Hot Chips 31 Analysis: In-Memory Processing by UPMEM
by Dr. Ian Cutress on August 19, 2019 3:15 PM EST
One of the key critical future elements about this world of compute is moving data about. Moving data requires power, to the point where calling data from memory can consume more power than actually doing ‘compute’ work on it. This is why we have caches, but even these require extensive management built in to the CPU. For simple operations, like bit-shifts or AND operations, the goal is to move the ability to do that compute onto the main DRAM itself, so it doesn’t have to shuttle back and forth. This year at Hot Chips, UPMEM is one of the first companies to showcase their new technology.
For anyone that has done any form of general purpose compute, pushing a bunch of inputs through an algorithm to get a result, and for those that have written the code, there are typically two high-level mental stages to conquer: first is getting it to work, and second is optimizing it. The algorithm needs to produce the correct result, and the faster the better – a slow correct result often isn’t useful, and a fast incorrect result is useless. If it can be done in less power, than that also decreases overhead.
The idea behind In-Memory Processing, or ‘Processing In-Memory’, is that a number of those simple integer or floating point operations should be done while the memory is still in DRAM – no need to cart it over to the CPU, do the operation, and then send it back. If the data can stay there and be updated, this saves time and power without affecting the result. Alternatively, perhaps compute on the CPU can be reduced if results are sent back out to main memory and a final XOR is applied to the data in memory. That frees up the main CPU core to do other compute related things, or reduces the effective memory bandwidth should it be a limiting factor.
What UPMEM has done is develop a data processing unit (DPU) that is built into the DRAM chip itself, on the DRAM process node. Each DPU has access to 64 MB of DRAM, and has the equivalent of 1 GB/s bandwidth to that memory. The DPU is built on a clean 32-bit ISA with a raft of optimizations, such 0-cycle conditional jmps, combined SHIFT+X instructions (such as SHIFT+ADD or SHIFT+SUB), basic logic instructions, shift and rotate instructions. The programming model is such that C-based libraries are in play taking care of all the common issues, and UPMEM expects for most apps for it to require a few hundred lines of code and a team of a handful of people need only take 2-4 weeks to update the software.
The big numbers that UPMEM are quoting involve better TCO, better ROI, and a potential target market of $10B. We’ll go through these in due course.
Processing In-Memory DRAM, or PIM-DRAM
(Personally I prefer the name PIM-DIMM, but oh well)
What UPMEM is proposing is a standard DDR4 RDIMM like product for which each 64 MB of memory has access to one of its DPUs. The DPU is built into the DRAM itself, using the manufacturing node that the memory is made in. For example, UPMEM is promoting that it is making a 4 Gb DDR4-2400 chip to be used in modules that embeds 8 DPUs in 512 MB, with the DPUs running at 500 MHz. UPMEM plans to put 16 of these 4 Gb chips onto a single DDR4 RDIMM module, providing an 8 GB module with 128 DPUs inside.
