The Apple iPhone 11, 11 Pro & 11 Pro Max Review: Performance, Battery, & Camera Elevated
by Andrei Frumusanu on October 16, 2019 8:30 AM ESTThe A13's Memory Subsystem: Faster L2, More SLC BW
The memory subsystem of a chip is an essential backbone for the performance of not only the CPU cores, but also the whole rest of the system. In this case we’re taking a closer look at how the memory subsystem behaves on the CPU side of things.
Last year we saw Apple make significant changes to the SoC’s memory subsystem with the inclusion of a new architecture system level cache (SLC), which serves as the last level cache for not only the CPU, but also a lot of other SoC components like the GPU.
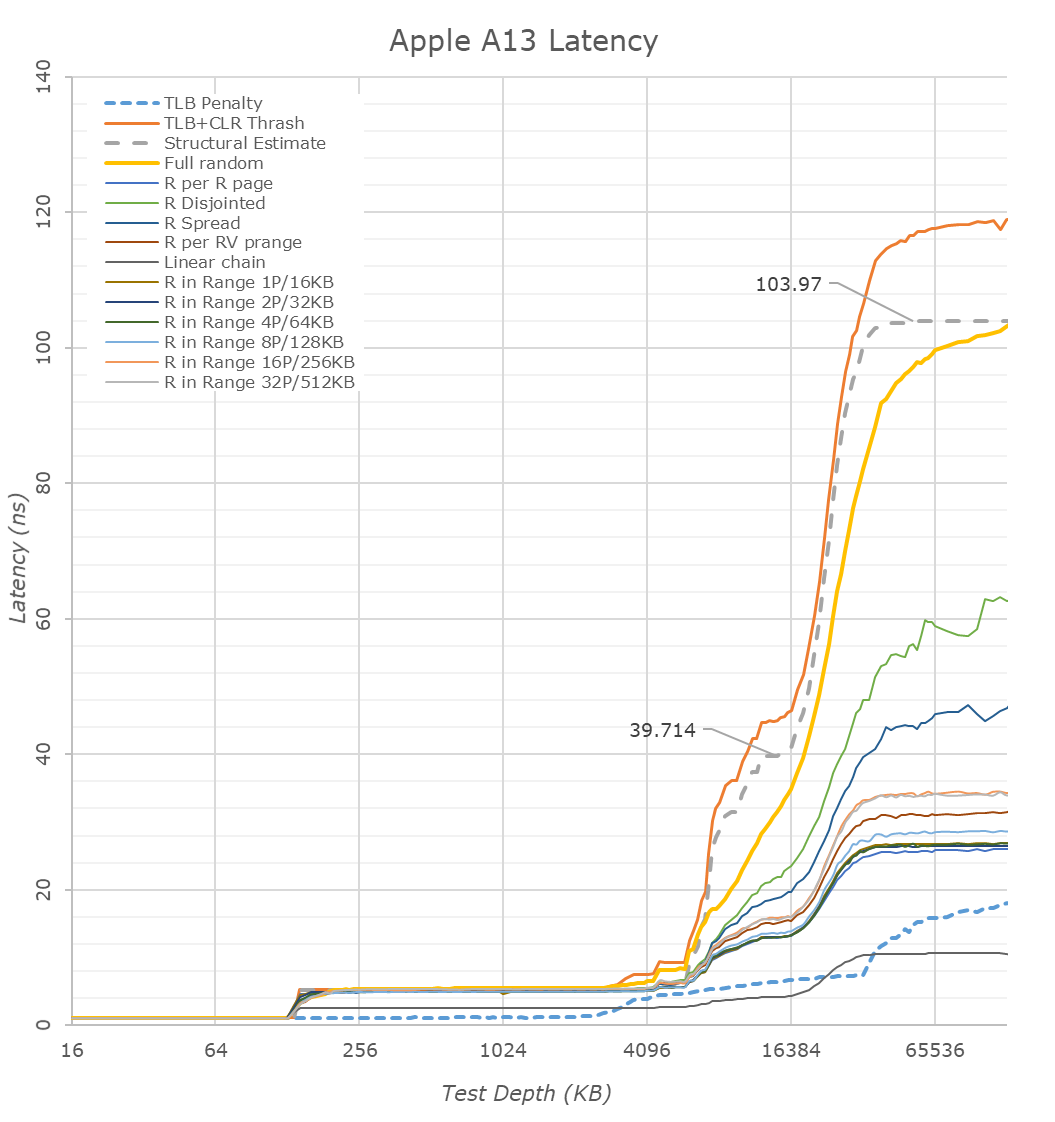
Looking first at the linear graphed memory latencies, we see that the A13’s structural DRAM latency falls in at ~104ns, a very slight regression to the 102.8ns of the A12. Apple in this regard isn’t the best among mobile SoCs, HiSilicon’s newest Kirin 990 now falls in at ~96ns and the Exynos 9820 should also fall into a similar range, however this doesn’t matter too much in the grand scheme of things given Apple’s massive cache hierarchy. Patterns such as full random pointer chasing is significantly more performant on Apple’s cores and this should be tightly linked to the strong TLBs as well as iOS’s system configuration choice of using 16KB pages.
