Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
by Andrei Frumusanu on April 6, 2021 11:00 AM EST- Posted in
- Servers
- CPUs
- Intel
- Xeon
- Enterprise
- Xeon Scalable
- Ice Lake-SP
Compiling LLVM, NAMD Performance
As we’re trying to rebuild our server test suite piece by piece – and there’s still a lot of work go ahead to get a good representative “real world” set of workloads, one more highly desired benchmark amongst readers was a more realistic compilation suite. Chrome and LLVM codebases being the most requested, I landed on LLVM as it’s fairly easy to set up and straightforward.
git clone https://github.com/llvm/llvm-project.gitcd llvm-projectgit checkout release/11.xmkdir ./buildcd ..mkdir llvm-project-tmpfssudo mount -t tmpfs -o size=10G,mode=1777 tmpfs ./llvm-project-tmpfscp -r llvm-project/* llvm-project-tmpfscd ./llvm-project-tmpfs/buildcmake -G Ninja \ -DLLVM_ENABLE_PROJECTS="clang;libcxx;libcxxabi;lldb;compiler-rt;lld" \ -DCMAKE_BUILD_TYPE=Release ../llvmtime cmake --build .We’re using the LLVM 11.0.0 release as the build target version, and we’re compiling Clang, libc++abi, LLDB, Compiler-RT and LLD using GCC 10.2 (self-compiled). To avoid any concerns about I/O we’re building things on a ramdisk. We’re measuring the actual build time and don’t include the configuration phase as usually in the real world that doesn’t happen repeatedly.
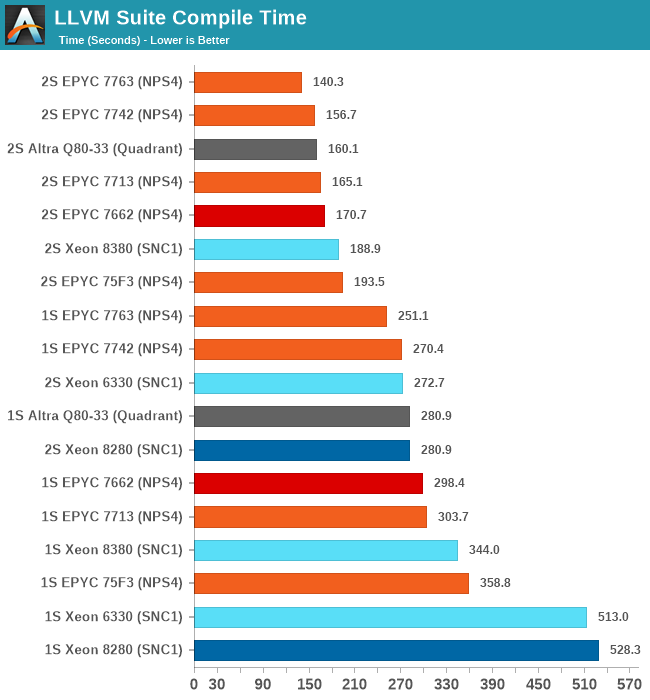
Starting off with the Xeon 8380, we’re looking at large generational improvements for the new Ice Lake SP chip. A 33-35% improvement in compile time depending on whether we’re looking at 2S or 1S figures is enough to reposition Intel’s flagship CPU in the rankings by notable amounts, finally no longer lagging behind as drastically as some of the competition.
It’s definitely not sufficient to compete with AMD and Ampere, both showcasing figures that are still 25 and 15% ahead of the Xeon 8380.
The Xeon 6330 is falling in line with where we benchmarked it in previous tests, just slightly edging out the Xeon 8280 (6258R equivalent), meaning we’re seeing minor ISO-core ISO-power generational improvements (again I have to mention that the 6330 is half the price of a 6258R).