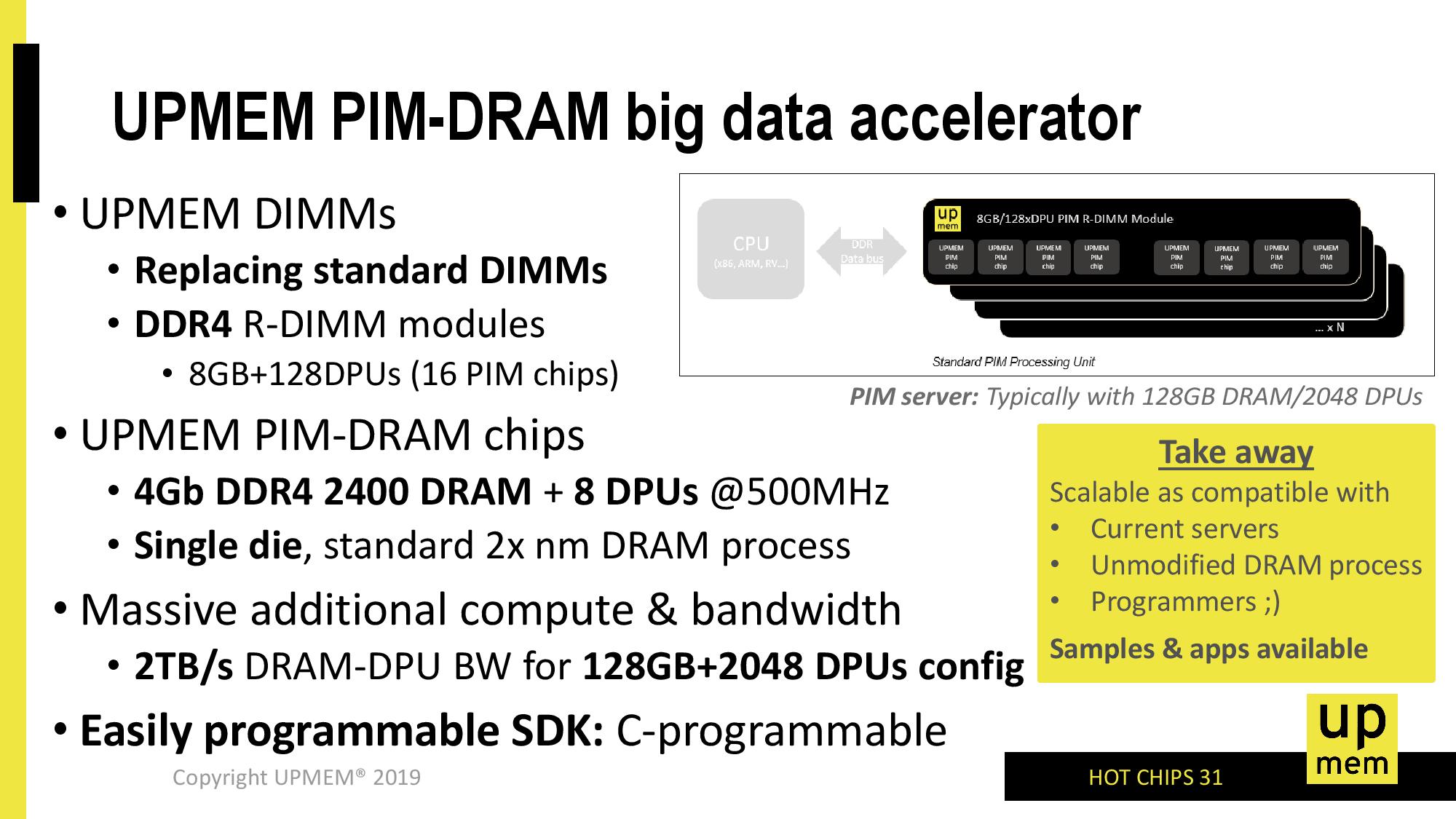
The goal is to eventually produce 128 GB modules with 2048 DPUs in total. At an effective 1 GB/s bandwidth between a DPU and its 64 MB of memory, this would imply an effective 2 TB/s bandwidth between the DPUs and memory. This is needed due to the way the DPU works, which is explained below.
The processor and technology are patented, but UPMEM has stated that they are working with a memory vendor on a 20-nm class process. Adding in the DPU cores adds a very negligible amount of die area, and can be enabled within 2-3 metal layers, as the logic is a magnitude less dense than a leading edge logic implementation. The idea is to achieve a total energy efficiency of 10x combined with scalability, compared to the leading CPU implementations.
Currently UPMEM has software simulations and hardware FPGA verification simulators for customers – in fact, interested parties can emulate the UPMEM platform on an AWS f1.16x large instance. Actual PIM-DRAM module samples are shipping to high profile customers in Q3, with a plan to ramp through the next year as more parties are interested and get on-board. Citing performance examples, UPMEM has stated that they have seen speedups of 22x—25x on Genomics pattern matching, an 18x speed up in throughput for database index searching at 1/100th the latency, and an 14x TCO gain for index search applications.

