Intel Launches Cooper Lake: 3rd Generation Xeon Scalable for 4P/8P Servers
by Dr. Ian Cutress on June 18, 2020 9:00 AM EST
We’ve known about Intel’s Cooper Lake platform for a number of quarters. What was initially planned, as far as we understand, as a custom silicon variant of Cascade Lake for its high-profile customers, it was subsequently productized and aimed to be inserted into a delay in Intel’s roadmap caused by the development of 10nm for Xeon. Set to be a full range update to the product stack, in the last quarter, Intel declared that its Cooper Lake platform would end up solely in the hands of its priority customers, only as a quad-socket or higher platform. Today, Intel launches Cooper Lake, and confirms that Ice Lake is set to come out later this year, aimed at the 1P/2P markets.
Count Your Coopers: BFloat16 Support
Cooper Lake Xeon Scalable is officially designated as Intel’s 3rd Generation of Xeon Scalable for high-socket count servers. Ice Lake Xeon Scalable, when it launches later this year, will also be called 3rd Generation of Xeon Scalable, except for low core count servers.
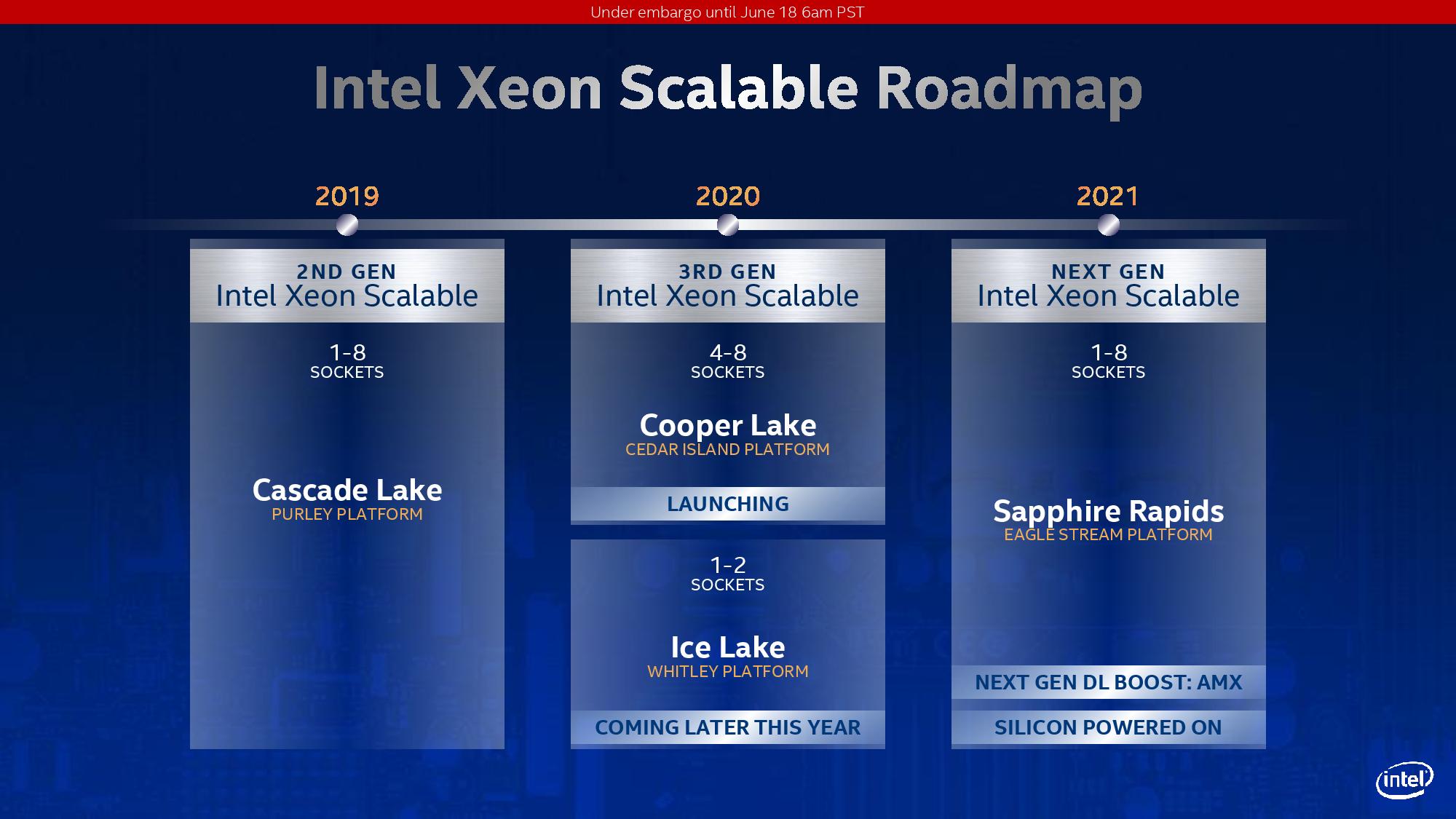
For Cooper Lake, Intel has made three key additions to the platform. First is the addition of AVX512-based BF16 instructions, allowing users to take advantage of the BF16 number format. A number of key AI workloads, typically done in FP32 or FP16, can now be performed in BF16 to get almost the same throughput as FP16 for almost the same range of FP32. Facebook made a big deal about BF16 in its presentation last year at Hot Chips, where it forms a critical part of its Zion platform. At the time the presentation was made, there was no CPU on the market that supported BF16, which led to this amusing exchange at the conference:
BF16 (bfloat16) is a way of encoding a number in binary that attempts to take advantage of the range of a 32-bit number, but in a 16-bit format such that double the compute can be packed into the same number of bits. The simple table looks a bit like this:
