Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
by Andrei Frumusanu on March 10, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Cloud Computing
- Amazon
- AWS
- Neoverse N1
- Graviton2
SPEC - Multi-Core Performance Scaling
I did mention the L3 cache of the Graviton2 was shared amongst all its cores, and we also discovered how only 8-16 cores were able to saturate the memory controllers of the system. To put those aspects into better context, I ran the SPEC suites at rate instance numbers, ranging from 16, 32, 48 and the full 64 cores, and normalised the results relative to the per-thread performance showcased in the rate-1 single-threaded runs.
What this attempts to showcase is the performance scaling of the full SoC across varying loads of the different workload types. Scaling linearly across cores might be easy for some workloads, but for anything that even remotely has some kind of memory pressure should see greater slowdowns given that all the threads are competing for the shared L3 and DRAM resources.
The testing here for all figures were done on a 16xlarge instance with 64 vCPUs to avoid the possibility of noisy neighbours, and give better reliability in the lower core count results.
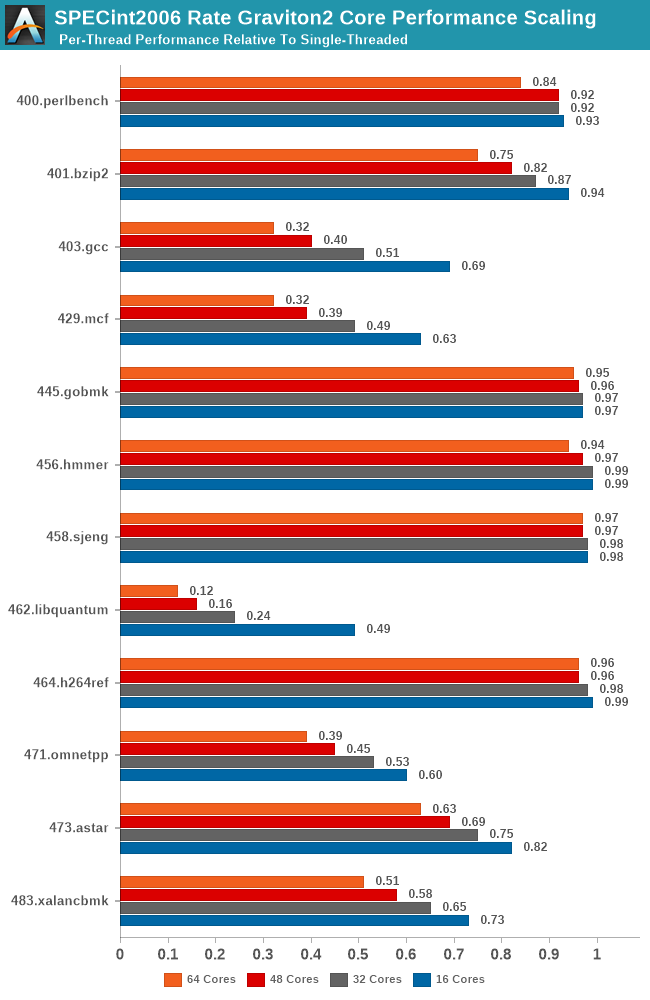
As expected, we’re seeing a quite wide range of results here, and it’s also a good showcase of which SPEC workloads are memory and cache intensive and which are not. Workloads such as 445.gobmk and 456.hmmer aren’t surprising in their near linear scaling as they don’t have too much cache pressure, and the Graviton2’s 1MB L2 per core is also more than enough for 464.h264ref.
On the other hand, well known memory intensive workloads such as 462.libquantum absolutely crater in terms of per-thread performance. This memory bandwidth demanding workload is fully saturating the bandwidth of the system early on with very few cores, meaning that performance barely increases the more threads and cores we throw at it. Such a scaling more or less is mimicked in other workloads of varying cache and memory pressure.
The most worrying result though is 403.gcc. Code compilation should have been one of the bigger use-cases for a platform such as Graviton2, but the platform is having issues scaling well with core count, undoubtedly a result of higher cache pressure of the system. In a single-thread scenario in the system a core would have access to 33MB L2+L3, but when having 64 cores doing the same thing at once you’d end up with only 1.5MB per core, assuming things are evenly competitively shared.