On the side of cost, UPMEM hasn’t stated how much it plans to sell its technology for, but promise to be a marginal cost compared to alternative solutions. In one presentation, the company stated that their solution can replace a potential $40000 server with a $400 enhanced memory solution, noting that using PIM has knock-on effects for software licensing, datacenter space, and power consumption/efficiency.
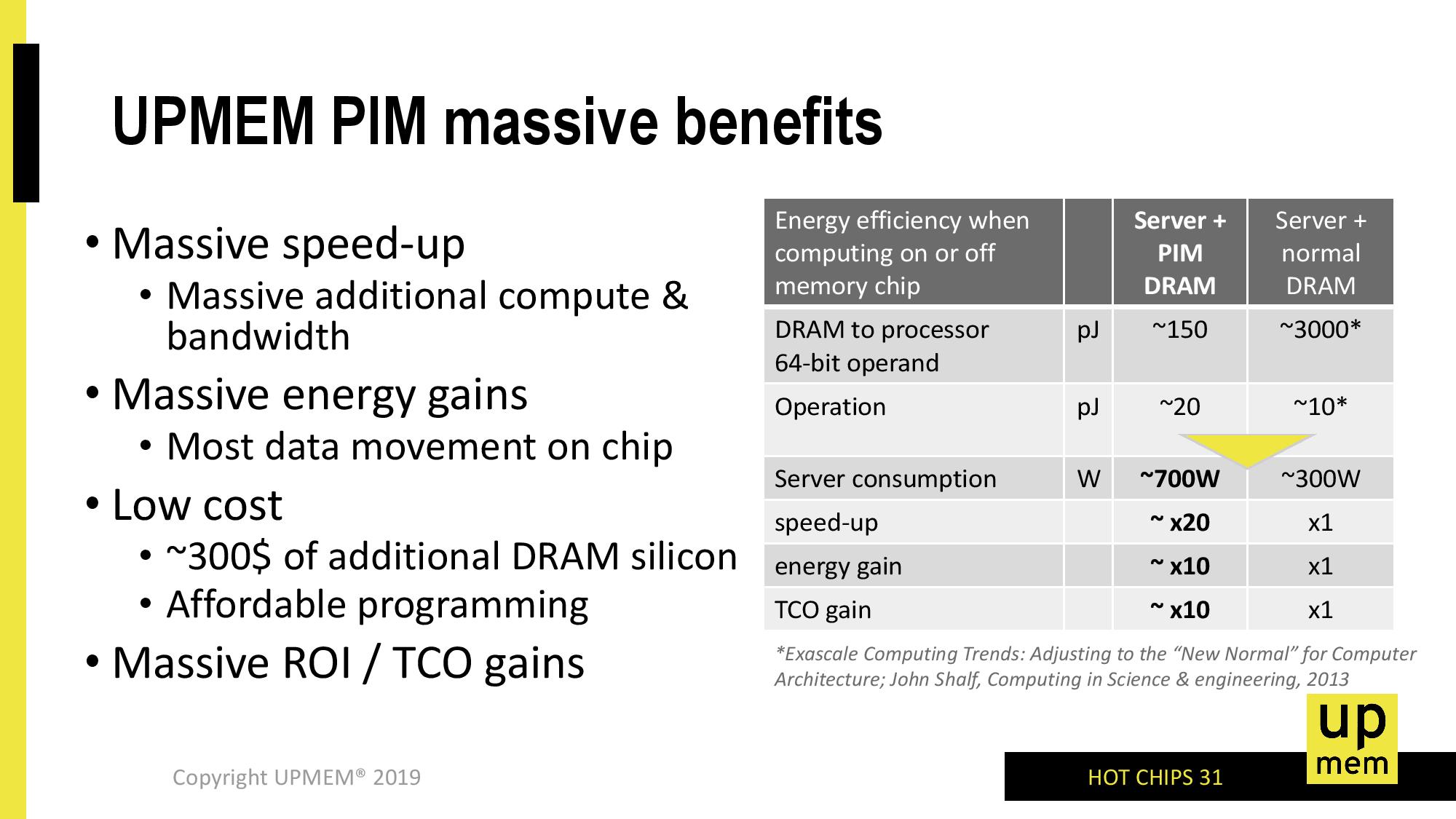
UPMEM puts some data on that power consumption. In this slide, the company compares two servers, one with PIM-DRAM and one without. In this case, a ‘DRAM to processor 64-bit operand’ recall requires 3000 pJ on a regular server, pulling the data out of DRAM and through to the caches, whereas the same operation on PIM-DRAM where it only has to move the data onto a DPU takes only 150 pJ of energy. The operation itself on the DPU actually requires 2x the power (20 pJ compared to 10 pJ), but the overall gain in power efficiency is 170 pJ vs 3010 pJ, or just under 20x.
