Apple Announces The Apple Silicon M1: Ditching x86 - What to Expect, Based on A14
by Andrei Frumusanu on November 10, 2020 3:00 PM EST- Posted in
- Apple
- Apple A14
- Apple Silicon
- Apple M1
Dominating Mobile Performance
Before we dig deeper into the x86 vs Apple Silicon debate, it would be useful to look into more detail how the A14 Firestorm cores have improved upon the A13 Lightning cores, as well as detail the power and power efficiency improvements of the new chip’s 5nm process node.
The process node is actually quite the wildcard in the comparisons here as the A14 is the first 5nm chipset on the market, closely followed by Huawei’s Kirin 9000 in the Mate 40 series. We happen to have both devices and chips in house for testing, and contrasting the Kirin 9000 (Cortex-A77 3.13GHz on N5) vs the Snapdragon 865+ (Cortex-A77 3.09GHz on N7P) we can somewhat deduct how much of an impact the process node has in terms of power and efficiency, translating those improvements to the A13 vs A14 comparison.

Starting off with SPECint2006, we don’t see anything very unusual about the A14 scores, save the great improvement in 456.hmmer. Actually, this wasn’t due to a microarchitectural jump, but rather due to new optimisations on the part of the new LLVM version in Xcode 12. It seems here that the compiler has employed a similar loop optimisation as found on GCC8 onwards. The A13 score actually had improved from 47.79 to 64.87, but I hadn’t run new numbers on the whole suite yet.
For the rest of the workloads, the A14 generally looks like a relatively linear progression from the A13 in terms of progression, accounting for the clock frequency increase from 2.66GHz to 3GHz. The overall IPC gains for the suite look to be around 5% which is a bit less than Apple’s prior generations, though with a larger than usual clock speed increase.
Power consumption for the new chip is actually in line, and sometimes even better than the A13, which means that workload energy efficiency this generation has seen a noticeable improvement even at the peak performance point.
Performance against the contemporary Android and Cortex-core powered SoCs looks to be quite lopsided in favour of Apple. The one thing that stands out the most are the memory-intensive, sparse memory characterised workloads such as 429.mcf and 471.omnetpp where the Apple design features well over twice the performance, even though all the chip is running similar mobile-grade LPDDR4X/LPDDR5 memory. In our microarchitectural investigations we’ve seen signs of “memory magic” on Apple’s designs, where we might believe they’re using some sort of pointer-chase prefetching mechanism.
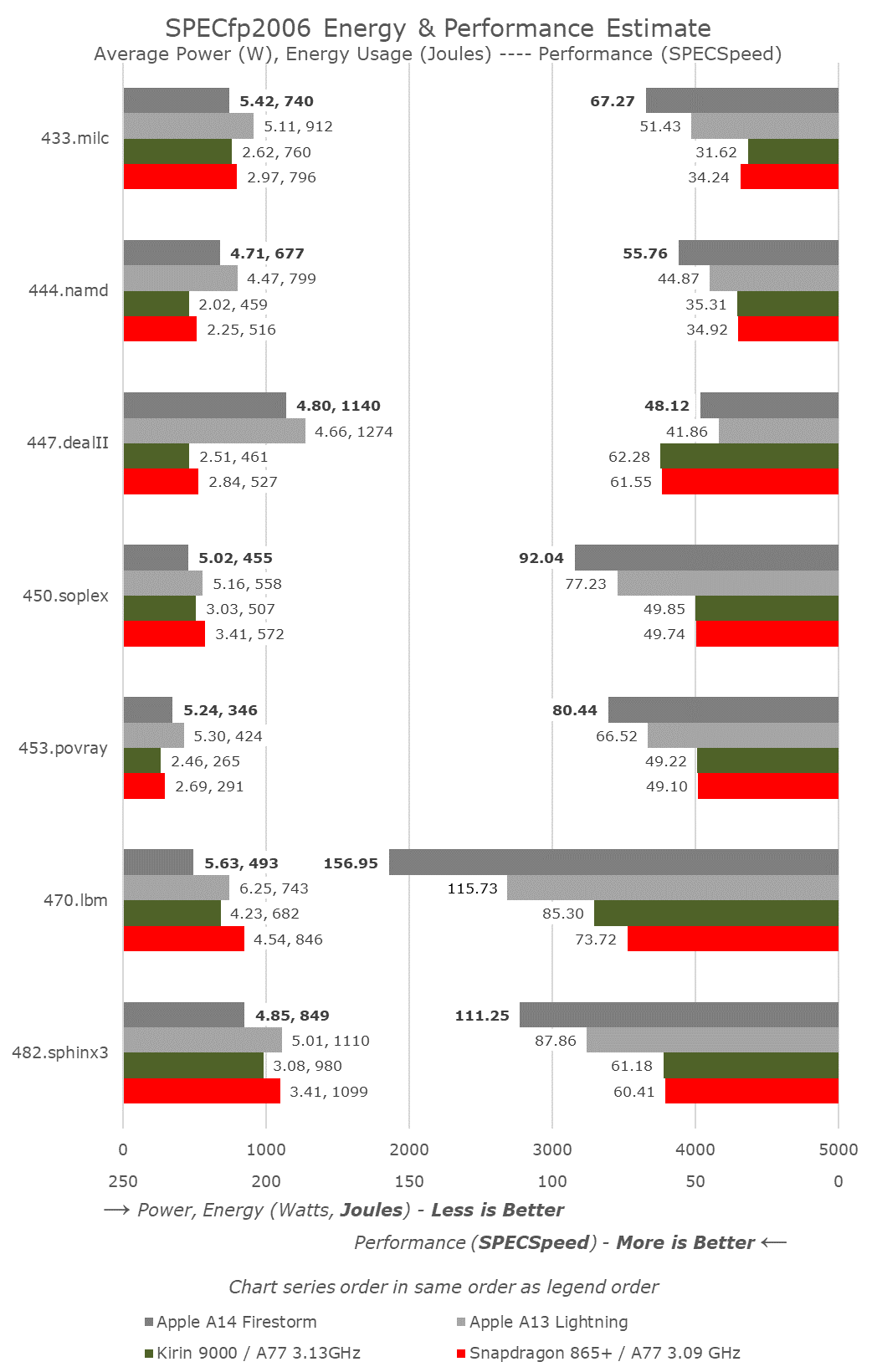
In SPECfp, the increases of the A14 over the A13 are a little higher than the linear clock frequency increase, as we’re measuring an overall 10-11% IPC uplift here. This isn’t too surprising given the additional fourth FP/SIMD pipeline of the design, whereas the integer side of the core has remained relatively unchanged compared to the A13.
