Arm's New Cortex-A78 and Cortex-X1 Microarchitectures: An Efficiency and Performance Divergence
by Andrei Frumusanu on May 26, 2020 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- GPUs
- Cortex
- Cortex A78
- Cortex X1
- Mali G78
Performance & Power Projections: Best of Both Worlds
We quickly looked at some projected figures at the start of the article, but now that we've had a chance to dig through the new CPUs, let's more precisely define the expected performance, power and area gains that the new Cortex-A78 and X1 cores are supposed to achieve.
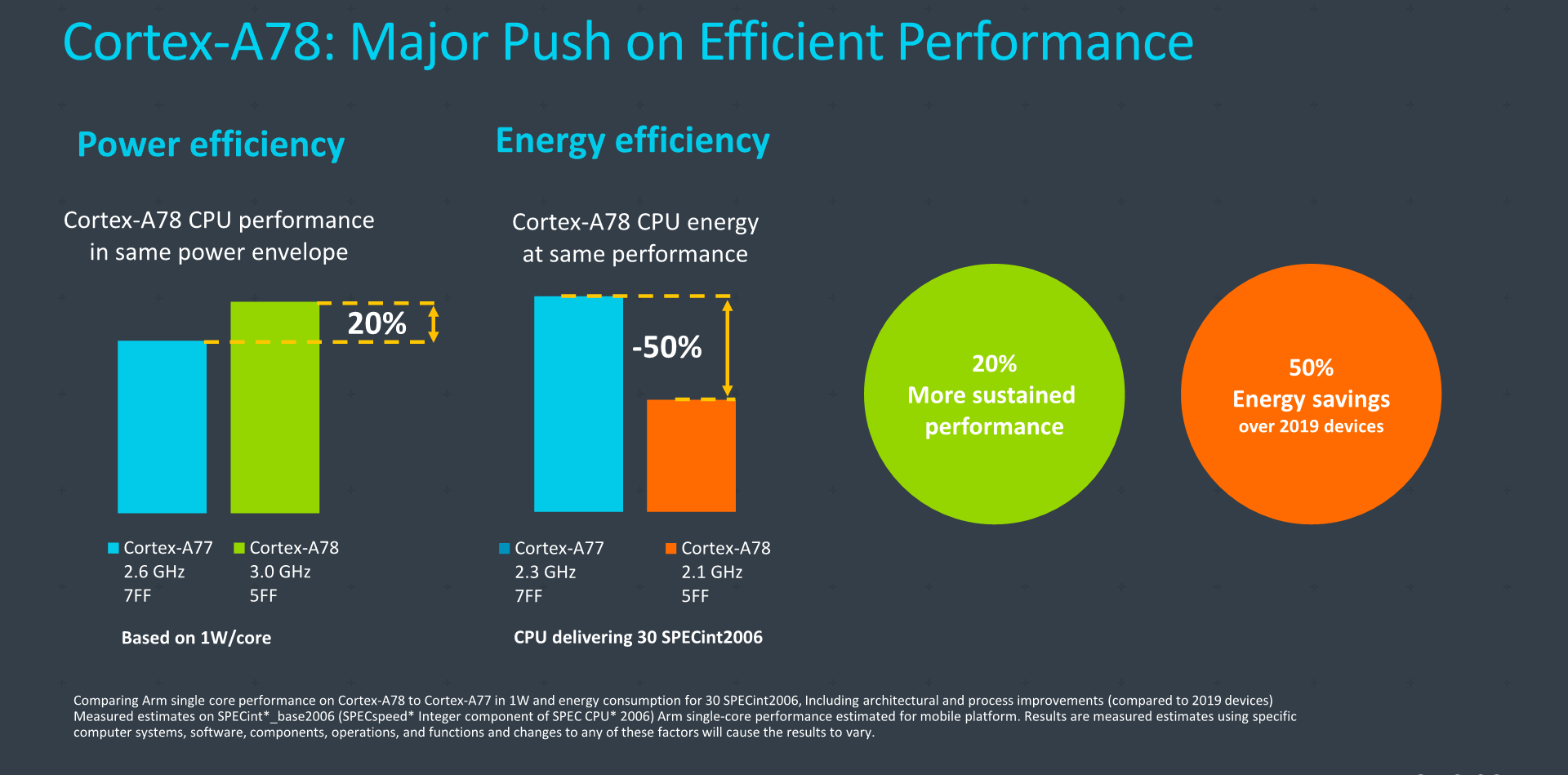
Starting off with the Cortex-A78, the first comparison figures here are meant to represent the generational improvements the A78 would achieve in a target 2021 system on a TSMC N5 node. So the figures here contain both the microarchitectural gains as well as the expected process node improvements.
