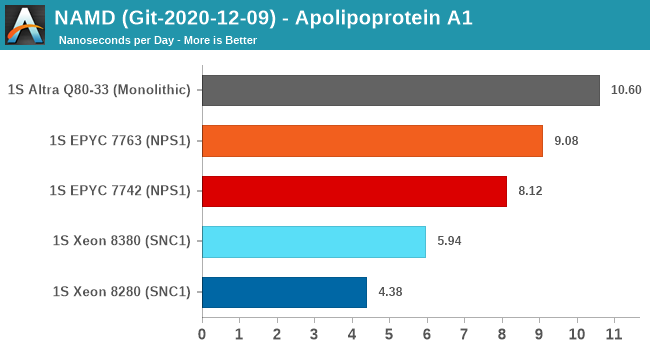
NAMD is a problem-child benchmark due to its recent addition of AVX512: the code had been contributed by Intel engineers – which isn’t exactly an issue in my view. The problem is that this is a new algorithm which has no relation to the normal code-path, which remains not as hand-optimised for AVX2, and further eyebrow raising is that it’s solely compatible with Intel’s ICC and no other compiler. That’s one level too much in terms of questionable status as a benchmark: are we benchmarking it as a general HPC-representative workload, or are we benchmarking it solely for the sake of NAMD and only NAMD performance?
We understand Intel is putting a lot of focus on these kinds of workloads that are hyper-optimised to run well extremely on Intel-only hardware, and it’s a valid optimisation path for many use-cases. I’m just questioning how representative it is of the wider market and workloads.
In any case, the GCC binaries of the test on the ApoA1 protein showcase significant performance uplifts for the Xeon 8380, showcasing a +35.6% gain. Using this apples-to-apples code path, it’s still quite behind the competition which scales the performance much higher thanks to more cores.








169 Comments
View All Comments
Oxford Guy - Sunday, April 11, 2021 - link
'The faulty logic I see is that you seem to believe it's the review's job to...''I think it could be appropriate to do that sort of thing, in articles that...'
Don't contradict yourself or anything.
If you're not interested in knowing how fast a CPU is that's ... well... I don't know.
Telling people to go for marketing info (which is inherently deceptive — the entire fundamental reason for marketing departments to exist) is obviously silly.
mode_13h - Monday, April 12, 2021 - link
> Don't contradict yourself or anything.I think the point of confusion is that I'm drawing a distinction between the initial product review and subsequent follow-up articles they often publish to examine specific points of interest. This would also allow for more time to do a more thorough investigation, since the initial reviews tend to be conducted under strict deadlines.
> If you're not interested in knowing how fast a CPU is that's ... well... I don't know.
There's often a distinction between the performance, as users are most likely to experience it, and the full capabilities of the product. I actually want to know both, but I think the former should be the (initial) priority.
ballsystemlord - Thursday, April 8, 2021 - link
Spelling and grammar errors (there are a lot!):"At the same time, we have also spent time a dual Xeon Gold 6330 system from Supermicro, which has two 28-core processors,..."
Nonsensical English: "time a duel". I haven't the faintest what you were trying to say.
"DRAM latencies here are reduced by 1.7ns, which isn't very much a significant difference,..."
Either use "very much", or use "a significant":
DRAM latencies here are reduced by 1.7ns, which isn't a very significant difference,..."
"Inspecting Intel's prior disclosures about Ice Lake SP in last year's HotChips presentations, one point sticks out, and that's is the "SpecI2M optimisation" where the system is able to convert traditional RFO (Read for ownership) memory operations into another mechanism"
Excess "is":
"Inspecting Intel's prior disclosures about Ice Lake SP in last year's HotChips presentations, one point sticks out, and that's the "SpecI2M optimisation" where the system is able to convert traditional RFO (Read for ownership) memory operations into another mechanism"
"It's a bit unfortunate that system vendors have ended up publishing STREAM results with hyper optimised binaries that are compiled with non-temporal instructions from the get-go, as for example we would not have seen this new mechanism on Ice Lake SP with them"
You need to rewrite the sentance or add more commas to break it up:
"It's a bit unfortunate that system vendors have ended up publishing STREAM results with hyper optimised binaries that are compiled with non-temporal instructions from the get-go, as, for example, we would not have seen this new mechanism on Ice Lake SP with them"
"The latter STREAM results were really great to see as I view is a true design innovation that will benefit a lot of workloads."
Exchange "is" for "this as":
"The latter STREAM results were really great to see as I view this as a true design innovation that will benefit a lot of workloads."
Or discard "view" and rewrite as a diffinitive instead of as an opinion:
"The latter STREAM results were really great to see as this is a true design innovation that will benefit a lot of workloads."
"Intel's new Ice Lake SP system, similarly to the predecessor Cascade Lake SP system, appear to be very efficient at full system idle,..."
Missing "s":
"Intel's new Ice Lake SP system, similarly to the predecessor Cascade Lake SP system, appears to be very efficient at full system idle,..."
"...the new Ice Lake part to most of the time beat the Cascade Lake part,..."
"to" doesn't belong. Rewrite:
"...the new Ice Lake part can beat the Cascade Lake part most of the time,..."
"...both showcasing figures that are still 25 and 15% ahead of the Xeon 8380."
Missing "%":
"...both showcasing figures that are still 25% and 15% ahead of the Xeon 8380."
"Intel had been pushing very hard the software optimisation side of things,..."
Poor sentance structure:
"Intel had been pushing the software optimisation side very hard,..."
"...which unfortunately didn't have enough time to cover for this piece."
Missing "we":
"...which unfortunately we didn't have enough time to cover for this piece."
"While we are exalted to finally see Ice lake SP reach the market,..."
"excited" not "exalted":
"While we are excited to finally see Ice lake SP reach the market,..."
Thanks for the article!
Oxford Guy - Sunday, April 11, 2021 - link
Perhaps Purch would be willing to take you on as a volunteer unpaid intern for proofreading for spelling and grammar?I would think there are people out there who would do it for resume building. So... if it bothers you perhaps you should make an inquiry.
evilpaul666 - Saturday, April 10, 2021 - link
Are the W-1300s going to use 10nm this year?mode_13h - Saturday, April 10, 2021 - link
You mean the bottom-tier Xeons? Those are just mainstream desktop chips with less features disabled, so that question depends on when Alder Lake hits.I'd say "no", because the Xeon versions typically lag the corresponding mainstream chips by a few months. So, if Alder Lake launches in November, then maybe we get the Xeons in February-March of next year.
The more immediate question is whether they'll release a Xeon version of Rocket Lake. I think that's likely, since they skipped Comet Lake and there are significant platform enhancements for Rocket Lake.
AdrianBc - Monday, April 12, 2021 - link
No, the W-1300 Xeons will be Rocket Lake. The top model will be Xeon W-1390P, which will be equivalent to the top i9 Rocket Lake, with 125 W TDP and 5.3 GHz maximum turbo.rahvin - Tuesday, April 20, 2021 - link
Andre does some of the best server reviews available, IMO.KKK11 - Tuesday, May 11, 2021 - link
That is a curious-looking wafer. I thought it was fake at first but then I noticed the alignment notch. Actually, I'm still not convinced it's real because I have seen lots and lots of wafers in various stages of production and I have never seen one where partial chips go all the way out to the edges. It's a waste of time to deal with those in the steppers so no one does that.