The Snapdragon 865 Performance Preview: Setting the Stage for Flagship Android 2020
by Andrei Frumusanu on December 16, 2019 7:30 AM EST- Posted in
- Mobile
- Qualcomm
- Smartphones
- 5G
- Cortex A77
- Snapdragon 865
Machine Learning Inference Performance
AIMark 3
AIMark makes use of various vendor SDKs to implement the benchmarks. This means that the end-results really aren’t a proper apples-to-apples comparison, however it represents an approach that actually will be used by some vendors in their in-house applications or even some rare third-party app.
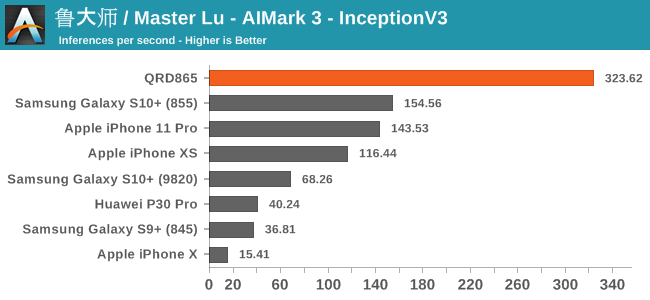
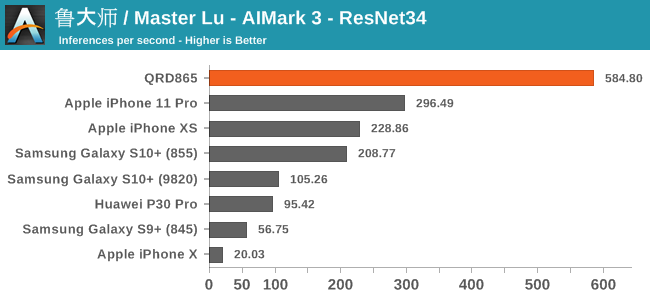
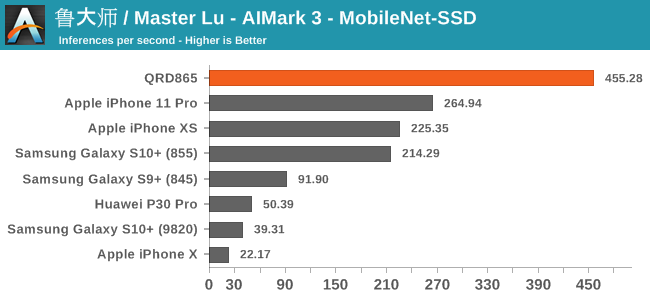
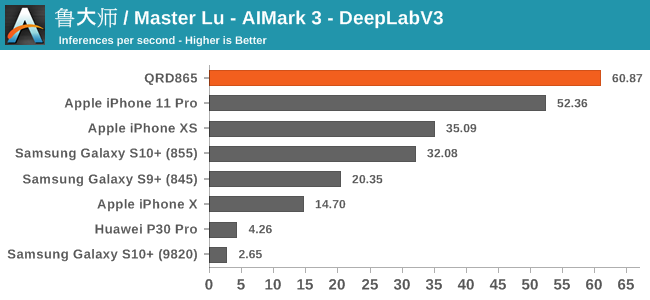
In AIMark 3, the benchmark uses each vendor’s proprietary SDK in order to accelerate the NN workloads most optimally. For Qualcomm’s devices, this means that seemingly the benchmark is also able to take advantage of the new Tensor cores. Here, the performance improvements of the new Snapdragon 865 chip is outstanding, posting in 2-3x performance compared to its predecessor.
AIBenchmark 3
AIBenchmark takes a different approach to benchmarking. Here the test uses the hardware agnostic NNAPI in order to accelerate inferencing, meaning it doesn’t use any proprietary aspects of a given hardware except for the drivers that actually enable the abstraction between software and hardware. This approach is more apples-to-apples, but also means that we can’t do cross-platform comparisons, like testing iPhones.