In terms of performance, at an ISO-power target of 1W for a core, Arm says that an A78 implementation would bring with it a 20% increase in performance, which is a healthy upgrade. A 2.6GHz A77 here on N7 here grossly matches the MediaTek Dimensity 1000(+), and the 1W power figure also roughly matches the power I’ve measured on that SoC.
Meanwhile at an ISO-performance comparison, the A78 would be able to halve the power and energy consumption compared to a 2.3GHz A77 on N7. This comparison is likely aimed at various mid-core implementations out there in the market, it is a bit of an arbitrary comparison but Arm also showcases some better figures we’ll go over in just a bit.
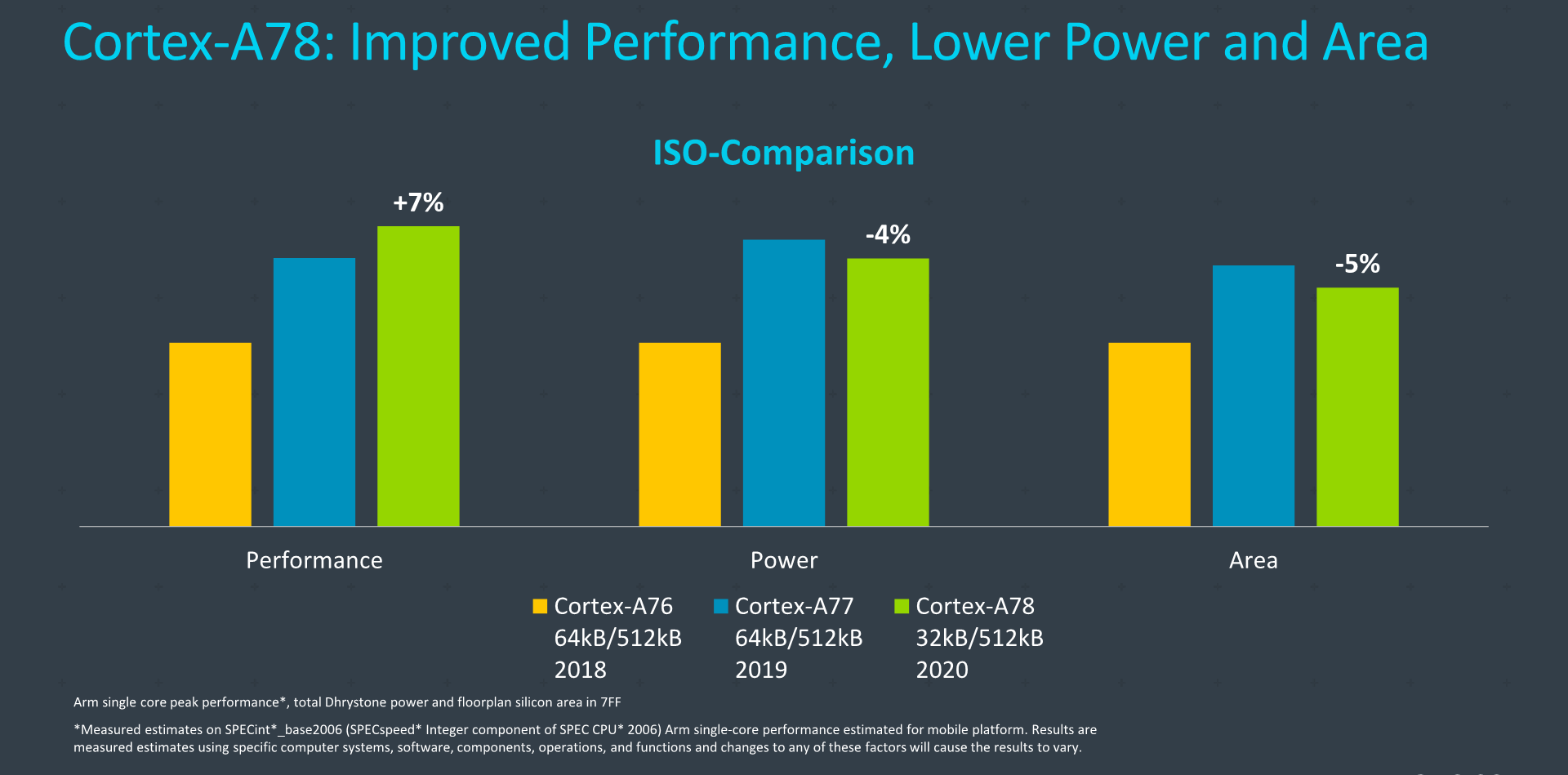
When actually looking at an ISO-process node comparison with a similar core configuration (essentially what Arm expects to be most commonly implemented), we’re seeing the A78 improve performance by roughly 7% over a Cortex-A77, all while reducing power by 4% and reducing area by 4%. It’s again important to note that while these figures sound maybe a little timid, Arm’s projected figures here do showcase an A78 with a lower-bounds configuration such as only 32KB L1D and L1I caches. I think the best way to interpret these numbers is to assume that this would be an implementation vendors would use to implement as their middle performance cores, leaving the higher perf targets for the X1.