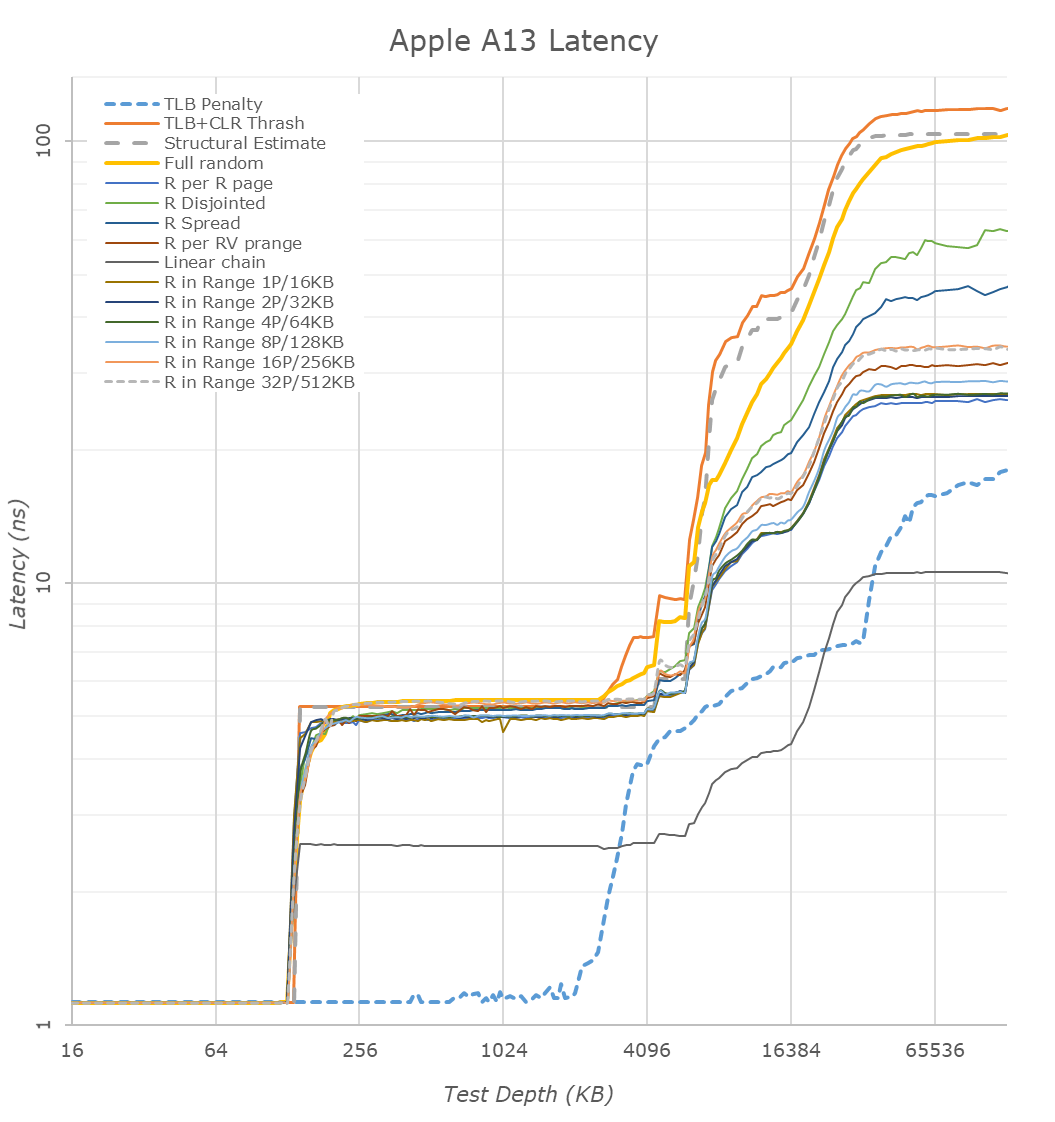
Moving to a logarithmic chart we better see the transitions between the cache hierarchies. We can clearly see Apple’s 128KB L1D cache here. The L2 cache is also relatively straightforward till 4MB as the latencies are relatively flat. From here on things become quite complicated and things differ a bit compared to the A12. Last year we determined that the L2 cache structure physically must be around 8MB in size, however we saw that it only looks as if the big cores only have access to around 6MB. Apple employs an “L2E” cache – this is seemingly a region of the big core L2 cache that serves as an L3 to the smaller efficiency cores (which themselves have their own shared L2 underneath in their CPU group).
In this region the new A13 behaves slightly different as there’s an additional “step” in the latency ladder till about 6MB. Frankly I don’t have any proper explanation as to what the microarchitecture is doing here till the 8MB mark. It does look however that the physical structure has remained at 8MB.
Going further out into the cache hierarchy we’re hitting the SLC, which would act as an L3 to the large performance cores, but should be shared with other IP blocks in the SoC. Here we see a significant change in behavior to the A12. If one had to guess as to what happening you’d think that the SLC has grown in size beyond the 8MB we estimated to have been used in the A12. Short of analyzing the die shot and see if the structure indeed has doubled, I’m a bit skeptical and I feel it’s more likely that Apple is using a partitioning system and has possibly enabled the CPU complex to access more of the SLC. What is evident here, is the doubling of the SLC cache from 8MB to 16MB.
