Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
by Andrei Frumusanu on April 6, 2021 11:00 AM EST- Posted in
- Servers
- CPUs
- Intel
- Xeon
- Enterprise
- Xeon Scalable
- Ice Lake-SP
Conclusion & End Remarks
Today’s launch of the new 3rd gen Xeon Scalable processors is a major step forward for Intel and the company’s roadmap. Ice Lake SP had been baking in the oven for a very long time: originally planned for a 2020 release, Intel had only started production recently this January, so finally seeing the chips in silicon and in hand has been a relief.
Generationally Impressive
Technically, Ice Lake SP is an impressive and major generation leap for Intel’s enterprise line-up. Manufactured on a new 10nm process, node, employing a new core microarchitecture, faster memory with more memory channels, PCIe 4.0, new accelerator capabilities and VNNI instructions, security improvements – these are all just the tip of the iceberg that Ice Lake SP brings to the table.
In terms of generational performance uplifts, we saw some major progress today with the new Xeon 8380. With 40 cores at a higher TDP of 270W, the new flagship chip is a veritable beast with large increases in performance in almost all workloads. Major architectural improvements such as the new memory bandwidth optimisations are amongst what I found to be most impressive for the new parts, showcasing that Intel still has a few tricks up its sleeve in terms of design.
This being the first super-large 10nm chip design from Intel, the question of how efficiency would end up was a big question to the whole puzzle to the new generation line-up. On the Xeon 8380, a 40-core part at 270W, we saw a +18% increase in performance / W compared to the 28-core 205W Xeon 8280. This grew to a +36% perf/W advantage when limiting the ICX part to 205 as well. On the other hand, our mid-stack Xeon 6330 sample showed very little advantages to the Xeon 8280, even both are 28-core 205W designs. Due to the mix of good and bad results here, it seems we’ll have to delay a definitive verdict on the process node improvements to the future until we can get more SKUs, as the current variations are quite large.
Per-core performance, as well as single-thread performance of the new parts don’t quite achieve what I imagine Intel would have hoped through just the IPC gains of the design. The IPC gains are there and they’re notable, however the new parts also lose out on frequency, meaning the actual performance doesn’t move too much, although we did see smaller increases. Interestingly enough, this is roughly the same conclusion we came to when we tested Intel's Ice Lake notebook platform back in August 2019.

The Competitive Hurdle Still Stands
As impressive as the new Xeon 8380 is from a generational and technical stand-point, what really matters at the end of the day is how it fares up to the competition. I’ll be blunt here; nobody really expected the new ICL-SP parts to beat AMD or the new Arm competition – and it didn’t. The competitive gap had been so gigantic, with silly scenarios such as where competing 1-socket systems would outperform Intel’s 2-socket solutions. Ice Lake SP gets rid of those more embarrassing situations, and narrows the performance gap significantly, however the gap still remains, and is still undeniable.
We’ve only had access limited to the flagship Xeon 8380 and the mid-stack Xeon 6330 for the review today, however in a competitive landscape, both those chips lose out in both absolute performance as well as price/performance compared to AMD’s line-up.
Intel had been pushing very hard the software optimisation side of things, trying to differentiate themselves as well as novel technologies such as PMem (Optane DC persistent memory, essentially Optane memory modules), which unfortunately didn’t have enough time to cover for this piece. Indeed, we saw a larger focus on “whole system solutions” which take advantage of Intel’s broader product portfolio strengths in the enterprise market. The push for the new accelerator technologies means Intel needs to be working closely with partners and optimising public codebases to take advantage of these non-standard solutions, which might be a hurdle for deployments such as cloud services where interoperability might be important. While the theoretical gains can be large, anyone rolling a custom local software stack might see a limited benefit however, unless they are already experts with Intel's accelerator portfolio.