Interestingly, Arm here for the first time ever published a whole performance/power curve of a microarchitecture, comparing the A77 to the A78. We see the higher cost at higher operating frequencies and the quadratic increase in power with increased voltage that is required to reach those higher frequencies (P = f * V²).
At the same peak performance point the A77 was able to achieve, the new A78 would use up 36% less power. At a more intermediate performance level (I think they might be using the process’ nominal voltage point here), this power reduction would be 30%. Finally, at the same power level, the A78 can increase performance by 7%.
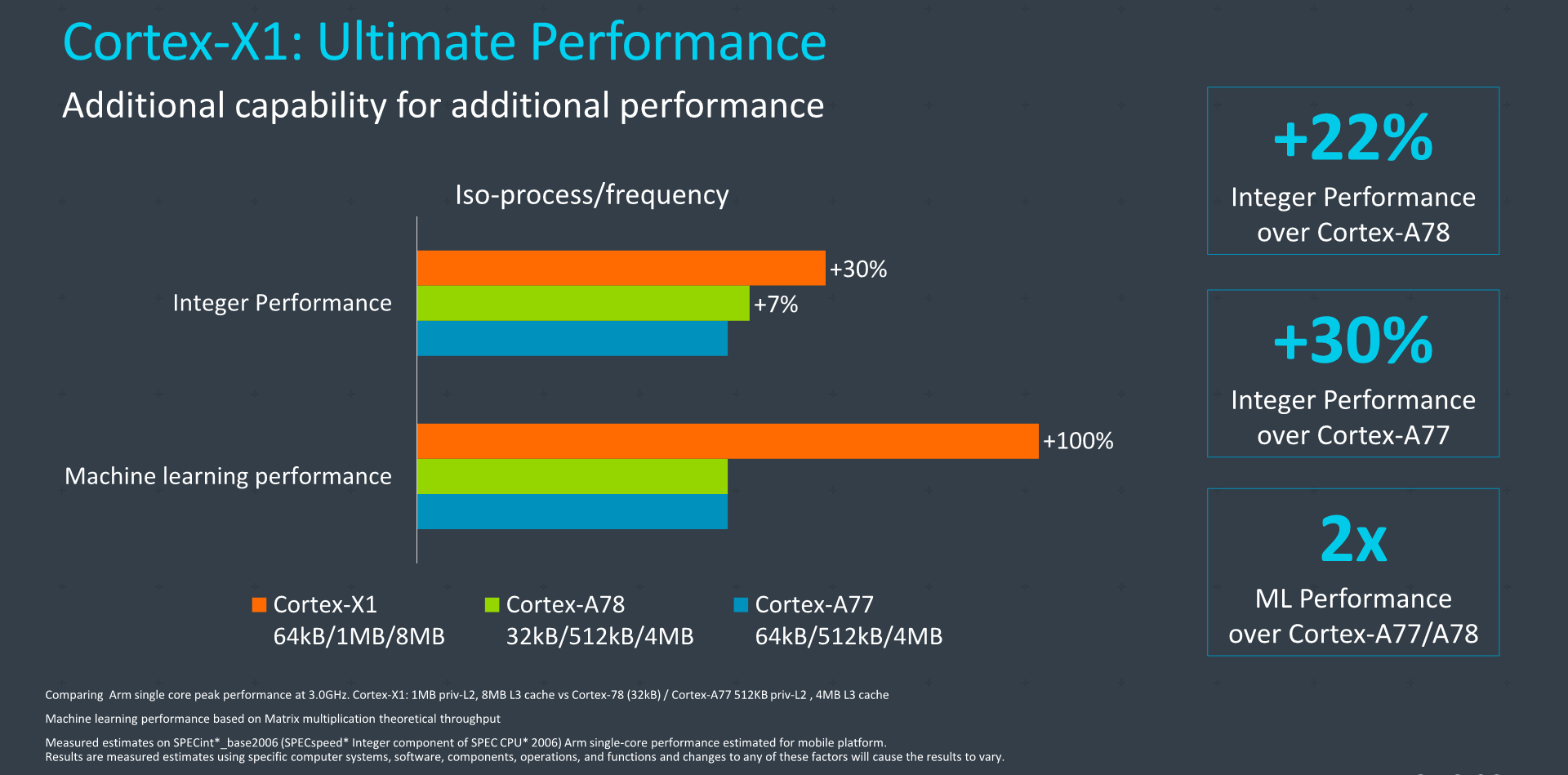
Moving onto the Cortex-X1, the generational performance improvements here are a lot more impressive, and we’re seeing an increase of +30% in terms of peak performance at the same frequencies versus the A77. This comparison would actually be a maximally configured X1 versus a maximally configured A77. It's to be noted that we never saw a 3GHz A77 by vendors, meaning the real-world performance boost would actually be even bigger than this (I’m actually expecting vendors to finally hit that 3GHz target this time around, on 5nm, fingers crossed).