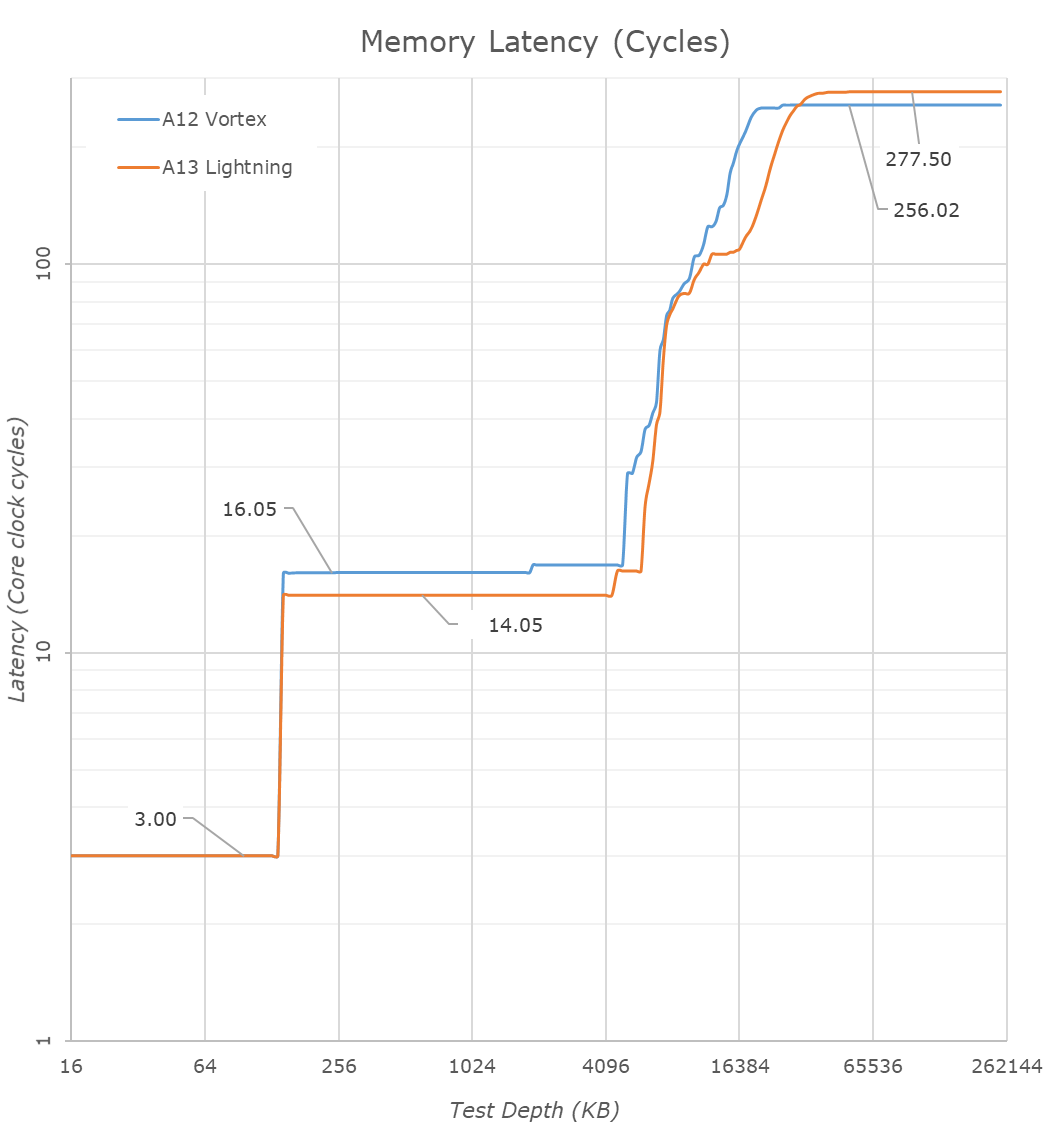
We mentioned that the Lightning cores L2 is faster now: Converting the measured latencies from nanoseconds to core cycles, we see the structural speed changes to the caches. The L1 remains at 3 cycles which is massively impressive given its 128KB size. The L2 cache has been reduced from 16 cycles down to 14 cycles, which is again extremely impressive given its purported 8MB physical size. Accounting for the core’s frequency increase, we do more noticeably see that the structural memory latency has increased a bit on the A13, adding about 21-22 cycles. It’s possible that the microarchitectural changes that made the SLC so much faster this generation had a knock-on effect in adding more total latency to DRAM.

Looking at the new Thunder cores versus last year’s Tempest microarchitecture, we see the new cache hierarchy differences. The L1D has grown from 32KB to 48KB – straightforward until now.
The L2 cache size also has evidently increased. Last year we estimated that the small core cluster had 2MB of shared L2, but was partitioned in such as way that a given core only has access to about 1.5MB, and this depth depended on the power management policy and DVFS state of the cores, appearing to only have access to 512KB when at the lowest performance states.