We’re publishing one-shot inference times. The difference here to sustained performance inference times is that these figures have more timing overhead on the part of the software stack from initialising the test to actually executing the computation.
AIBenchmark 3 - NNAPI CPU
We’re segregating the AIBenchmark scores by execution block, starting off with the regular CPU workloads that simply use TensorFlow libraries and do not attempt to run on specialized hardware blocks.
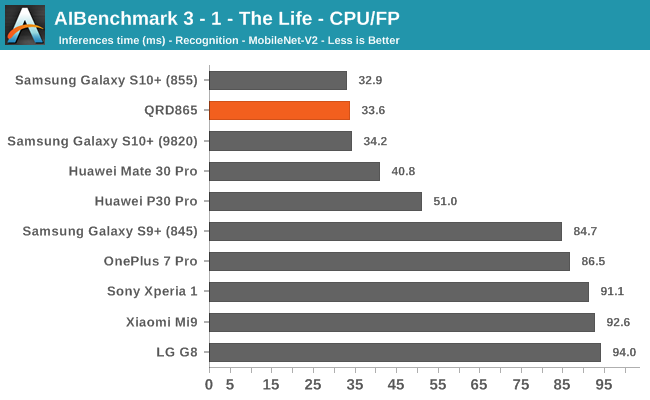