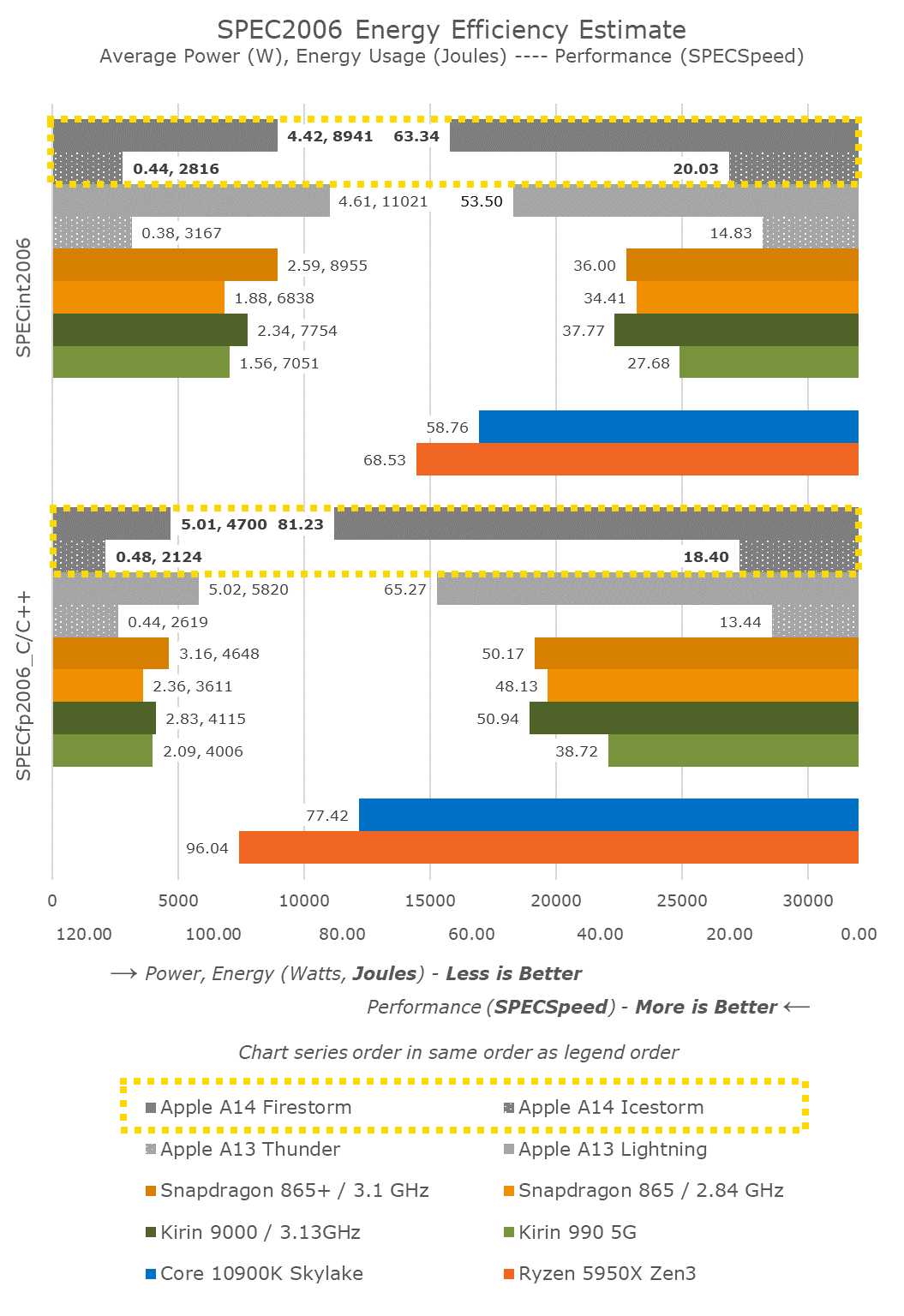
In the overall mobile comparison, we can see that the new A14 has made robust progress in terms of increasing performance over the A13. Compared to the competition, Apple is well ahead of the pack – we’ll have to wait for next year’s Cortex-X1 devices to see the gap narrow again.