This year, this 1.5MB access size has seemingly increased to 2.5MB. I thus estimate the shared L2 of the small cores has increased from a physical 2MB to 3MB. Past this we’re seeing a step-wise behavior in latency up to 4MB – it’s possible this would be part of the L2E cache of the CPU complex, so in other words we’d possibly be accessing a special partition of the big core’s L2.
Update October 27th: The die shot reveals that the L2 of the Thunder cluster is half the size of the Lightning cluster L2, thus we estimate it's 4MB large in total.
In this graph we continue to see the behavior change of the A13’s SLC. At first glance it appears bigger, which still can be the case, but I rather think the CPU complex has much better access to the 4 (or more) cache slices of the SLC in this generation.
Another change of the new Thunder cores here is that we’re obviously seeing an increase in the L2 TLB capacity of the core. While the L1 TLB seems to have remained unchanged at 128 pages / 2MB, the L2 TLB has increased from 512 pages to 1024 pages – covering up to 16MB, a quite ideal size as it’s covering the depth of the SLC.
Finally, we see that the efficiency cores in the A13 this time around don’t have access to faster DRAM on their own – the memory controller remains very slow and DRAM latencies are in excess of 340ns while on the A12 the Tempest cores were able to enjoy latencies of 140-150ns. This explains some of the performance regressions of the new Thunder cores we measured earlier.