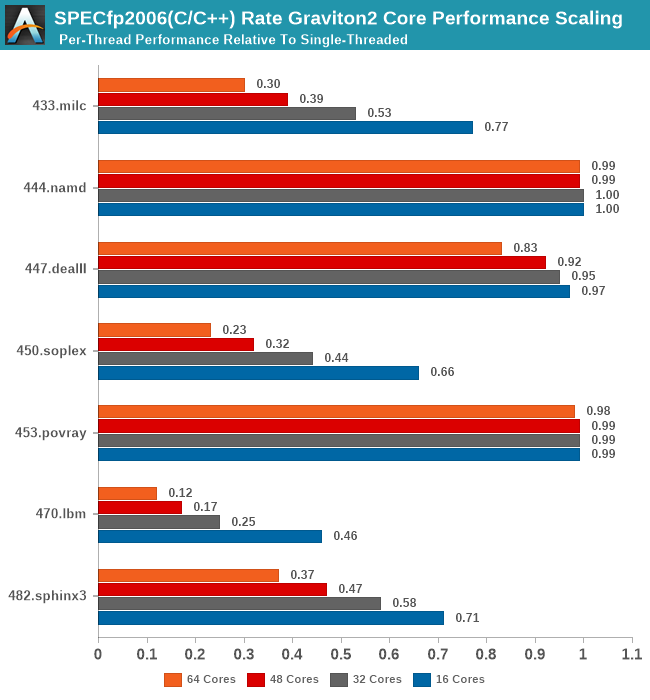
In SPECfp2006, again, we see the well-known memory intensive workloads such as 433.milc and 470.lbm crater in their per-thread performance the more threads you throw at the system, while other workloads are able to scale near linearly with cores.
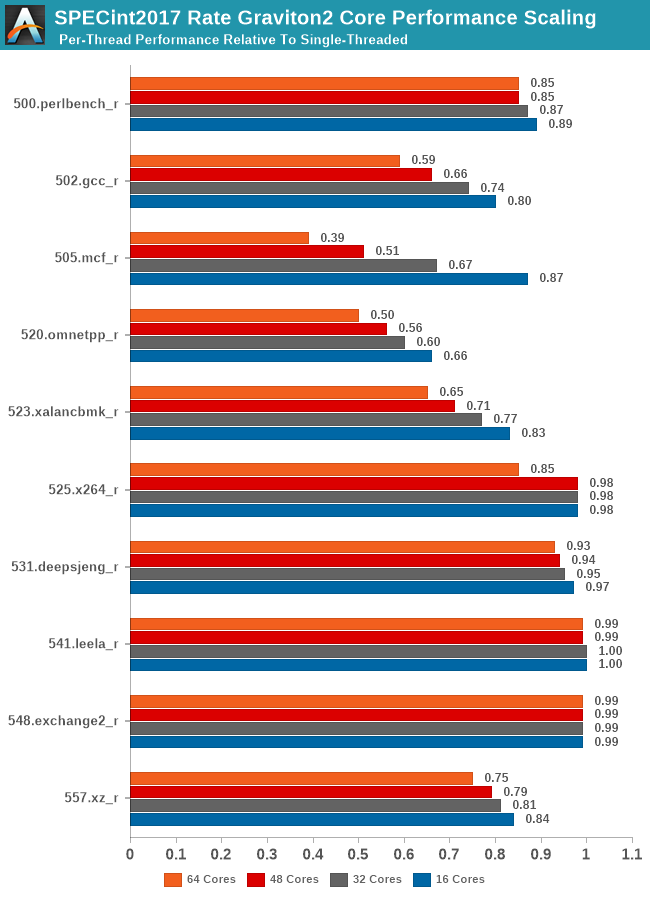
In SPECint2017, we see the workload changes I referred to previously on the single-threaded page. The new gcc and mcf tests are actually scaling better than their 2006 counterparts due to actually reduced memory pressure on the new tests. It does beg the question of which variant of the test is actually more representative of most workloads of these types.