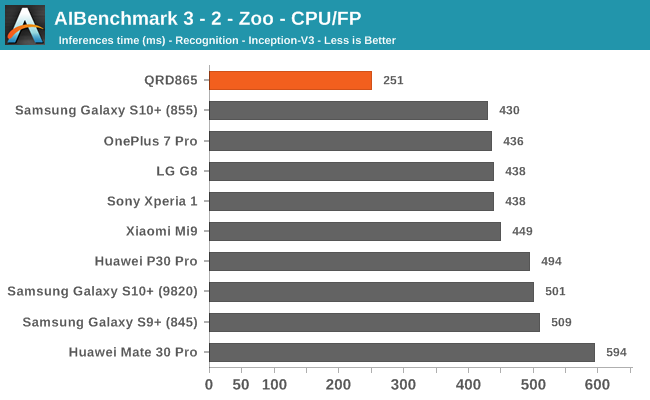
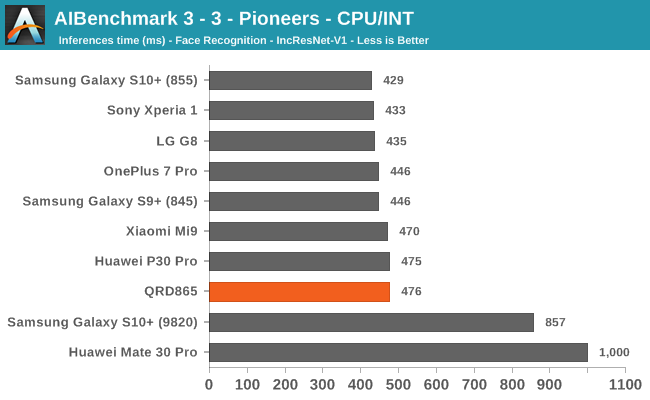
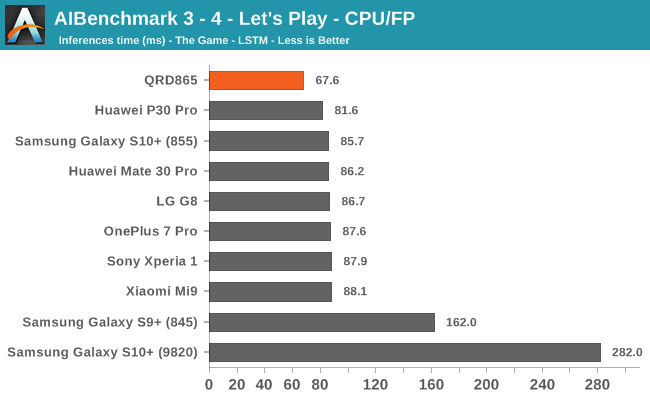
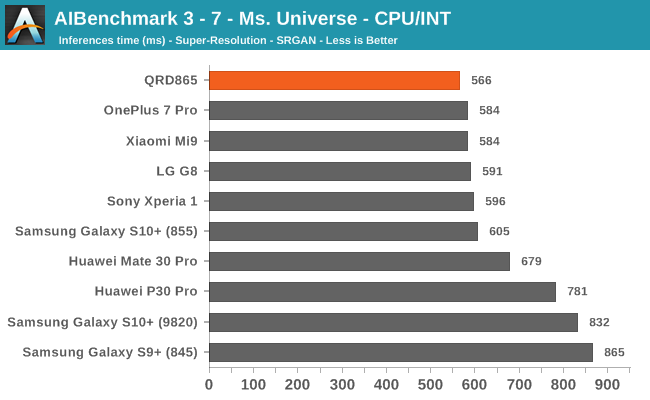

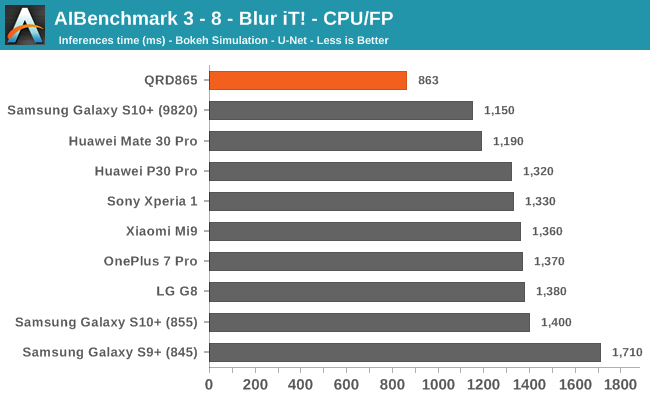
Starting off with the CPU accelerated benchmarks, we’re seeing some large improvements of the Snapdragon 865. It’s particularly the FP workloads that are seeing some big performance increases, and it seems these improvements are likely linked to the microarchitectural improvements of the A77.
AIBenchmark 3 - NNAPI INT8