| Data Type Representations | ||||||
| Type | Bits | Exponent | Fraction | Precision | Range | Speed |
| float32 | 32 | 8 | 23 | High | High | Slow |
| float16 | 16 | 5 | 10 | Low | Low | 2x Fast |
| bfloat16 | 16 | 8 | 7 | Lower | High | 2x Fast |
By using BF16 numbers rather than FP32 numbers, it would also mean that memory bandwidth requirements as well as system-to-system network requirements could be halved. On the scale of a Facebook, or an Amazon, or a Tencent, this would appeal to them. At the time of the presentation at Hot Chips last year, Facebook confirmed that it already had silicon working on its datasets.
Doubling Socket-to-Socket Interconnect Bandwidth
The second upgrade that Intel has made to Cooper Lake over Cascade Lake is in socket-to-socket interconnect. Traditionally Intel’s Xeon processors have relied on a form of QPI/UPI (Ultra Path Interconnect) in order to connect multiple CPUs together to act as one system. In Cascade Lake Xeon Scalable, the top end processors each had three UPI links running at 10.4 GT/s. For Cooper Lake, we have six UPI links also running at 10.4 GT/s, however these links still only have three controllers behind them such that each CPU can only connect to three other CPUs, but the bandwidth can be doubled.
This means that in Cooper Lake, each CPU-to-CPU connection involves two UPI links, each running at 10.4 GT/s, for a total of 20.8 GT/s. Because the number of links is doubled, rather than an evolution of the standard, there are no power efficiency improvements beyond anything Intel has done to the manufacturing process. Note that double the bandwidth between sockets is still a good thing, even if latency and power per bit is still the same.
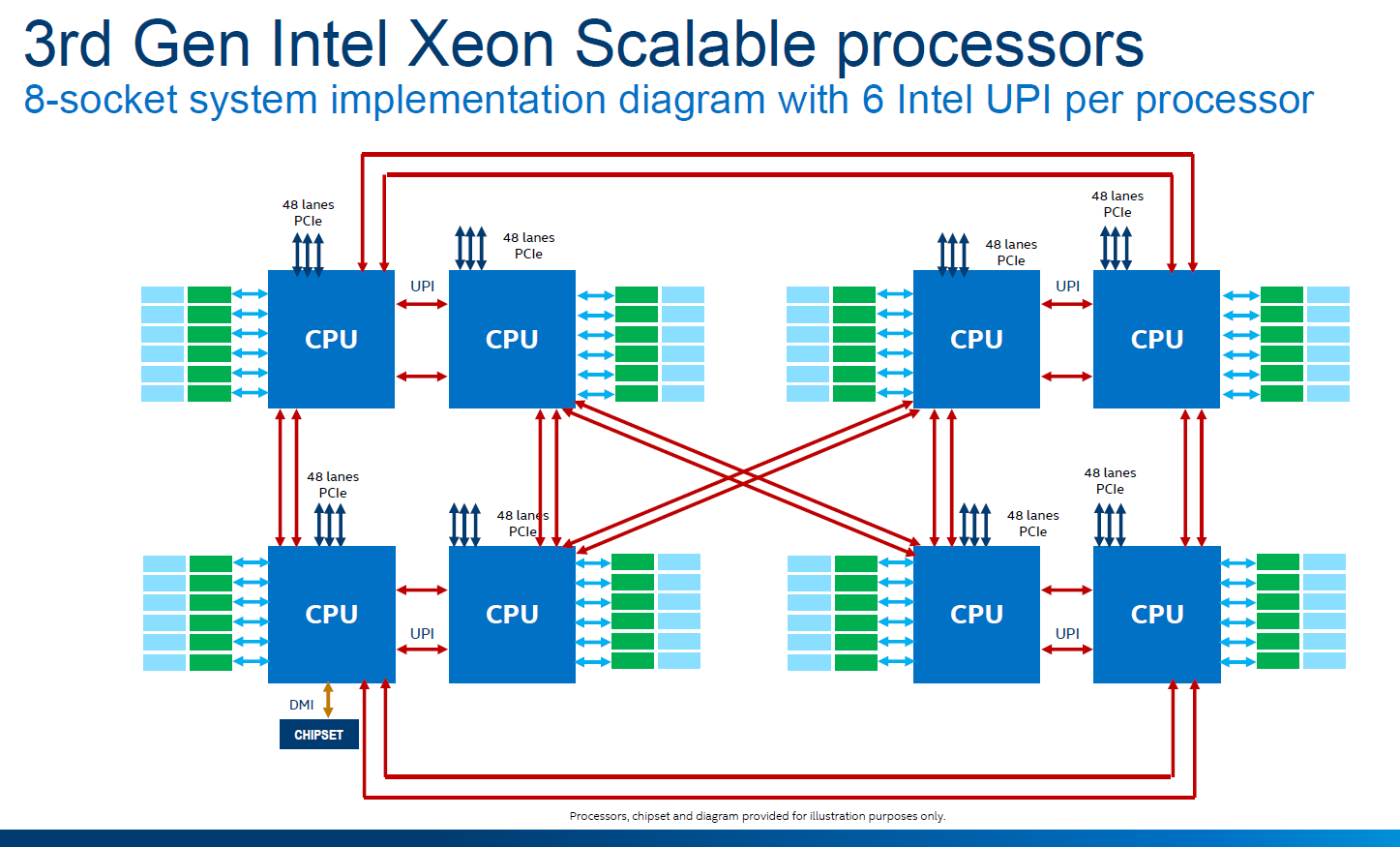
Intel still uses the double pinwheel topology for its eight socket designs, ensuring at max two hops to any required processor in the set. Eight socket is the limit with a glueless network – we have already seen companies like Microsoft build servers with 32 sockets using additional glue logic.