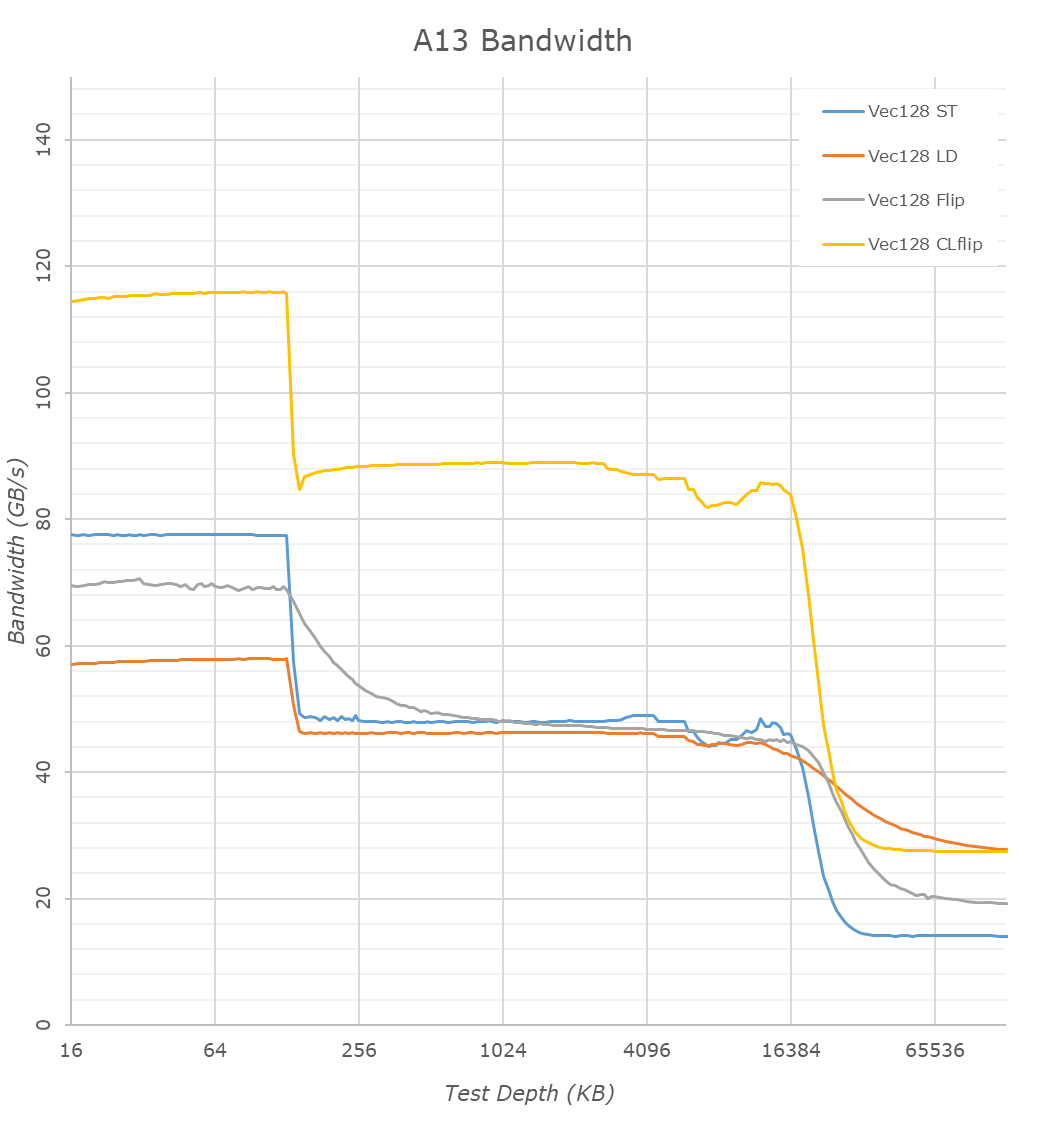
Bandwidth between the A13 and A12 doesn’t majorly differ in the L1 and DRAM regions beyond minor clock speed changes. In the L2, we notice there’s been a more noticeable increase in performance for read+writes into the same cache line, increasing performance by 25%.