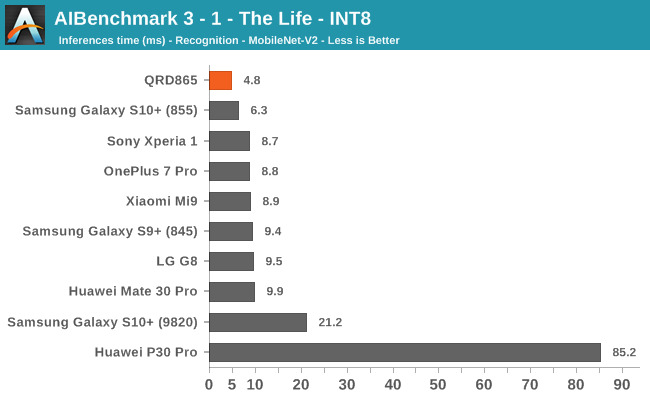
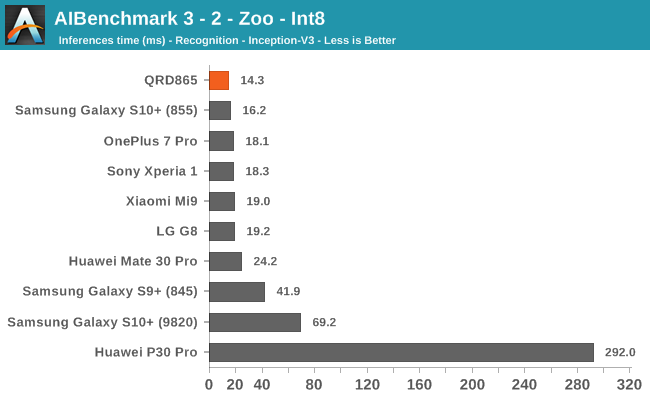
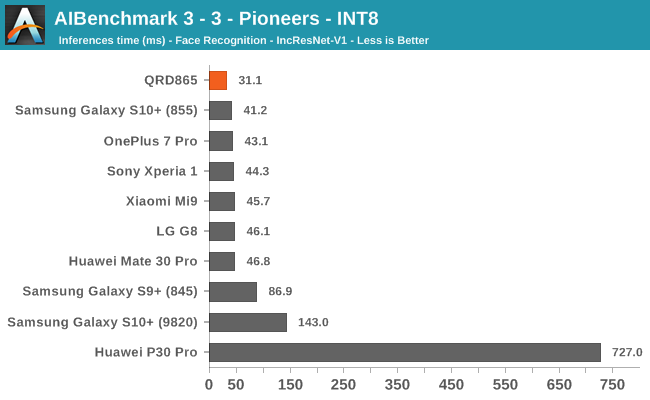
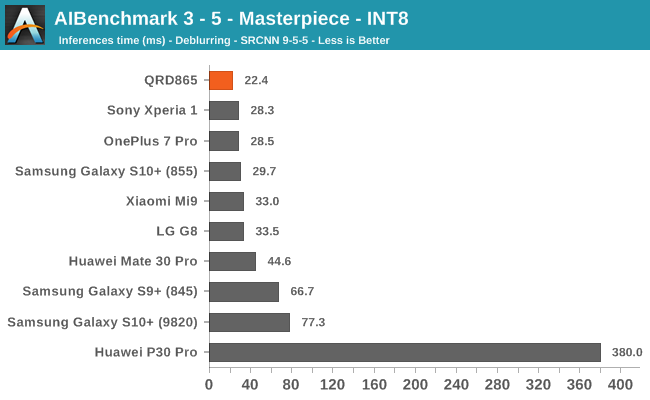
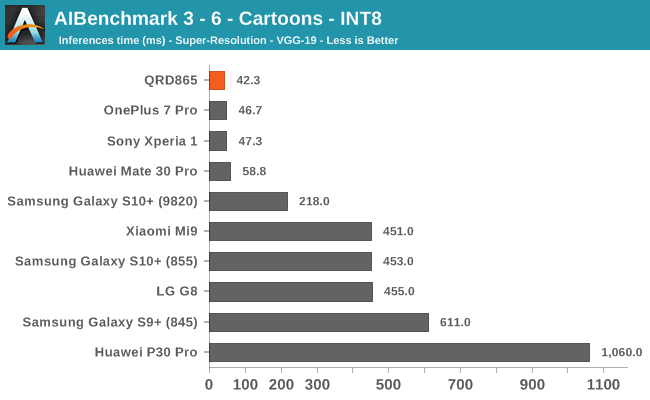
INT8 workload acceleration in AI Benchmark happens on the HVX cores of the DSP rather than the Tensor cores, for which the benchmark currently doesn’t have support for. The performance increases here are relatively in line with what we expect in terms of iterative clock frequency increases of the IP block.
