Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics
by Dr. Ian Cutress on September 17, 2019 10:00 AM ESTA Short Detour on Mobile CPUs
For our readers that focus purely on the desktop space, I want to dive a bit into what happens with mobile SoCs and how turbo comes into effect there.
Most Arm based SoCs use a mechanism called EAS (Energy-Aware Scheduling) to manage how it implements both turbo but also which cores are active within a mobile CPU. A mobile CPU has one other aspect to deal with: not all cores are the same. A mobile CPU has both low power/low performance cores, and high power/high performance cores. Ideally the cores should have a crossover point where it makes sense to move the workload onto the big cores and spend more power to get them done faster. A workload in this instance will often start on the smaller low performance cores until it hits a utilization threshold and then be moved onto a large core, should one be available.
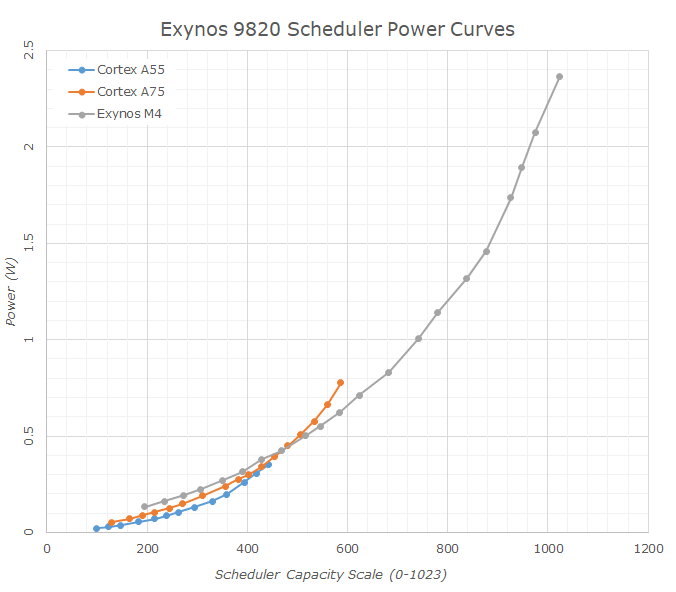
For example, here's Samsung's Exynos 9820, which has three types of cores: A55, A75, and M4. Each core is configured to a different performance/power window, with some overlap.
Peak Turbo on these CPUs is defined in the same way as Intel does on its desktop processors, but without the Turbo tables. Both the small CPUs and the big CPUs will have defined idle and maximum frequencies, but they will conform to a chip-to-chip defined voltage/frequency curve with points along that curve. When the utilization of a big core is high, the system will react and offer it the highest voltage/frequency up that curve as is possible. This means that the strongest workloads get the strongest frequency.
However, in Energy Aware Scheduling, because the devices that these chips go into are small and often have thermal limitations, the power can be limited by battery or thermals. There is no point for the chip to stay at maximum frequency only to burn in the hand. So the system will apply an Energy Aware algorithm, combined with the thermal probes inside the device, to ensure that the turbo and workload tend towards a peak skin temperature of the device (assuming a consistent, heavy workload). This power is balanced across the CPU, the GPU, and any additional accelerators within the system, and the proportion of that balance can be configured by the device manufacturer to respond to what proportion of CPU/GPU/NPU instructions are being fed to the chip.
As a result, when we see a mobile processor that advertises ‘2.96 GHz’, it will likely hit that frequency but the design of the device (and the binning of the chip) will determine how long before thermal limits kick in.








144 Comments
View All Comments
Smell This - Wednesday, September 18, 2019 - link
{ s-n-i-c-k-e-r }
BurntMyBacon - Wednesday, September 18, 2019 - link
Electron migration is generally considered to be the result of momentum transfer from the electrons, which move in the applied electric field, to the ions which make up the lattice of the interconnect material.Intuitively speaking, raising the frequency would proportionally increase the number of pulses over a given time, but the momentum (number of electrons) transferred per pulse would remain the same. Conversely, raising the voltage would proportionally increase the momentum (number of electrons) per pulse, but not the number of pulses over a given time. To make an analogy, raising the frequency is like moving your sandpaper faster while raising your voltage is like using coarser grit sandpaper at the same speed.