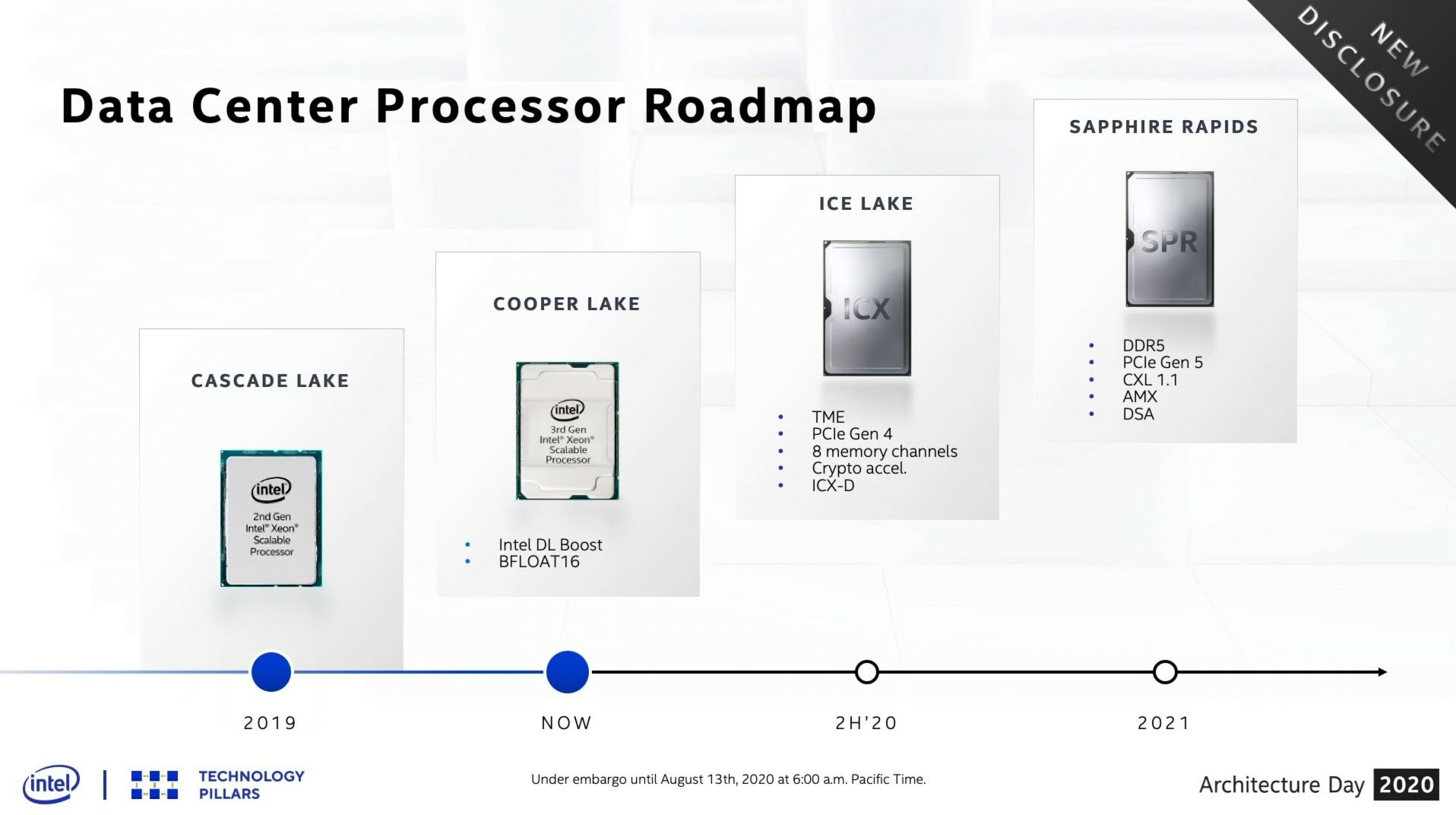
There’s also the looming Intel roadmap. While we are exulted to finally see Ice lake SP reach the market, Intel is promising the upcoming Sapphire Rapids chips for later this year, on a new platform with DDR5 and PCIe 5. Intel is set to have Ice Lake Xeon and Sapphire Rapids Xeon in the market concurrently, with the idea to manage both, especially for customers that apply the leading edge hardware as soon as it is available. It will be interesting to see the scale of the roll out of Ice Lake with this in mind.
