The Ice Lake Benchmark Preview: Inside Intel's 10nm
by Dr. Ian Cutress on August 1, 2019 9:00 AM EST- Posted in
- CPUs
- Intel
- GPUs
- 10nm
- Core
- Ice Lake
- Cannon Lake
- Sunny Cove
- 10th Gen Core
Section by Andrei Frumusanu
SPEC2017 and SPEC2006 Results (15W)
SPEC2017 and SPEC2006 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparsion. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by our own Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing is good enough. SPEC2006 is deprecated in favor of 2017, but remains an interesting comparison point in our data. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates from our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 8.0.0-svn350067-1~exp1+0~20181226174230.701~1.gbp6019f2 (trunk)
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions. Despite ICL supporting AVX-512, we have not currently implemented it, as it requires a much greater level of finesse with instruction packing. The best AVX-512 software uses hand-crafted intrinsics to provide the instructions, as per our 3PDM AVX-512 test later in the review.
For these comparisons, we will be picking out CPUs from across our dataset to provide context. Some of these might be higher power processors, it should be noted.
SPECint2006
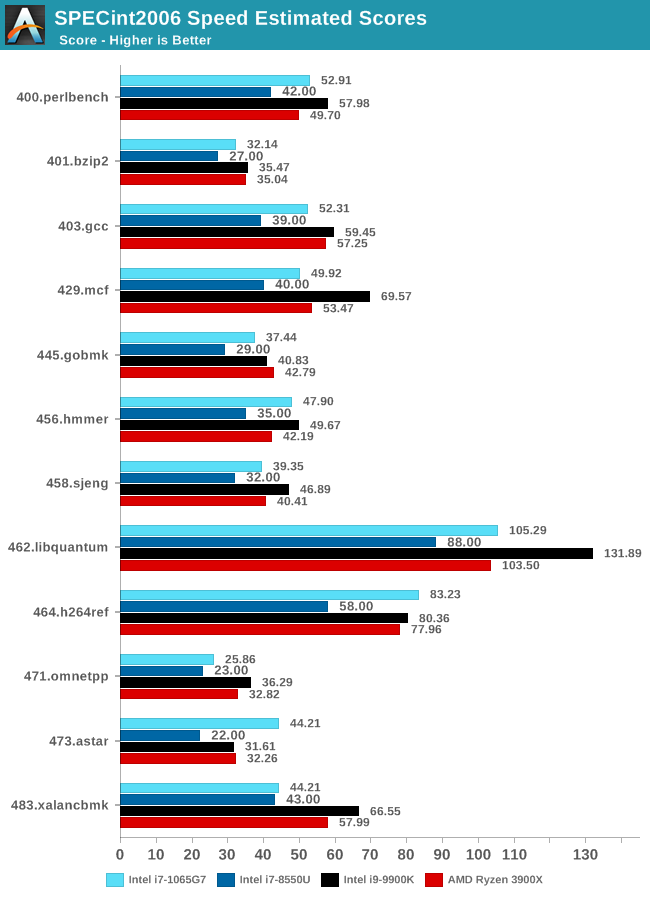
Amongst SPECint2006, the one benchmark that really stands out beyond all the rest is the 473.astar. Here the new Sunny Cove core is showcasing some exceptional IPC gains, nearly doubling the performance over the 8550U even though it’s clocked 100MHz lower. The benchmark is extremely branch misprediction sensitive, and the only conclusion we can get to rationalise this increase is that the new branch predictors on Sunny Cove are doing an outstanding job and represent a massive improvement over Skylake.
456.hmmer and 464.h264ref are very execution bound and have the highest actual instructions per clock metrics in this suite. Here it’s very possible that Sunny Cove’s vastly increased out-of-order window is able to extract a lot more ILP out of the program and thus gain significant increases in IPC. It’s impressive that the 3.9GHz core here manages to match and outpace the 9900K’s 5GHz Skylake core.
Other benchmarks here which are limited by other µarch characteristics have various increases depending on the workload. Sunny Cove doubled L2 cache should certainly help with workloads like 403.gcc and others. However because we’re also memory latency limited on this platform the increases aren’t quite as large as we’d expect from a desktop variant of ICL.
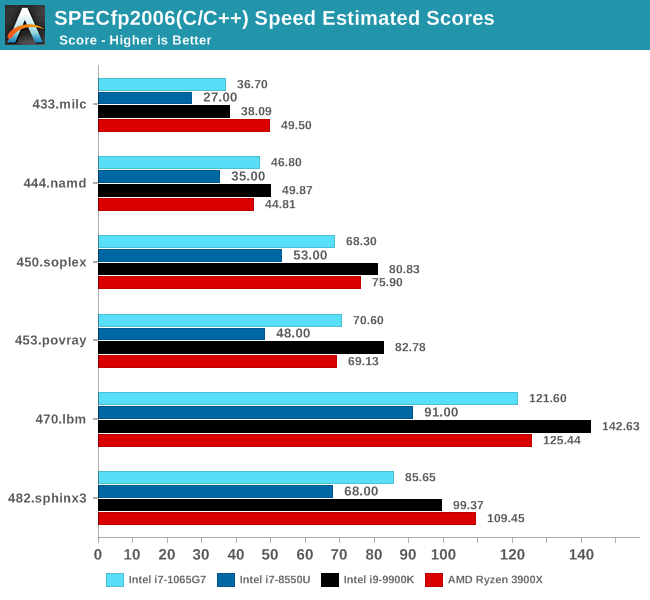
In SPECfp2006, Sunny Cove’s wider out-of-order window can again be seen in tests such as 453.povray as the core is posting some impressive gains over the 8550U at similar clocks. 470.lbm is also instruction window as well as data store heavy – the core’s doubled store bandwidth here certainly helps it.