The 30% IPC improvements versus the A77 cover both integer and floating-point suites of SPEC2006, which is extremely impressive. Arm also showcased Stream bandwidth improvements as well as Octane performance boosts, although I don’t find these to be quite as relevant, although they do serve as pointers of what to expect of the microarchitectures in such workloads.
Arm was relatively vague on the power and area efficiency of the X1, quoting that they aren’t quite as public with these figures for these “custom” parts as they are with public roadmap designs such as the Cortex-A78, but I was able to figure out a few rough metrics. In terms of area, on a similar process, we should expect an X1 cores to be roughly 1.5x the size of an A78 – including the difference between maximized L1 and L2 caches. Power should also be roughly in that ballpark figure.
If vendors are able to actually do a good implementation and there aren't any bad surprises with the upcoming 5nm processes, we should be seeing something similar to these projections:
Again, as a big note – these figures are largely my own projections based on the various data-points that Arm has presented. This can end up differently in actual products, but in the past our predictions of the A76 and A77 ended up extremely close to the actual silicon, if not even pessimistically worse than what the real figures ended up at.
This generation, I do expect vendors to actually hit the 3GHz target for the Cortex-X1, as I have heard this being one of the goals the vendors are aiming to achieve for next year’s SoCs. I’m not too sure how many vendors will be doing for this for the Cortex-A78, which will more likely end up at lower clock speeds and implemented with a greater focus on power efficiency and area.
The Cortex-A78 would generally end up with the same power usage as current generation A77 products such as the Snapdragon 865 – with the vendors possibly using the process gains to get the last hundred MHz required to reach the 3GHz mark. The performance projection here is largely based on Arm’s +7% performance boost as well as a small clock boost. It would be a respectable upgrade, but nothing too earth-shattering in terms of generational updates.
The performance bump of an X1 system would be extremely competitive here, essentially being 37% faster than a Snapdragon 865 SoC today. That’s a huge generational bump and would put Arm very much in distance of Apple’s A13 cores, although in reality its competition would be the upcoming A14.
What’s really shocking here is how close Arm would be getting to Intel and AMD’s current best desktop systems in terms of performance. If both incumbent x86 vendors weren’t already worried about Arm’s yearly rate of improvement over the last few generations, they should outright panic at these figures if they actually materialize – and I do expect them to materialize.
The Cortex-X1 here is projected to use 1.5x the power of an A78. This might end up slightly lower but I’m being overly cautious here and prefer to be on the more pessimistic side. Here’s the real kicker though: the X1 could very well use up to 2x the power of a Cortex-A77/A78 and it would still be able to compete with Apple’s cores in terms of energy efficiency – the core’s increased performance largely makes up for its increased power draw, meaning its energy efficiency at the projected power would roughly only be 23% worse than an A78, and only 11-14% worse than say a current generation Snapdragon 865. Arm has such a big leeway in power efficiency at the moment that I just don’t see any scenario where the X1 would end up disappointing.
For years we’ve wanted Arm to finally go for no-compromise performance, and the Cortex-X1 is seemingly exactly that. That’s really exciting.