One thing that this slide states that might be confusing is the server power consumption – the regular server is listed as only 300W, but the PIM solution is up to 700W. This is because the power-per-DRAM module would increase under UPMEM’s solution.
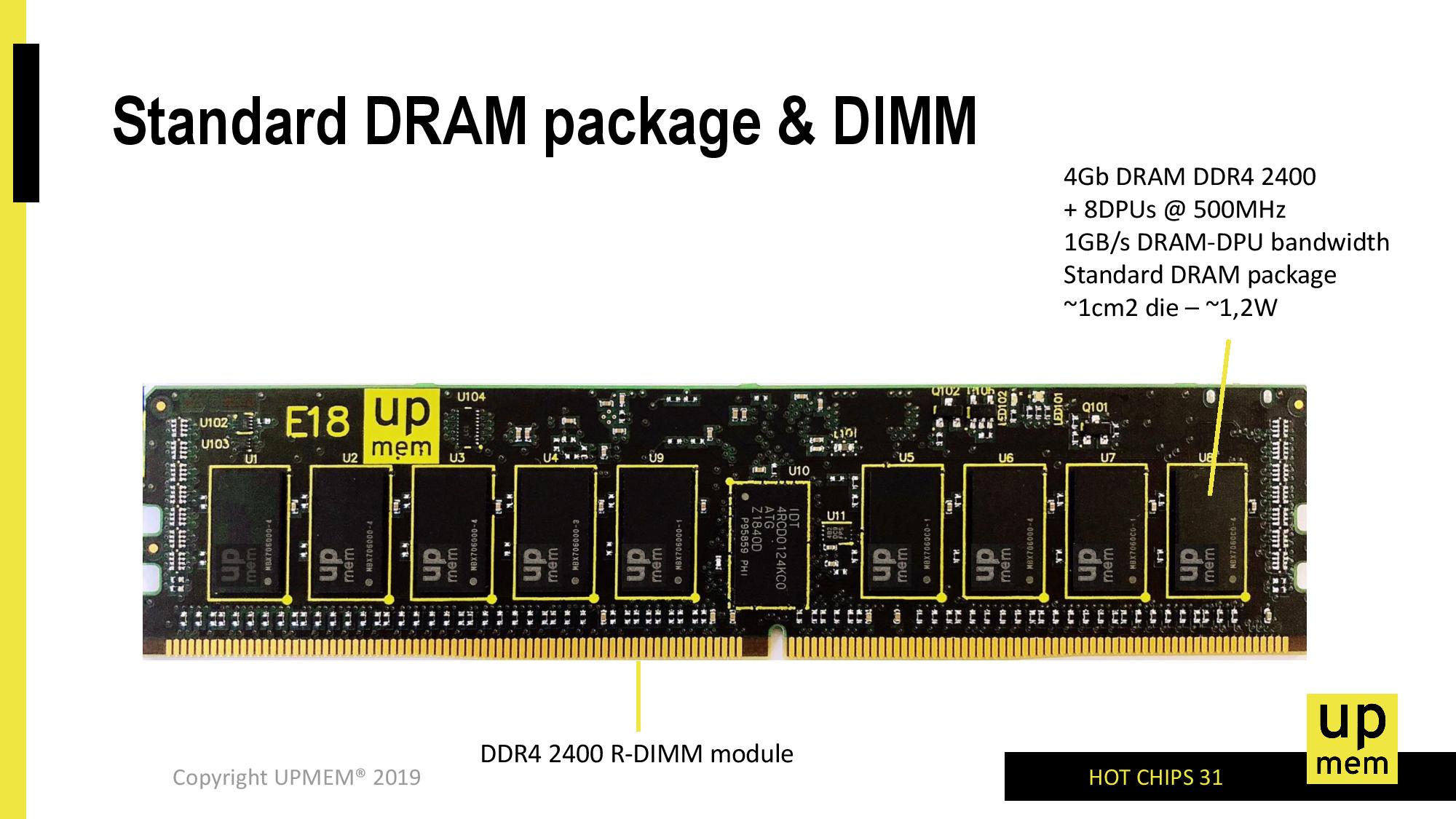
The module that UPMEM is proposing as its first product is that 8 GB DDR4-2400 module mentioned previously, with 128 DPUs each covering 64 MB of memory and running at 500 MHz. For a single 4 Gb die (there are 16 of them in an 8 GB module, 18 for RDIMM ECC), we are still at a regular 1 cm2 die size but the power required per chip is ~1.2 watts.
If we go into all 16/18 chips, we can see that each 8GB module is going to be in the 19.2-21.6 watts. That’s a lot of power for DRAM, and actually pushes up against the limit of what a DDR4 slot is often rated for. To put some perspective here, Intel’s 512 GB Optane module has an 18 W running mode for servers that can cool that much, but can run as low as 12 W. UPMEM hasn’t stated if it offers the ability for its customers to scale down the power per module by reducing the DPU frequency.
UPMEM’s goal is to replace DRAM modules in servers with PIM-DRAM modules as drop-in replacements. The company states that the DDR4 interface isn’t the best for this sort of thing, but they have worked around it. In one presentation, the company notes that at present there needs to be non-PIM-DRAM installed at a minimum for an OS.








38 Comments
View All Comments
azazel1024 - Wednesday, August 21, 2019 - link
I prefer General In-Memory Processing. Just be careful of Last-level In-Memory Processing. I hear it can handicap your system if implemented wrong.winkingchef - Monday, August 19, 2019 - link