At the end of the day, Ice Lake SP is a success. Performance is up, and performance per watt is up. I'm sure if we were able to test Intel's acceleration enhancements more thoroughly, we would be able to corroborate some of the results and hype that Intel wants to generate around its product. But even as a success, it’s not a traditional competitive success. The generational improvements are there and they are large, and as long as Intel is the market share leader, this should translate into upgraded systems and deployments throughout the enterprise industry. Intel is still in a tough competitive situation overall with the high quality the rest of the market is enabling.








169 Comments
View All Comments
Oxford Guy - Wednesday, April 7, 2021 - link
You're arguing apples (latency) and oranges (capability).An Apple II has better latency than an Apple Lisa, even though the latter is vastly more powerful in most respects. The sluggishness of the UI was one of the big problems with that system from a consumer point of view. Many self-described power users equated a snappy interface with capability, so they believed their CLI machines (like the IBM PC) were a lot better.
GeoffreyA - Wednesday, April 7, 2021 - link
"today's software and OSes are absurdly slow, and in many cases desktop applications are slower in user-time than their late 1980s counterparts"Oh yes. One builds a computer nowadays and it's fast for a year. But then applications, being updated, grow sluggish over time. And it starts to feel like one's old computer again. So what exactly did we gain, I sometimes wonder. Take a simple suite like LibreOffice, which was never fast to begin with. I feel version 7 opens even slower than 6. Firefox was quite all right, but as of 85 or 86, when they introduced some new security feature, it seems to open a lot slower, at least on my computer. At any rate, I do appreciate all the free software.
ricebunny - Wednesday, April 7, 2021 - link
Well said.Frank_M - Thursday, April 8, 2021 - link
Intel Fortran is vastly faster then GCC.How did ricebunny get a free compiler?
mode_13h - Thursday, April 8, 2021 - link
> It's strange to tell people who use the Intel compiler that it's not used much in the real world, as though that carries some substantive point.To use the automotive analogy, it's as if a car is being reviewed using 100-octane fuel, even though most people can only get 93 or 91 octane (and many will just use the cheap 87 octane, anyhow).
The point of these reviews isn't to milk the most performance from the product that's theoretically possible, but rather to inform readers about how they're likely to experience it. THAT is why it's relevant that almost nobody uses ICC in practice.
And, in fact, BECAUSE so few people are using ICC, Intel puts a lot of work into GCC and LLVM.
GeoffreyA - Thursday, April 8, 2021 - link
I think that a common compiler like GCC should be used (like Andrei is doing), along with a generic x86-64 -march (in the case of Intel/AMD) and generic -mtune. The idea would be to get the CPUs on as equal a footing as possible, even with code that might not be optimal, and reveal relative rather than absolute performance.Wilco1 - Thursday, April 8, 2021 - link
Using generic (-march=x86-64) means you are building for ancient SSE2... If you want a common baseline then use something like -march=x86-64-v3. You'll then get people claiming that excluding AVX-512 is unfair eventhough there is little difference on most benchmarks except for higher power consumption ( https://www.phoronix.com/scan.php?page=article&... ).GeoffreyA - Saturday, April 10, 2021 - link
I think leaving AVX512 out is a good policy.GeoffreyA - Thursday, April 8, 2021 - link
If I may offer an analogy, I would say: the benchmark is like an exam in school but here we test time to finish the paper (and with the constraint of complete accuracy). Each pupil should be given the identical paper, and that's it.Using optimised binaries for different CPUs is a bit like knowing each child's brain beforehand (one has thicker circuitry in Bodman region 10, etc.) and giving each a paper with peculiar layout and formatting but same questions (in essence). Which system is better, who can say, but I'd go with the first.
Oxford Guy - Wednesday, April 7, 2021 - link
Well, whatever tricks were used made Blender faster with the ICC builds I tested — both on AMD's Piledriver and on several Intel releases (Lynnfield and Haswell).