AIBenchmark 3 - NNAPI FP16
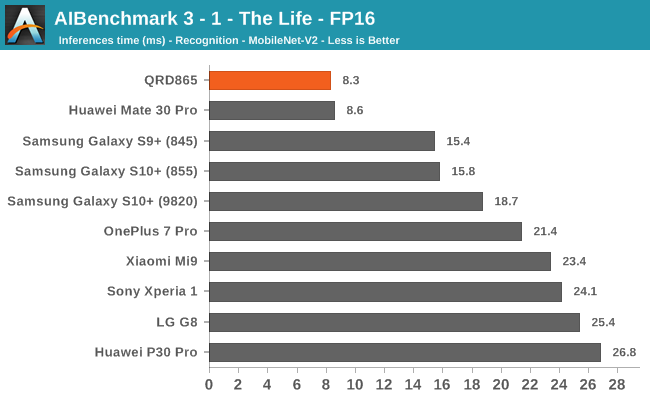
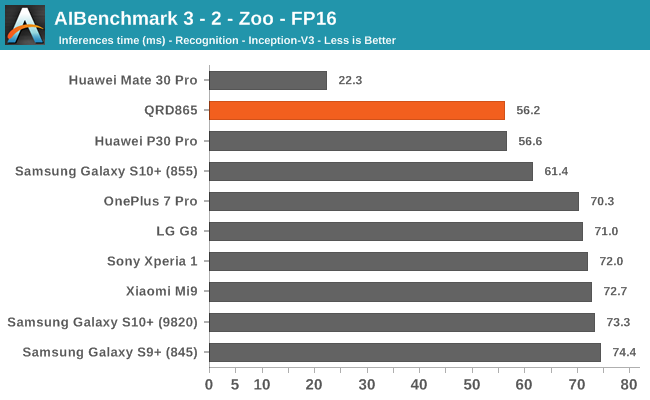
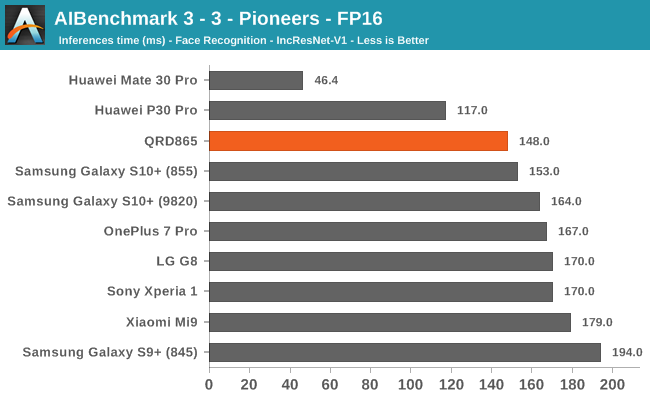
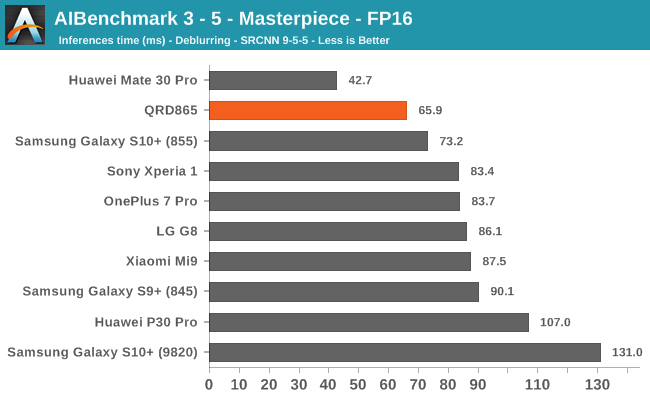
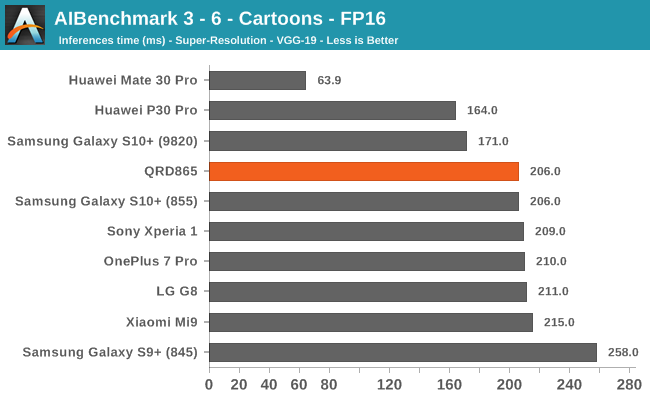
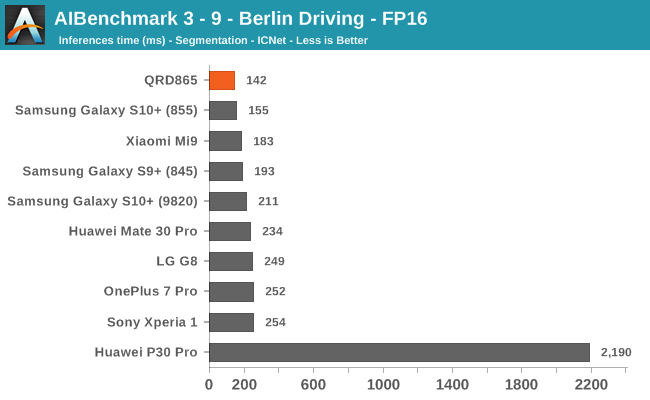
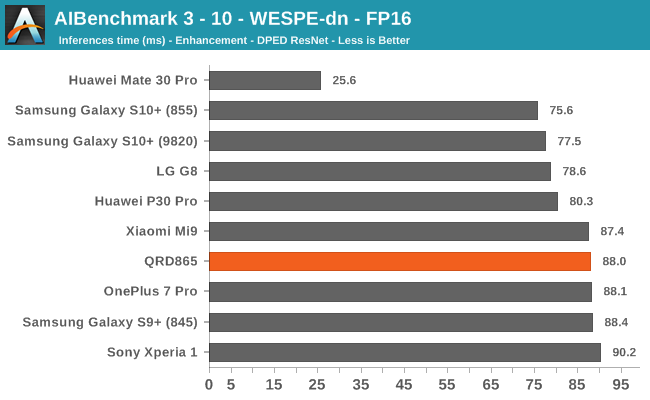
FP16 acceleration on the Snapdragon 865 through NNAPI is likely facilitated through the GPU, and we’re seeing iterative improvements in the scores. Huawei’s Mate 30 Pro is in the lead in the vast majority of the tests as it’s able to make use of its NPU which support FP16 acceleration, and its performance here is quite significantly ahead of the Qualcomm chipsets.
AIBenchmark 3 - NNAPI FP32
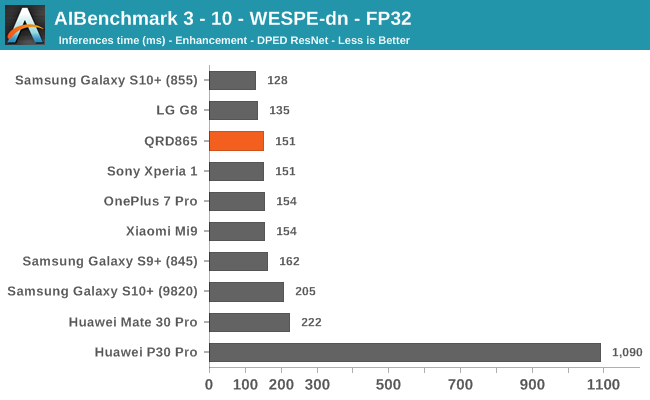
Finally, the FP32 test should be accelerated by the GPU. Oddly enough here the QRD865 doesn’t fare as well as some of the best S855 devices. It’s to be noted that the results here today were based on an early software stack for the S865 – it’s possible and even very likely that things will improve over the coming months, and the results will be different on commercial devices.
Overall, there’s again a conundrum for us in regards to AI benchmarks today, the tests need to be continuously developed in order to properly support the hardware. The test currently doesn’t make use of the Tensor cores of the Snapdragon 865, so it’s not able to showcase one of the biggest areas of improvement for the chipset. In that sense, benchmarks don’t really mean very much, and the true power of the chipset will only be exhibited by first-party applications such as the camera apps, of the upcoming Snapdragon 865 devices.








178 Comments
View All Comments
joms_us - Tuesday, December 17, 2019 - link
Ah poorman's attempt to hide the truth. I feel sorry for those buying a phone (even replacing a desktop) because they see it flying with colors in SPEC.Andrei Frumusanu - Tuesday, December 17, 2019 - link
You're just a blabbering idiot. You keep pulling things out your ass, nobody ever said A9 is faster than Ryzen or Skylake, I dare you find a quote or data that says that. The A13 was the first to *match* them.The test you quote isn't ST like the SPEC results, and it's not even a full CPU test as it has API components.
joms_us - Tuesday, December 17, 2019 - link
Ahh the irony... Let's see who is the blabbering !d!ot here.You reminded us on who the IPC gorila is...
https://twitter.com/andreif7/status/11569659188089...