(This needs a #HotChips keyword tag)IMO this model of computing is the way the industry needs to go (pushing bits around from storage/memory to compute is wasteful of power).
HOWEVER, i also believe the adoption of this technology will be held back by the current mechanical/thermal assumptions around DRAM DIMMS which also drive electricals (spacing DIMMs out will create need for higher drive strength from the full rank of them to CPU). Someone will need to take a risk to adopt this on their server architecture.
Threska - Monday, August 19, 2019 - link
Basically diffusing a CPU into the space of a memory stick. Might be better to take the most used operations* in code and put those there.*Not to be confused with instructions. Too fine grained.
Elstar - Monday, August 19, 2019 - link
So many questions: what’s the security model? What’s the coherency model? How does virtual memory or virtualization in general interact with this? What happens when one DPU program needs data outside of its 64 MiB region?name99 - Saturday, August 24, 2019 - link
Yeah, these two issues (security and concurrency) are the immediate sticking points, and saying that a C-library hides them doesn't help much.An additional problem that hasn't been raised is the issue of physical address bit swizzling. Obviously this work happens at the physical address level, not virtual address; but it's worse than that. Right now physical address bits are rearranged in the memory to maximize DRAM utilization across all possible channels. So very low bits will target different memory controllers, then slightly less low bits will target ranks, and so on.