It’s again in the SLC region where we see major changes – while on the A12 the bandwidth here slowly fell off in depth, the A13 is able to sustain the same bandwidth over the 16MB of system cache. It’s impressive that the bandwidth here is essentially equal to the L2 – albeit of course quite notably worse latency as we noted earlier. The smaller dips at the 8MB region is an artifact of the cache behavior between the big L2 and the SLC.
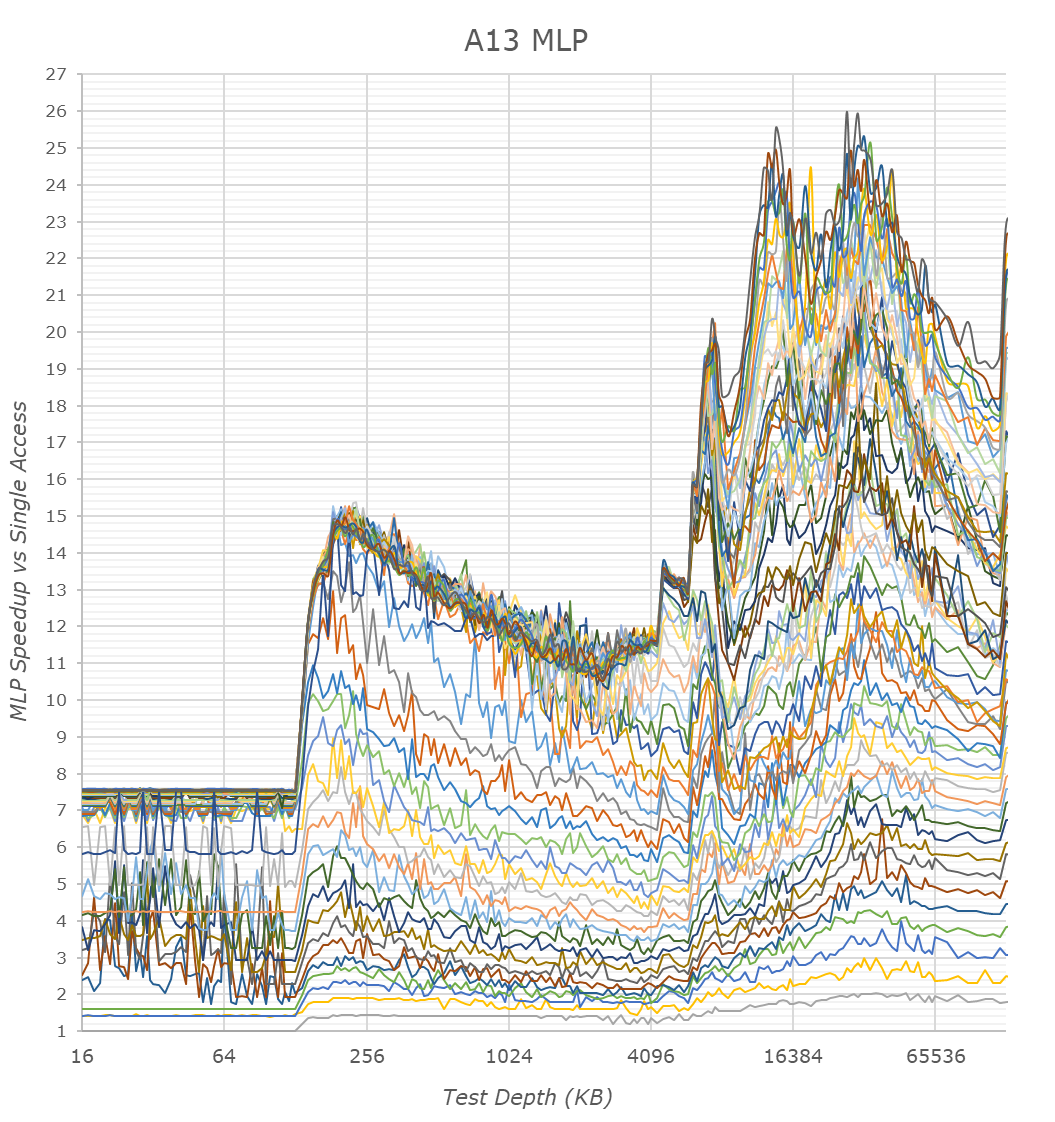
Finally, the MLP graphs showcase the memory level parallelism capacity of the CPU cores and the memory subsystem. MLP is the ability for the CPU to “park” memory requests missing the caches and to continue executing in out-of-order fashion other requests. High MLP ability is extremely important to be able to extract the most from out-of-order execution of code, which has higher memory pressure and more complex memory access patterns.