You might assume that if the total number of electrons are the same, then the wear will be the same? However, there is a certain amount of force required to dislodge an atom (or multiple atoms) from the interconnect material lattice. Though the concept is different, you can simplistically think of it like stationary friction. Increasing the voltage increases the force (momentum) from each pulse which could overcome this resistance where nominal voltages may not be enough. Also, increasing voltage has a larger affect on heat produced than increasing frequency. Adding heat energy into the system may lower the required force to dislodge the atom(s). If the nominal voltage is unable or only intermittently able to exceed the required force, then raising the frequency will have little effect compared to raising the voltage. That said, continuous strain will probably weaken the resistance over time, but it is likely that this still less significant than increasing voltage. Based on this, I would expect (read my opinion) four things:
1) Electron migration becomes exponentially worse the farther you exceed specifications (Though depending on where your initial durability is it may not be problematic)
2) The rate of electron migration is not constant. Holding all variables constant, it likely increases over time. That said, there are likely a lot of process specific variables that determine how quickly the rate increases.
3) Increasing voltage has a greater affect on electron migration than frequency. Increasing frequency alone may be considered far more affordable from a durability standpoint than increases that require significant voltage.
4) Up to a point, better cooling will likely reduce electron migration. We are already aware that increased heat physically expands the different materials in the semiconductor at different rates. It is likely that increased heat energy in the system also makes it easier to dislodge atoms from their lattice. Reducing this heat build-up should lessen the effect here.
Some or all of these may be partially or fully incorrect, but this is where my out of date intuition from limited experience in silicon fabrication takes me.
eastcoast_pete - Wednesday, September 18, 2019 - link
Thanks Ian! And, as mentioned, would also like to hear from you or Ryan on the same for GPUs. With lots of former cryptomining cards still in the (used) market, I often wonder just how badly those GPUs were abused in their former lifes.nathanddrews - Tuesday, September 17, 2019 - link
My hypothesis is that CPUs are more likely to outlive their usefulness long before a hardware failure. CPUs failing due to overclocking is not something we hear much about - I'm thinking it's effectively a non-issue. My i5-3570K has been overclocked at 4.2GHz on air for 7 years without fault. I don't think it has seen any time over 60C. That said, as a CPU, it has nearly exhausted its usefulness in gaming scenarios due to lack of both speed and cores.What would cause a CPU to "burn out" that hasn't already been accounted for via throttling, auto-shutdown procedures, etc.?
dullard - Tuesday, September 17, 2019 - link
Thermal cycling causes CPU damage. Different materials expand at different rates when they heat, eventually this fatigue builds up and parts begin to crack. The estimated failure rate for a CPU that never reaches above 60°C is 0.1% ( https://www.dfrsolutions.com/hubfs/Resources/servi... ). So, in that case, you are correct that your CPU will be just fine.But, now CPUs are reaching 100°C, not 60°C. That higher temperature range doubles the temperature range the CPUs are cycling through. Also, with turbo kicking on/off quickly, the CPUs are cycling more often than before. https://encrypted-tbn0.gstatic.com/images?q=tbn:AN...
GreenReaper - Wednesday, September 18, 2019 - link
Simple solution: run BOINC 24/7, keeps it at 100°C all the time!I'm sure this isn't why my Surface Pro isn't bulging out of its case on three sides...
Death666Angel - Thursday, September 19, 2019 - link
Next up: The RGB enabled hair dryer upgrade to stop your precious silicon from thermal cycling when you shut down your PC!mikato - Monday, September 23, 2019 - link
Now I wonder how computer parts had an RGB craze before hair dryers did. Have there been andy RGB hair dryers already?tygrus - Saturday, September 28, 2019 - link
The CPU temperature sensors have changed type and location. Old sensors were closer to the surface temperature just under the heatsink (more of an average or single spot assumed to be the hottest). Now its the highest of multiple sensors built into the silicon and indicates higher temperatures for the same power&area than before. There is always a temperature gradient from the hot spots to where heat is radiated.eastcoast_pete - Wednesday, September 18, 2019 - link
For me, the key statement in your comment is that your Sandy Bridge i7 rarely if ever went above 60 C. That is a perfectly reasonable upper temperature for a CPU. Many current CPUs easily get 50% hotter, and that's before any overclocking and overvolting. For GPUs, it even worse; 100 - 110 C is often considered "normal" for "factory overclocked" cards.