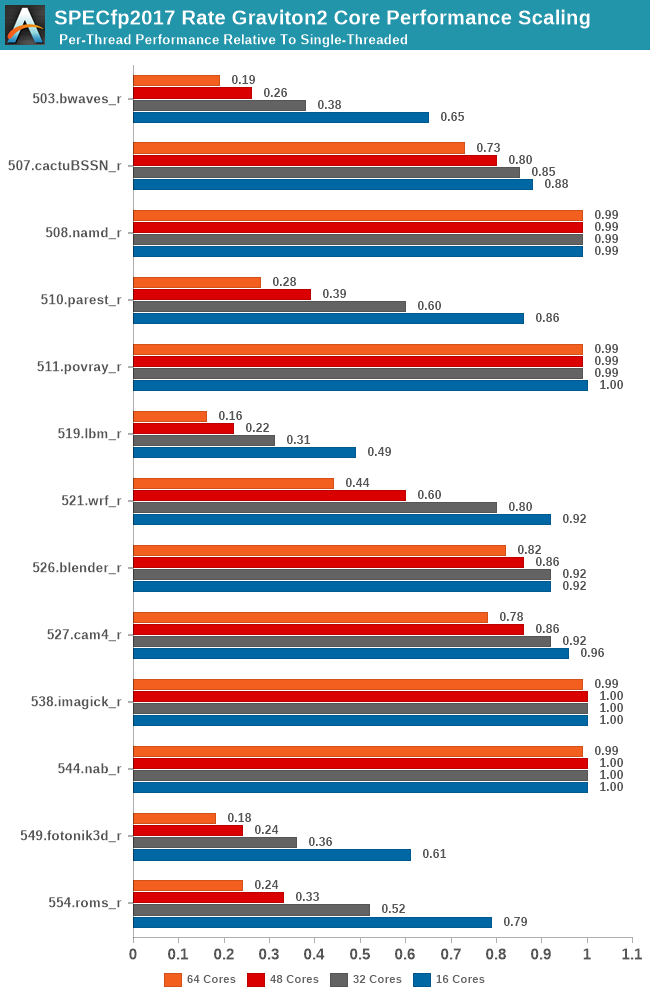
Compared to the int2017 suite, the fp2017 suite scales significantly worse for a larger number of workloads. When Ampere last week talked about its Altra processor, and that it was “designed for integer workloads”, that didn't make too much sense other than in the context that the N1 cores are missing wider SIMD execution units. What does make sense though is that the floating-point suite of SPEC is a lot more memory intensive and SoCs like the Graviton2 don’t fare as well at higher loaded core-counts.
It will be interesting to see where the Arm chip designers are heading to in regards to this general memory bottleneck. If your workload isn’t too memory intensive then scaling up to such huge core counts is an easy way to scale performance as well. On the opposite end of the spectrum on memory hungry workloads, these chips will just be memory starved. Arm had envisioned 64 core Neoverse N1 systems to have 64-128MB of L3 cache, and the CMN-600 scales up to 256MB total in a 128-core system, which seem like more sensible and balanced targets.








96 Comments
View All Comments
eek2121 - Tuesday, March 10, 2020 - link
It is worth noting AnandTech’s own numbers: https://www.anandtech.com/show/14694/amd-rome-epyc...RallJ - Tuesday, March 10, 2020 - link
I understand that, but consider everything boils down to just $/vCPU/hr, I think a discussion around the new Xeon Gold R is warranted. For example, the existing dual-socket Xeon Amazon is using can be substituted by the new 6248R for 60% lower price while providing a modest turbo and base frequency improvement at lower a slight TDP reduction versus the existing Platinum they have. Unless Amazon decides to pocket the saving, that would have a massive impact on the vCPU $ comparison.https://www.anandtech.com/show/15542/intel-updates...
Andrei Frumusanu - Tuesday, March 10, 2020 - link
Hyperscalers never pay full list price for their special SKUs, so comparisons to public new SKUs like the 6248R are not relevant.We're happy to update the landscape once EC2 introduces newer generation instances, but for now, these are the current prices and costs for what's available today and in the next few months.
Spunjji - Wednesday, March 11, 2020 - link
I'm confused. Either you can think that everything boils down to $/vCPU/hr, in which case the only thing that's relevant is what Amazon actually offer, or you can think that "a discussion around the 'new' Xeon Gold R is warranted". They're mutually exclusive.close - Tuesday, March 10, 2020 - link
Great write-up Andrei. One question (I hope I didn't miss the answer in the article). Does Amazon's chip come out in front in the cost analysis because Amazon decided to take a loss or overcharge the other options, or is it an organic difference where it's intrinsically better?Andrei Frumusanu - Tuesday, March 10, 2020 - link
We have no idea of Amazon's internal cost structure, so take the cost analysis from and end-user TCO perspective.eek2121 - Tuesday, March 10, 2020 - link
I suspect the TDP of this chip is likely in the 150 watt range. We also know nothing about the operating environment of any of the chips. For example, the chip is rated for DDR4 3200, but is it running at 3200 speeds? The EPYC chip likely is NOT. So many questions here...Andrei Frumusanu - Tuesday, March 10, 2020 - link
It is running 3200, Amazon confirmed that.They didn't comment on TDP, but given Arm and Ampere's figures, I think my estimate is correct.
Flunk - Thursday, April 9, 2020 - link
They're comparing VMs with the same cost/hour. What number of cores/threads is isn't really relevant.autarchprinceps - Sunday, October 25, 2020 - link
That’s exactly why they reserved the entire hardware. If you run only a single workload on SMT, that single thread can use the entire core. That’s kind of the point of SMT.