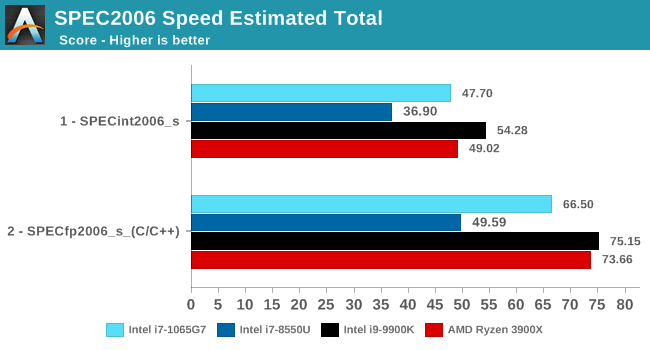
Overall in SPEC2006, the new i7-1065G7 beats a similarly clocked i7-8550U by a hefty 29% in the int suite and 34% in the fp suite. Of course this performance gap will be a lot smaller against 9th gen mobile H-parts at higher clocks, but these are also higher TDP products.
The 1065G7 comes quite close to the fastest desktop parts, however it’s likely it’ll need a desktop memory subsystem in order to catch up in total peak absolute performance.
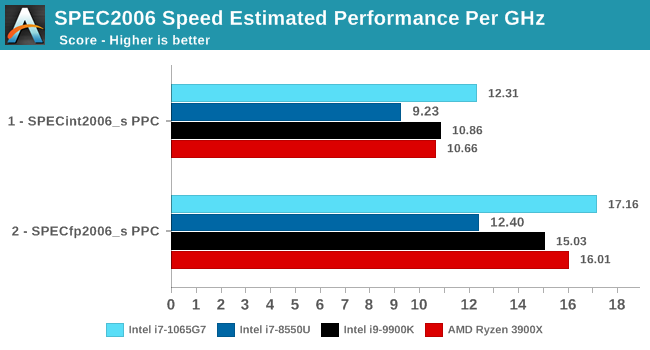
Performance per clock increases on the new Sunny Cove architecture are outstandingly good. IPC increases against the mobile Skylake are 33 and 38% in the integer and fp suites, though we also have to keep in d mind these figures go beyond just the Sunny Cove architecture and also include improvements through the new LPDDR4X memory controllers.
Against a 9900K, although apples and oranges, we’re seeing 13% and 14% IPC increases. These figures likely would be higher on an eventual desktop Sunny Cove part.
SPEC2017
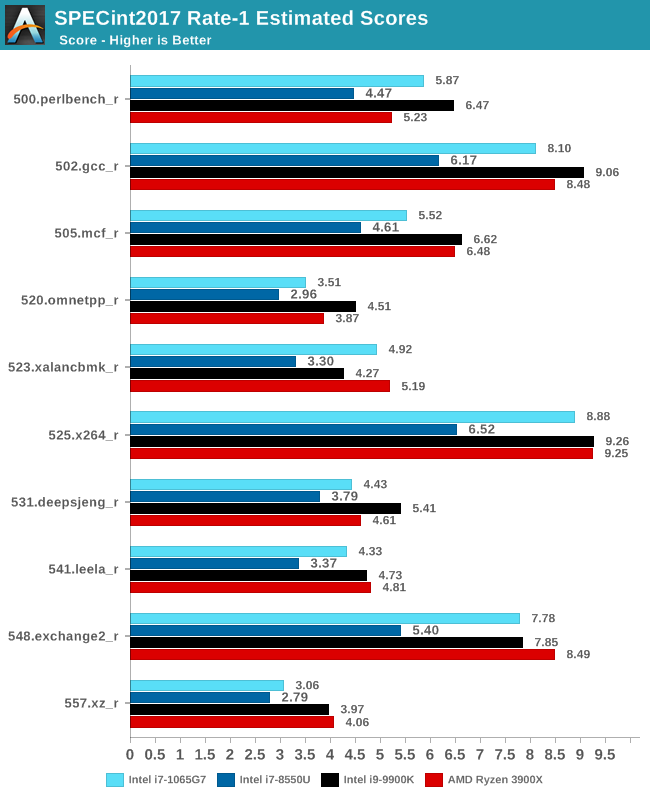
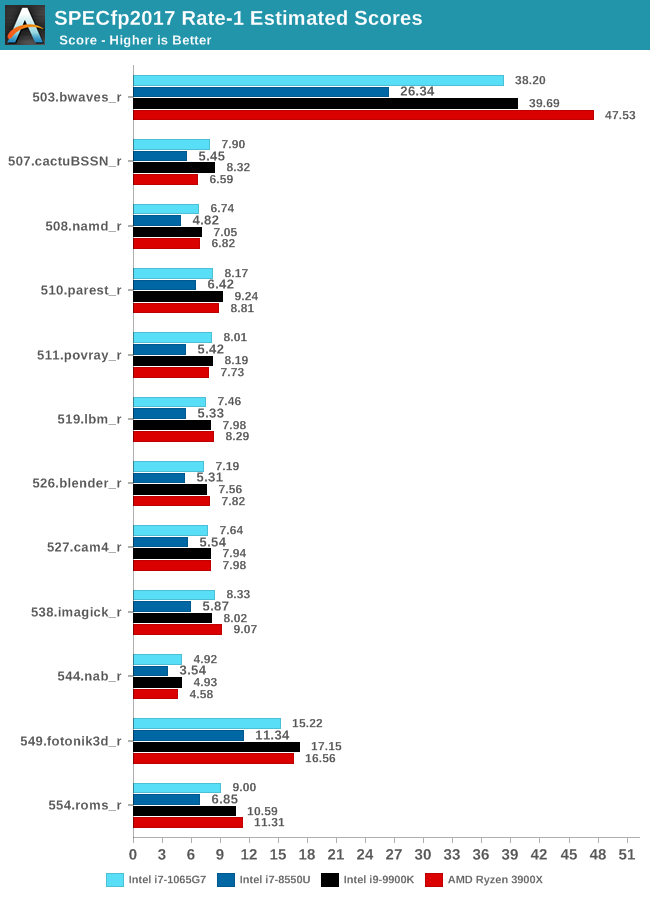
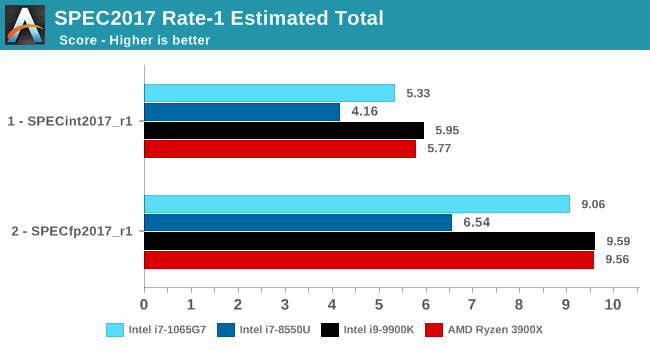
The SPEC2017 results look similar to the 2006 ones. Against the 8550U, we’re seeing grand performance uplifts, just shy of the best desktop processors.
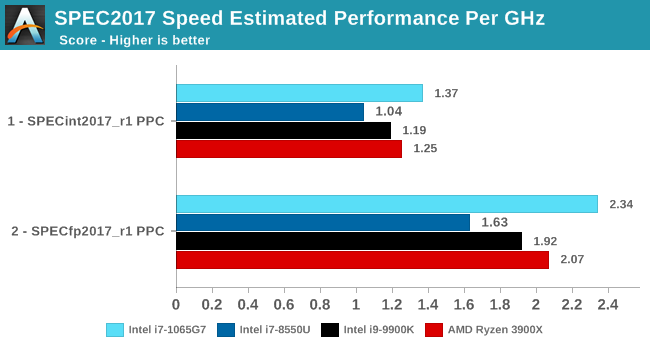
Here the IPC increase also look extremely solid. In the SPECin2017 suite the Ice Lake part achieves a 14% increase over the 9900K, however we also see a very impressive 21% increase in the fp suite.
