Imagination Announces B-Series GPU IP: Scaling up with Multi-GPU
by Andrei Frumusanu on October 13, 2020 4:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- SoCs
- IP
Introducing IMGIC - A better frame-buffer compression
Besides the multi-GPU scalability, another big feature introduction to the B-Series is the addition of a completely new image compression algorithm, simply dubbed IMGIC, or Imagination Image Compression.
Compression is an integral part of modern GPUs as otherwise the designs would simply be memory bandwidth starved. To date, Imagination has been using PVRIC to achieve this. The problem with PVRIC was that it was a relatively uncompetitive compression format, falling behind in data compression ratio compared to other competitor techniques such as Arm’s AFBC (Arm Frame-Buffer Compression). This resulted in IMG GPUs using up more bandwidth than a comparable Arm GPU.


IMGIC is a completely new and redesigned compression algorithm that replaces PVRIC. Imagination touts this as the most advanced image compression technology, offering extreme bandwidth savings and a lot more flexibility compared to previous PVRIC designs. Amongst the flexibility aspect of things, IMGIC can now work on individual pixels instead of just smaller tiles or pixel groups.
Furthermore, the new algorithm is said to be 8x simpler than PVRIC, meaning the hardware implementation is also much simplified and achieves a significant are area reduction.
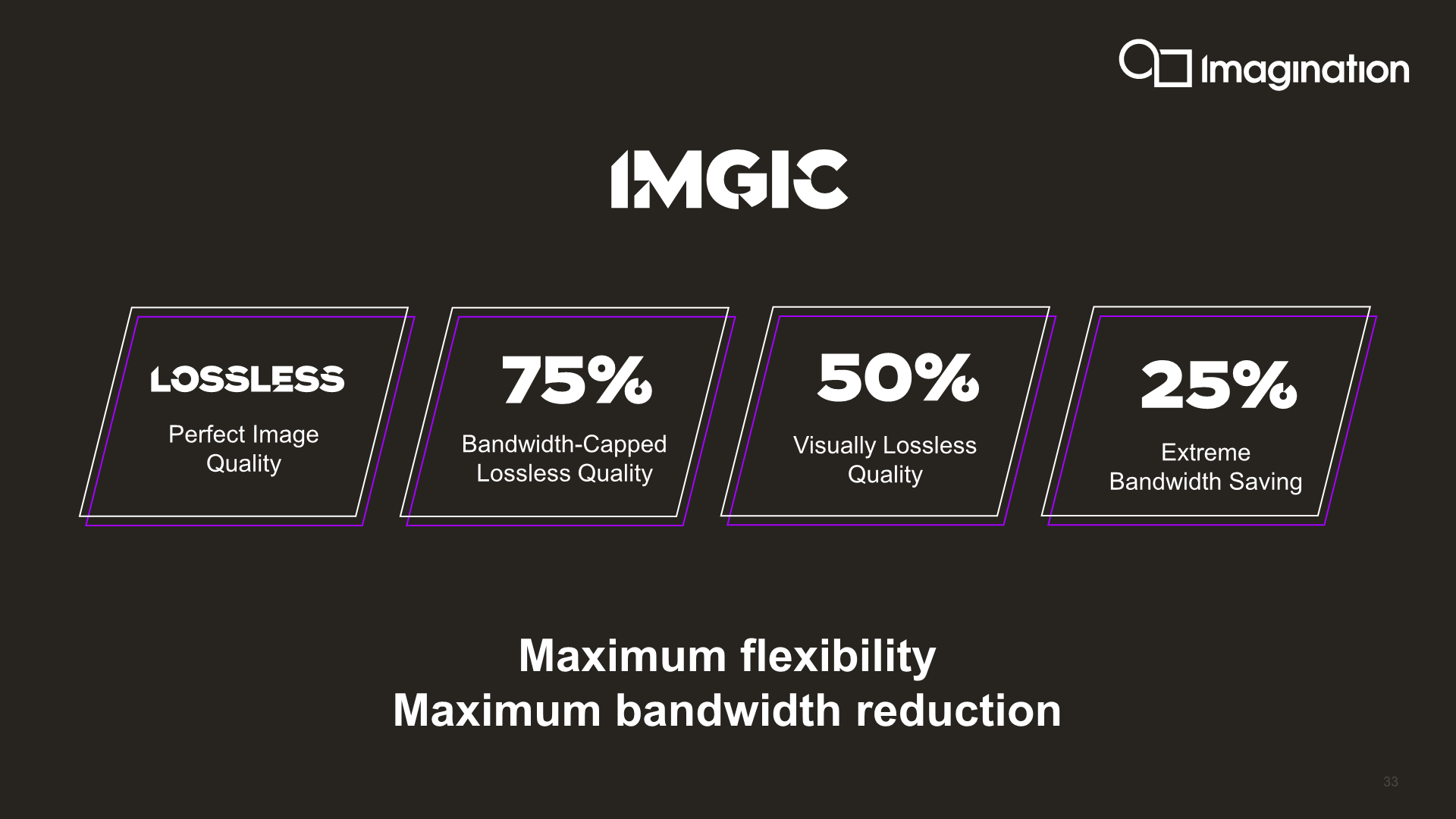
The new implementation gives vendors more scaling options, adding compression ratios down to a lossy 25% for extreme bandwidth savings. SoC vendors can use this to alleviate bandwidth starved scenarios or QoS scenarios where other IPs on the SoC should take priority.