What’s also very important to note here is that Apple has achieved this all whilst remaining flat, or even lowering the power consumption of the new chip, notably reducing energy consumption for the same workloads.
Looking at the Kirin 9000 vs the Snapdragon 865+, we’re seeing a 10% reduction in power at relatively similar performance. Both chips use the same CPU IP, only differing in their process node and implementations. It seems Apple’s A14 here has been able to achieve better figures than just the process node improvement, which is expected given that it’s a new microarchitecture design as well.
One further note is the data of the A14’s small efficiency cores. This generation we saw a large microarchitectural boost on the part of these new cores which are now seeing 35% better performance versus last year’s A13 efficiency cores – all while further reducing energy consumption. I don’t know how the small cores will come into play on Apple’s “Apple Silicon” Mac designs, but they’re certainly still very performant and extremely efficient compared to other current contemporary Arm designs.
Lastly, there’s the x86 vs Apple performance comparison. Usually for iPhone reviews I comment on this in this section of the article, but given today’s context and the goals Apple has made for Apple Silicon, let’s investigate that into a whole dedicated section…








644 Comments
View All Comments
hecksagon - Tuesday, November 10, 2020 - link
There is also the issue of the benchmarks not being long enough to cause any significant throttling. This is the reason Apple mobile devices are so strong in this benchmark. Their CPUs provide very strong peak performance that slows down as the device gets heat soaked. That's why it looks like an iPhone can compete with a i7 laptop according to this benchmark.misan - Wednesday, November 11, 2020 - link
Apple delivers performance comparable to that of best 5.0 ghz x86 chips while running at 3 ghz and drawing under 5 watts. You argument does not make any sense logically. Ys, there will be throttling — but at the same cooling performance and consuming the same power Apple chips will always be faster. In fact, their lead on x86 chips will increase when the CPUs are throttled, since Intel will need to drop the clocks significantly — Apple doesn't.hecksagon - Tuesday, November 10, 2020 - link
No he is saying that Geekbench weight on cache bound workloads to no represent reality.techconc - Wednesday, November 11, 2020 - link
GB5 scores are inline with Spec results, so there is no merit to the claim that they don't match reality.chlamchowder - Wednesday, November 11, 2020 - link
The large lsq/other ooo resource queues and high MLP numbers are there to cover for the very slow L3 cache. With 39ns latency on A13 and similar looking figures here, you're looking at over 100 cycles to get to L3. That's worse than Bulldozer's L3, which was considered pretty bad.name99 - Wednesday, November 11, 2020 - link
Why not try to *understand* Apple's architecture rather than concentrating on criticism?(a) Apple's design is *their* design, it is not a copy of AMD or Intel's design
(b) Apple's design is optimized for the SoC as a whole, not just the CPU.
The L3 on Apple SoC's does not fulfill the role of a traditional L3, that is why Apple calls it an SLC (System Level Cache). For traditional CPU caching, Apple has a large L2 (8MiB A14, 12MiB M1).
The role of the L3 is PRIMARILY
- to save power (everything, especially on the GPU side, that can be kept there rather than in DRAM is a power advantage)
- to communicate between different elements of the SoC.
The fact that the SLC can act as a large (slow, but still faster than DRAM) L3 is just a bonus, it is not the design target.
Why did Apple keep pushing the UMA theme at their event? The stupid think it's Apple claiming that they are first with UMA; but Apple never said that. The point is that UMA is part of what enables Apple's massive cross-SoC accelerator interaction; while the SLC is what makes that interaction fast and low power. How many accelerators do you think are on the A14/M1? We don't know -- what we do know is that there are 42 on the A12.
42 accelerators! Did you have a clue that it was anything close to that?
Sure, you know the big picture, things like ISP, GPU and NPU working together for computational photography, but there is so much more. And they can all interact together and efficiently via SLC.
https://arxiv.org/pdf/1907.02064v1.pdf
discusses all this, along with pointing out just how important it is to have fast low energy communication between the accelerators.
techconc - Wednesday, November 11, 2020 - link
Why are we still arguing about the validity of Geekbench? The article even states the following from their own testing..."There’s been a lot of criticism about more common benchmark suites such as GeekBench, but frankly I've found these concerns or arguments to be quite unfounded."
BlackHat - Wednesday, November 11, 2020 - link
Because the creator of the benchmark themselves admitted that their old version were somehow inaccurate.Spunjji - Thursday, November 12, 2020 - link
Just as well we're not really discussing those here, then 😬hecksagon - Tuesday, November 10, 2020 - link
Too bad the links are all for Geekbench. This is about as far from a real world benchmark you can get.