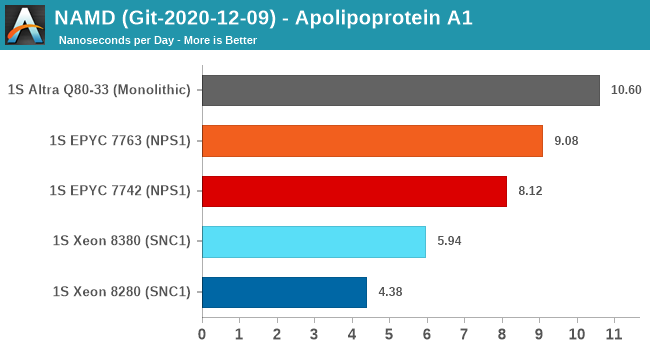
NAMD is a problem-child benchmark due to its recent addition of AVX512: the code had been contributed by Intel engineers – which isn’t exactly an issue in my view. The problem is that this is a new algorithm which has no relation to the normal code-path, which remains not as hand-optimised for AVX2, and further eyebrow raising is that it’s solely compatible with Intel’s ICC and no other compiler. That’s one level too much in terms of questionable status as a benchmark: are we benchmarking it as a general HPC-representative workload, or are we benchmarking it solely for the sake of NAMD and only NAMD performance?
We understand Intel is putting a lot of focus on these kinds of workloads that are hyper-optimised to run well extremely on Intel-only hardware, and it’s a valid optimisation path for many use-cases. I’m just questioning how representative it is of the wider market and workloads.
In any case, the GCC binaries of the test on the ApoA1 protein showcase significant performance uplifts for the Xeon 8380, showcasing a +35.6% gain. Using this apples-to-apples code path, it’s still quite behind the competition which scales the performance much higher thanks to more cores.








169 Comments
View All Comments
Oxford Guy - Tuesday, April 6, 2021 - link
Reading the conclusion I’m confused by how it’s possible for the product to be a success and for it to be both slower and more expensive.‘But Intel has 10nm in a place where it is economically viable’
Is that the full-fat 10nm or a simplified/weaker version? I can’t remember but vaguely recall something about Intel having had to back away from some of the tech improvements it had said would be in its 10nm.
Yojimbo - Tuesday, April 6, 2021 - link
Because there is more than the benchmarks that are in this review to making decisions when buying servers. Intel's entire ecosystem is an advantage much bigger than AMD's lead in benchmarks, as is Intel's ability to deliver high volume. The product will be a success because it will sell a lot of hardware. It will, however, allow a certain amount of market share to be lost to AMD, but less thanwpuld be lost without it. It will also cut into profit margins compared to if the Intel chips were even with the AMD ones in the benchmarks, or if Intel's 10 nm was as cost effective as they'd like it to be (but TSMC's 7 nm is not as cost effect as Intel would like they're processes to be, either).RanFodar - Tuesday, April 6, 2021 - link
This.Oxford Guy - Wednesday, April 7, 2021 - link
So, the argument here is that the article should have been all that instead of focusing on benchmarks.Yojimbo - Friday, April 9, 2021 - link
I never made any argument or made any suggestions for the article, I only tried to clear up your confusion: "Reading the conclusion I’m confused by how it’s possible for the product to be a success and for it to be both slower and more expensive." Perhaps the author should have been more explicit as to why he made his conclusion. To me, the publishing of server processor benchmarks on a hardware enthusiast site like this is mostly for entertainment purposes, although it might influence some retail investors. They are just trying to pit the processor itself against its competitors. "How does Intel's server chip stack up against AMD's server chip?" It's like watching the ball game at the bar.mode_13h - Saturday, April 10, 2021 - link
> To me, the publishing of server processor benchmarks on a hardware enthusiast site like this is mostly for entertainment purposes, although it might influence some retail investors.You might be surprised. I'm a software developer at a hardware company and we use benchmarks on sites like this to give us a sense of the hardware landscape. Of course, we do our own, internal testing, with our own software, before making any final decisions.
I'd guess that you'll find systems admins of SMEs that still use on-prem server hardware are probably also looking at reviews like these.
Oxford Guy - Sunday, April 11, 2021 - link
It's impossible to post a rebuttal (i.e. 'clear up your confusion') without making one or more arguments.I rebutted your rebuttal.
You argued against the benchmarks being seen as important. I pointed out that that means the article shouldn't have been pages of benchmarks. You had nothing.
trivik12 - Tuesday, April 6, 2021 - link
I wish there were test done with 2nd gen Optane memory. isn't that one of the selling point of Intel Xeon that is not there in Epyc or Arm Servers. Also please do benchmarks with P5800X optane SSD as that is supposedly fastest SSD around.Frank_M - Thursday, April 8, 2021 - link
Optane and Thunderbolt.Azix - Tuesday, April 6, 2021 - link
There's a reason intel's data center revenues are still massive compared to AMDs. These will sell in large quantities because AMD can't supply.