Meaning that I don't understand how this "No DPU sharing" provides real value. IF DPUs can only access their own data with no DPU cross traffic, then you're limited in how much damage you can do (but you're also massively limited in how much of value you can do...) But if DPUs can write to each other (necessary if you're going to support blits and memcopy, which would seem to be the first order win) then who cares about this "no sharing", how does it help?
Onur Mutlu's solution is much less sophisticated, but also seems a lot more practical. All that solution does is perform on-DRAM blits and memcopies, in essence by allowing the CPU to send instructions through the memory controller saying copy DRAM page at address A to DRAM page at address B. This gets you most of the win, while providing no security weirdness, and a very obvious chokepoint for how you perform the virtual to (controller, rank, bank, page) mapping rather than being a nightmare for generic code.
abufrejoval - Monday, August 19, 2019 - link
When I invented the concept perhaps ten years ago, I called it ‘computing memory’ and I was so glad, I found no matches for it on Google. But like with many other of my ideas, plenty of others had been there and actually done something about it, too.I was somewhat inspired by the Weitek Floating Point co-processor, an Intel i387 competitor which used a 64K memory segment while it only had perhaps 32 registers: It used the lowest significant address bit to encode one operation while writing the data, perhaps another while reading it: It very neatly solved the memory bottleneck between the CPU and the co-processor at the time, offering something like 4x the performance of Intel’s own.
Content addressable memory and the Linda Tuple space were other inspirations and I always wanted SQL-RAM, where the I’d put the WHERE clause into the address bits and then only retrieve matching data 😊.
I liked Micron's Automata Processor a lot, because it was a nice programming paradigm, good balance between problem solving power and logic overhead and excellent for formal proofs and unassailable by the likes of return oriented programming. Unfortunately they shelved that project.
HBM memory chip stacks offer free real-estate below the DRAM cells on the silicon die carrier, much like offices on the ground floor of a high-rise building with lots of elevators for the silicon tru vias (TSV). Even if the die carrier would be manufactured at a lower density, you’d have ample space for some simple logic at bandwidths much bigger than the CPU behind the chip multiplexing memory bus. I believe SK Hynix was at one point begging for engineers to come forward with ideas what to put there.
When the HP Memristor was supposed to offer 1000 layers and density at linear cost, it became very clear that general purpose CPUs simply wouldn’t be able to take advantage of that, much like a Morris Minor with 1000 BHP.
UPMEM is French I believe, I’ve heard about them for a long time, never seen a working chip yet. But computing memory is one of the few escape routes out of the von Neuman bottleneck.
abufrejoval - Monday, August 19, 2019 - link
Another idea was to use to expand on the row buffer also used for refresh. Use dual or tertiary buffers an a 'row ALU' that would operate on the entire memory row as a whole, e.g. for matching bit or byte patterns, then use some address bits to select transparent or operational access and write/modify the ALU row buffers.SaberKOG91 - Monday, August 19, 2019 - link
You didn't invent the idea: https://ieeexplore.ieee.org/document/592312I'm sure there are even early examples of this, but Patterson et. al were pretty prophetic in this arena.
abufrejoval - Tuesday, August 20, 2019 - link
Of course, I invented it, and all on my own, too!But as I mentioned (with a bit of irony between the lines) and you noticed, I just didn't invent it first nor did I manage to put it into physical implementation.
It's rather obviously the only open avenue of escape so idea duplication is natural.
I am actually more astonished at the lack of adoption over the last years, but silicon economics is still a game of scale.
But perhaps more importantly, those companies who's rising computing-power vs. value-of- computeratio is under the strongest pressure (GAFA/BATX), have found ways to push out the energy cost onto the client devices.
SaberKOG91 - Tuesday, August 20, 2019 - link
It has nothing to do with adoption or scale. The materials science for modern memory technologies took a long time to catch up, some of it didn't even exist until around decade ago, and only caught up because CMOS process tech lagged and slowed down the progress of everything else.It isn't selfish to push computing to client devices. These devices are faster to adopt optimized accelerators because they are now mostly mobile and battery restricted, which saves a tremendous amount of power overall, not just in the data-center.