The A13 here again remains quite unique in its behavior, which is vastly more complex that what we see in any other microarchitecture. The non-linearity of the MLP speedup versus access count is something I can’t find a viable explanation for. We do see that the new A13 is a little bit better and more “even” than the A12, although what this practically means is something only Apple’s architects know. In general, Apple’s MLP ability is only second to AMD’s Zen processors, and clearly trounces anything else in the mobile space.
The overall conclusion for the A13’s memory subsystem is that Apple has evidently made very large changes to the system level cache, which is now significantly faster than what we’ve seen in the A12. The L2 cache of the big cores benefit from a 2-cycle latency reduction, but otherwise remain the same. Finally, the new Thunder efficiency cores have seen large changes with increased L1D, L2 and TLB capacity increases.








242 Comments
View All Comments
BradleyTwo - Monday, October 21, 2019 - link
My apologies if this has been disclosed already, but would it be possible to ask if Apple supplied these phones for testing?The reason I ask is that there is quite a long thread over at a popular Mac rumors forum where a number of us are concerned at the variable screen quality on the iPhone 11 Pro and Pro Max.
Many of us, myself included, have received a suboptimal screen, in that it was a dim, murky yellow display (the less polite of us have called them p-stained), while others have received screens which are not uniformly lit.
We have generally exchanged them to receive marginally better units, a few of which have been perfect, but a disappointing majority of the exchanges are often still below the apparently impressive characteristics of the displays discussed in the review.
As this is not mentioned in the various iPhone 11 Pro reviews, a number of us have formed suspicions that Apple has cherry picked the best screens to supply to reviewers.
A clarification whether Apple did indeed supply the units, or if they were bought off the shelf, would be much appreciated.
techsorz - Monday, October 21, 2019 - link
Apple calibrates each device, this is what XDR essentially is. However this will create better uniformity across displays than make them as different as you say.Dim, murky yellow is probably caused by you not disabling true-tone and auto-brightness. Otherwhise you have a very faulty unit, as this display should be bright enough to nearly burn out your retina. (Exaggeration)
Not uniformly lit could be an error, just return it in this case. Clearly Apple wouldn't supply faulty hardware to anyone on purpose, not testers or consumers.
Andrei Frumusanu - Monday, October 21, 2019 - link
These are Apple review samples, but in our experience and testing they don't differ from commercial models.BradleyTwo - Monday, October 21, 2019 - link
Thank you for the clarification. It would of course be negligent for Apple PR not to ensure reviewers receive fully tested units.I can assure you, however, that when it comes to the screen, the number of less than optimal units being sold at retail is probably higher than you might think. While these are most likely all within manufacturing tolerances for QC purposes, some of them I highly doubt Apple would send to reviewers.
Oh well, at least the 14 day return period provides the opportunity to exchange. The "screen lottery" we call it.
Andrei Frumusanu - Tuesday, October 22, 2019 - link
Apple would have to be very misleading in providing fully sealed units. It's possible that some retail units perform worse but over the years we've never really encountered such a unit.s.yu - Tuesday, October 22, 2019 - link
"It would of course be negligent for Apple PR not to ensure reviewers receive fully tested units."lol! Samsung Fold.
joms_us - Tuesday, October 22, 2019 - link
It is pity though the so-called fastest SoC is not even close to these Android phones which are typically half the speed of fastest desktops. How do you expect people to believe A13 is faster than i-9900K or Ryzen 3950X? Where GeekBiased and jurassic SP2006? LOLhttps://youtu.be/ay9V5Ec8eiY?t=514
https://youtu.be/DtSgdrKztGk?t=423
https://youtu.be/PkVW5eSXKfw?t=115
I'd say cut the crap and show us real-world results not cherry-picked worthless numbers from benchmarking tools.