192 Comments
View All Comments
Wilco1 - Tuesday, May 26, 2020 - link
Disappointed in what way? Flagship phones have been more than fast enough in the last few years. There is a balance between power consumption and performance - and I think the improved efficiency of Cortex-A78 will be more useful in typical use-cases. It won't win benchmarks, but if you believe iPhone performance is measurably better in real-life use (rather than benchmarks), why not just buy one?syxbit - Tuesday, May 26, 2020 - link
Put it in context. You pay $1500 for a Galaxy S20 ultra that's slower than a $400 iphone.If you do a lot of web browsing on javascript heavy pages, nothing beats single threaded perf. You can't improve it by just throwing slower cores at it.
Discourse did a good writeup that's still valid today.
https://meta.discourse.org/t/the-state-of-javascri...
Wilco1 - Tuesday, May 26, 2020 - link
You could also get the $699 OnePlus 8 and beat the S20 ultra on both performance and cost. Where is the difference?Javascript and browsers depend heavily on software optimization, and that's the real issue.
armchair_architect - Tuesday, May 26, 2020 - link
syxbit is right. Javascript and browsers are not just software. They stress CPU in different ways than the usual Spec/Geekbench and X1 will not be just a benchmark core.If you look at DVFS curve of A77 vs A78, X1 will probably be even lower power than A78 in the region of perf in which they overlap.
For the simple reason that to achieve same performance as A77/A78, X1 will need much lower frequency and voltage. This will greatly offset the intrinsic growth in iso-frequency power that X1 will for sure have.
My point would be: going wider helps you be more efficient iso-perf vs narrower cores.
The power efficiency hit only comes when you go over the peak perf offered by the narrower core.
So you could argue that something like X1 is taking the A78 DVFS curve and pushing it down (lower power) and of top of that it extends it to new performance point not even reachable on A78.
Obviously you pay in area for this :)
But Apple has clearly showed over the years that this is the winning formula
ZolaIII - Wednesday, May 27, 2020 - link
You are completely wrong. It's much more about caching than wider core's. X1 is not 50% faster than A78 but it is 50% bigger. Best approach would be wider ISA with same execution units multiplied in numbers like RISC V did lay out already foundations for 256 bit ISA (still a scratch) and is finalising 128 bit one. But there's a catch in tool's and compilers support.soresu - Wednesday, May 27, 2020 - link
X1 does have wider NEON SIMD, twice as wide in fact - so for content that favors SIMD (like dav1d AV1 decoding) you will get a serious jump in performance.Unfortunately the benchmarks do not really give us much of an idea of real world improvement for something like this, so we'll have to wait for products to get a better idea.
dotjaz - Thursday, May 28, 2020 - link
ARM specifically said A78 was designed to INCREASE EFFICIENCY vs A77, a lot of the decisions concur with that.X1 was designed to MAXIMIZE PERFORMANCE sacrificing efficiency and area in the process. When you factor in the leakage caused by larger die. X1 would almost certainly be less efficient than A78 when you drop it to below 2GHz.
Wilco1 - Thursday, May 28, 2020 - link
"Javascript and browsers are not just software."They are just software. Fun fact: your Android browser is built with -Oz. Yes, all optimizations are turned off in order to reduce binary size. That's an insanely stupid software decision which means Android phones appear to be behind iOS when in fact they are not.
name99 - Saturday, May 30, 2020 - link
It's not an "insanely stupid software decision"...Fun fact: Apple ALSO builds pretty much all their software at either -Oz or -Os! Both Apple and Google (and probably MS) are well aware that the "overall system experience" matters more than picking up a few percentage points in particular benchmarks, and that large app footprints hurt that overall system experience. Apple's recommendation for MOST developer code (and followed internally) has been to optimize for size for yikes, at least 20 years, and hasn't changed in all that time.
Look at the (ongoing) work in LLVM to reduce code size ( "outliner" is one of the relevant keywords); the people involved in that span a range of companies. I've seen a lot of work by Apple people, a lot by Google people, some even by Facebook people.
Wilco1 - Saturday, May 30, 2020 - link
There is a world of difference between optimizing performance without regard for codesize and optimizing for smallest possible codesize without any regard for performance. -Ofast is the former, -Oz is the latter. Most software, including Linux distros, uses -O2 as the best tradeoff between these extremes. Non essential applications use -Os (or even -Oz if performance is irrelevant). However a browser is extremely performance sensitive. Saving a few bytes with -Oz loses 10-20% performance and that means you lose the equivalent of a full CPU generation. I call that insanely stupid, there are no other words to describe it.