Overall, the B-Series now offers a 35% reduction in bandwidth compared to the A-Series and previous generation Imagination GPU architectures, which is a rather large improvement given that memory bandwidth is a costly matter, both in terms of actual silicon cost as well as energy usage.








74 Comments
View All Comments
Yojimbo - Tuesday, October 13, 2020 - link
I didn't know Xi JinPing was an engineer...EthiaW - Wednesday, October 14, 2020 - link
Those chinese have only managed to outcast the former corporate leaders recently. The shift from engeneer culture will take time, if not reverted by the UK government.Yojimbo - Wednesday, October 14, 2020 - link
They had the stubbornness to not be bought by Apple in order to be bought by the Chinese government. And through what will or method is the UK government going to change the culture of the company?Yojimbo - Tuesday, October 13, 2020 - link
Hey, you're right. He studied chemical engineering. I knew that, but forgot.melgross - Tuesday, October 13, 2020 - link
With Apple being 60% of their sales, and 80% of their profits, they demanded $1 billion from Apple, which refused that ridiculous price.The company is likely worth no more than $100 million, if that, considering their sales are now just about $20 million a year.
colinisation - Tuesday, October 13, 2020 - link
Well if not Apple why not ARM, I know ARM tried to buy them at some point in the past.But once Apple left their valuation would have taken a pretty substantial hit and ARM's GPU IP is successful but I don't think it is the most Area/Power efficient so it looked to me to be something they would have explored both would have been in the same country, maybe it would have spurred ARM into providing a more viable alternative to Qualcomm in the smartphone GPU space.
CiccioB - Tuesday, October 13, 2020 - link
"Whereas current monolithic GPU designs have trouble being broken up into chiplets in the same way CPUs can be, Imagination’s decentralised multi-GPU approach would have no issues in being implemented across multiple chiplets, and still appear as a single GPU to software."There's not problem in splitting today desktop monolithic GPUs into chiplets.
What is done here is to create small chiplets that have all the needed pieces as a monolithic one. The main one is the memory controller.
Splitting a GPU over chiplets all having their own MC is technically simple but makes a mess when trying to use them due to the NUMA configuration. Being connected with a slow bus makes data sharing between chiplets almost impossible and so needs the programmer/driver to split the needed data over the single chiplet memory space and not make algorithms that share data between them.
The real problem with MCM configuration is data sharing = bandwidth.
You have to allow for data to flow from one core to another independently of its physical location on which chiplet it is. That's the only way you can obtain really efficient MCM GPUs.
And that requires high power+wide buses and complex data management with most probably very big caches (= silicon and power again) to mask memory latency and natural bandwidth restriction as it is impossible to have buses as fast as actual ones that connect 1TB/s to a GPU for each chiplet.
As you can see to make their GPUs work in parallel in HCP market Nvidia made a very fast point-to-point connection and created very fast switches to connect them together.
hehatemeXX - Tuesday, October 13, 2020 - link
That's why Infinity Cache is big. The bandwidth limitation is removed.Yojimbo - Tuesday, October 13, 2020 - link
Anything Infinity is big, except compared to a bigger Infinity.CiccioB - Tuesday, October 13, 2020 - link
It is removed just for the size of the cache.If you need more than that amount of data you'll still be limited to bandwidth limitation.
With the big cache latency now added.
If it were so easy to reduce the bandwidth limitations anyone would just add a big enough cache... the fact is that there's no a big enough cache for the immense quantity of data GPUs work with, unless you want all your VRAM as a cache (but then you won't be connected with such a limited bus).