Quantumz0d - Tuesday, October 22, 2019 - link
The fanboys man they are so blinded by reality, Apple was able to set a perfect world utopian dream for them. Can't fix stupid.I used to run Sultanxda kernel on my OP3 with SD820 processor the SD821 had higher clock speed over 820 but guess what OP screwed it up or Qualcomm didn't provide fix there was Clockspeed crashing at high freq so he disabled it entirely on both big and small. Guess what ? Benches took a massive hit. But UX ? Nope. Infact it improved a lot how is that possible ? I guess Spec and GB only matters right.
Pixel 3 lagged badly due to the RAM issue no one mentions all say its beautiful wonderful amazing. Guess what ? 1080P 60FPS doesn't exist as an option and its auto as Google deems. 4XL no 4K60FPS because less storage. No press mentions.
Coming to this garbage phone. iOS 13 whatever. Same icons, same springboard since 1.1.4 (I used it and JBed it) no desktop no customization to OS. All iPhones on the planet look same just like the brainwash here of ridiculous comparision of a GB (bullshit bench) and Spec score. Masterpiece of corporate koolaid.
Why don't they mention how the Audio format which records is not in Lossless but in AAC crap unlike my V30 does with the 192KHz 24Bit option in FLAC with Limiter and Gain switch or the Video mode which had full manual Pro controls or even the camera having any Manual options. All ASUS, Samsung, LG, Sony, OnePlus, Huawei offer Pro camera forget Pro Video which only LG and Sony do. But No one cares, simpletons only care about A series marketing BS.
The worst of all no Filesystem. $1000 device which doesn't even have a Filsystem usable by end user or has an option to install the apps off the AppStore. Nor any SD expansion slot to be prepared for emergency. But people are riling up and getting worked over the ARM masterrace LMAO with BGA MacBook Pro with 1 USB C port. Bonus is, to develop iOS app you must pay $99 yearly fee AND own that BGA Soldered KB/Touchpad/Battery/SSD macbook because XCode !!
The abomination design. Display mutilation for 3 years while heralding best colors best display LOL. Very funny.
And no 3.5mm jack. Because Apple wanted to make $5bn off revenue from AirPods (Higher than AMDs entire profit) guess what ? Less than 320kbps data rate LMAO. My LG V30 absolutely destroys this phone to oblivion with its ESS9218P DAC processor only found in Top motherboards from ASUS/GB/MSI. Even Vivo Nex decimates this garbage audio iPhone.
Very very funny how even Qualcomm who spent billions of dollars in R&D for their Centriq ARM server processor by even relegating the teams which worked on post 810, full custom Kryo 820 series and dumping all it out because of the Broadcom M&A (Major beneficiary was Apple due to the Hock Tan connection with Apple, he would sell out all LTE patents) impact and no profit in the ARM server market, forget logistics, capex, ROI, x86 emulation AND 64Bit x86 Emulation legacy code with a massive scale of Linux community around.
But we want ARM A series BGA processor which has world class Spec and GB score and beats Mainstream and HEDT LGA processors.
Claps !
Anand2019 - Tuesday, October 22, 2019 - link
Why are you so angry?Quantumz0d - Tuesday, October 22, 2019 - link
Fed up of the unending talk of x86 vs ARM is one hell even AT forums cpu and oc subforum. Whole thread dedicated to worship this talk.Two Apple ruined smartphones by this policy of removing jack and features while raising the price to moon, Other companies also want greed by forcing people to buy BT earphones which sound garbage, horrid longevity (Need to charge everyday) pushing people to buy trash (Beats) thus making whole market saturated with Apple agenda. Look at Google Pixel 4 they also removed offering Dongle, Samsung, OnePlus. Same thing like Apple very greedy.
Three destroyed the laptops with thin and light obsession. And soldered junk with less and less I/O.
Finally 4th - this corporation is built on American values but is a stooge to cash from China thus enabling more totalitarianship while claiming Liberty on US land. Spineless positiin.