Memory and 2nd Gen Optane
The third upgrade for Cooper Lake is the memory support. Intel is now supporting DDR4-3200 with the Cooper Xeon Platinum parts, however only in a 1 DIMM per channel (1 DPC) scenario. 2 DPC is supported, but only at DDR4-2933. Support for DDR4-3200 technically gives the system a boost from 23.46 GB/s per channel to 25.60 GB/s, an increase of 9.1%.
The base models of Cooper Lake will also be updated to support 1.125 TiB of memory, up from 1 TB. This allows for a 12 DIMM scenario where six modules are 64 GB and six modules are 128 GB. One of the complaints about Cascade Xeons was that in 1 TB mode, it would not allow for an even capacity per memory channel when it was filled with memory, so Intel have rectified this situation. In this scenario, it means that the six 128 GB modules could also be Optane. Why Intel didn’t go for the full 12 * 128 GB scenario, we’ll never know.
The higher memory capacity processors will support 4.5 TB of memory, and be listed as ‘HL’ processors.

Cooper Lake will also support Intel’s second generation 200-series Optane DC Persistent Memory, codenamed Barlow Pass. 200-series Optane DCPMM will still available in 128 GB, 256 GB, and 512 GB modules, same as the first generation, and will also run at the same DDR4-2666 memory speed. Intel claims that this new generation of Optane offers 25% higher memory bandwidth than the previous generation, which we assume comes down to a new generation of Optane controller on the memory and software optimization at the system level.
Intel states that the 25% performance increase is when they compare 1st gen Optane DCPMM to 2nd gen Optane DCPMM at 15 W, both operating at DDR4-2666. Note that the first-gen could operate in different power modes, from 12 W up to 18 W. We asked Intel if the second generation was the same, and they stated that 15 W is the maximum power mode offered in the new generation.