There it shows A13 and even A9 stomping the latest and greatest Ryzen and Skylake processors
But then when you compare the A13 versus the Android SoC in various apps and websites, it is the complete opposite.
I respect you because you have an excellent knowledge in what you do but it comes down to the toilet drain once your critical thinking is subpar and you are shadowed with your ego that you think yours and only yours speak the truth. I would not hesitate to hire you as my design engineer really but you have to back your claims with facts. When you state one is the fastest (especially by huge margin), it has to reflect in any test that you throw at it.
I would rest my case if you can convince Lisa or Bob that their processors are mediocre compared to Apple's latest SoC LOL.
Andrei Frumusanu - Tuesday, December 17, 2019 - link
That tweet is about IPC of the microarchitectures, not absolute performance.You literally have absolutely not a single whim of understanding of what's going on here and keep making a complete utter fool of yourself repeating lies, all you see is a bar graph being bigger than the other and suddenly that's the your whole basis on the truth of the world.
The actual engineers and architects in the industry very well know where they lie in relation to what's Apple's doing; I don't need to convince anybody.
joms_us - Tuesday, December 17, 2019 - link
No, you just told the whole world, that the fastest chip on the planet is the Apple SoC. A chip with great IPC will give great performance result, right? Your graph is telling us, a 1Ghz A12x core is equivalent to a 2Ghz Ryzen core which is utter BS. When AMD or Intel announce that their next processor has 20% IPC improvement, it does show in any tool/benchmark or app you throw at it not the opposite.Your tests methodology/tools are completely flawed and outdated as they don't translate to real world results. They are great though if you are comparing two similar platforms.
Andrei Frumusanu - Tuesday, December 17, 2019 - link
> No, you just told the whole world, that the fastest chip on the planet is the Apple SoCI did not. High IPC doesn't just mean it's the fastest overall. AMD and Intel still have a slight lead in over performance.
> A chip with great IPC will give great performance result, right?
As long as the clock-rate also is high enough, yes.
> Your graph is telling us, a 1Ghz A12x core is equivalent to a 2Ghz Ryzen core
That's exactly correct. Apple current has the highest IPC microarchitecture in the industry by a large margin.
> which is utter BS.
The difference between you and me is that I actually have a plethora of data to back this up, actual instruction counter data from the performance counters, actual tests tests that show that Apple's µarch is in fact 50% wider than anything else out there.
You are doing absolutely nothing than spewing rubbish comments with absolutely zero understanding of the matter. You have absolutely nothing to back up your claims about flawed and outdated methodologies, while I have the actual companies who design these chips agreeing with the data I present.
arsjum - Wednesday, December 18, 2019 - link
Andrei,As a member of Anandtech staff, you should be better than this. This is not an XDA forum.
Come on.
LordConrad - Tuesday, December 17, 2019 - link
Now if Samsung could just increase the anemic L2 cache. I want 1MB per A7x core and 512KB per A5x core.yankeeDDL - Tuesday, December 17, 2019 - link
It is truly disappointing that Android HW needs to run on SoC with the performance of the iPhone 3-4 generations older.I really don't understand with all the demand there is, why nobody comes up with something at least within the range of Apple's SoC.
Wilco1 - Tuesday, December 17, 2019 - link
You mean 2 generations behind at most on SPEC. And while interesting technically, it remains debatable how much that actually matters in actual phone use (where having fast SSD, download speeds and a lot of memory can help more). As well as having ~20% better power efficiency of course.It would be relatively easy to quadruple L2 to 1MB, L3 to 8MB and system cache to 16MB and get ~20% performance gain on SPEC. The area would be much larger and hence the cost of the SoC which would add to the cost of phones. QC's competitors would be happy to increase their market share with far cheaper SoCs which are equally fast in real-world usage.