99 Comments
View All Comments
JayNor - Thursday, June 18, 2020 - link
Intel 4S and 8S also increase the memory bandwidth vs a 1S solution, since more memory channels per each socket, right?also ... Ice Lake Server will have Sunny Cove
from 12/12/2018 ARS Technica article:
"Both Intel and AMD have shared these limits since 2003. No longer: Sunny Cove extends virtual addresses to 57 meaningful bits (with the top 7 bits again either all zeroes or all ones, copying bit 56), with physical memory addresses of up to 52 bits. To handle this requires a fifth level in the page table. The new limits enable 128PB of virtual address space and 4PB of physical memory."
Deicidium369 - Friday, June 19, 2020 - link
Agreed - 2 dual socket is preferable to 1 quad socket.The comparison should be between the 2 socket Ice Lake SP and not the Cooper Lake 4 and 8 sockets. Ice Lake SP will be 38C per socket, 76 cores and 128 PCIe4 lanes in a dual socket system. Ice Lake's Sunny Cove brings a 20% increase in IPC - so that 76C performs more like a 90 or 91 core Cooper Lake. So 128 AMD cores vs 90 Intel cores - and the same 128 PCIe4 lanes and the same 8 channel memory - and the ability to use Optane DIMMs
Not much of an advantage anymore.
schujj07 - Friday, June 19, 2020 - link
Due to VMware's change in licensing, no one is going to buy a 38c Ice Lake same as no one will buy a 48c Epyc. The only people who might are cloud providers running open source hypervisors. IDK if you know how the licensing changed, but VMware has changed their license to 32c/socket/license. If you are running a 38c Ice Lake you will need 2 licenses for it, same as the 48 or 64c Epyc. The difference is the 64c Epyc at least maximizes the cores/socket requirement.When Ice Lake is released, it won't be competing against Zen2 Epyc, it will be competing against Zen3 Epyc.On the PCIe lane Ice Lake is still at a disadvantage in a dual socket setup. Depending on configuration, Epyc can have 160 PCIe 4.0 lanes for IO and still have 96 lanes for CPU-CPU communication. Even with 96 CPU communication lanes EPYC still provides ~50% more CPU-CPU bandwidth than an Ice Lake with 6 UPI links. In all honesty Ice Lake only has caught up with 1st Gen Epyc on IO but 2nd Gen on IPC.
Deicidium369 - Saturday, June 20, 2020 - link
Intel will sell as many ICL 38 cores as it can produce - I agree that most will be 32C IF they are destined for a VMware farm..Epyc has 128 PCIe4 Lanes PERIOD. in a dual socket Epyc - 64 lanes on EACH CPU is used to communicate with the other CPU. Leaving 128 PCIe4 lanes for IO. and 64 PCIe4 lanes for CPU to CPU communications..
Cool story
schujj07 - Saturday, June 20, 2020 - link
Wrong. There are 2 different dual socket setups possible. The 128 lane IO lane setup and the 160 lane IO setup. https://www.servethehome.com/amd-epyc-7002-series-... In the 128 IO setup there are also 128 lanes for Cpu-CPUDeicidium369 - Saturday, June 20, 2020 - link
There are no 4 socket Epycs.each CPU has 128 PCIe4 lanes - in a 2 socket system, 64 of them are used as CPU to CPU communications - please explain how you can add additional processors and still have PCIe lanes for, you know, IO.
AnGe85 - Thursday, June 18, 2020 - link
As you can already estimate/derive from the provided graph, Epyc does not compete with Xeon's in DL/ML-Tasks, simply because of missing features.A 4S system based on low priced Xeon's should already be enough to outperform a high-end Epyc system with two 7742. AVX-512, VNNI and DLBoost provide a much higher relative performance due to specialization for these types of workloads.
AMD will provide semi custom Zen3-Epyc's for the Frontier with good cause. ;-)
mode_13h - Thursday, June 18, 2020 - link
But, if you really care about deep learning performance, then you wouldn't use a CPU for it. That's why Intel just spent $2B to acquire Habana Labs.Deicidium369 - Thursday, June 18, 2020 - link
Or FPGAs configured as Tensor cores or tensor coresmode_13h - Thursday, June 18, 2020 - link
Also, AVX-512 has significant performance pitfalls. It's close to being an anti-feature.