Overall in the 2017 suite, we’re seeing a 19% increase in IPC over the 9900K, which roughly matches Intel’s advertised metric of 18% IPC increase.








261 Comments
View All Comments
Fulljack - Thursday, August 1, 2019 - link
lpddr4 would make it higher priced and stuck in premium device, as it's a soldered ram.RSAUser - Friday, August 2, 2019 - link
I think the commenter means DDR4L, low powered SO-DIMM and not the usual phone/tablet soldered RAM.Rudde - Thursday, August 1, 2019 - link
There are rumors (check AT forums) about a Gen 12 (ice lake is 11) discrete gpu with 512 EUs (arctic sound). I believe 64 EUs is confirmed max on Ice lake, but the generation after that (Tiger lake?) might have more.Mr Perfect - Thursday, August 1, 2019 - link
I notice that these parts all have Hyper threading. Has Intel addressed their security concerns with HT in Ice Lake, or do they see the benefits of HT to be greater then the risks in the mobile space?djayjp - Thursday, August 1, 2019 - link
And what about Zombieload...? Or was that just quietly swept under the rug?justaviking - Thursday, August 1, 2019 - link
QUOTE: "After attending the event, to which fewer than 10 press were invited, I now understand why. Some of the press invited didn’t have OS images, didn’t bring benchmarks with them, and were quite happy to go along with the flow. Intel provided benchmarks like Geekbench and 3DMark, which those press with their audiences were happy to run. I came prepared with both a new 1903 OS image and my benchmark suite, ready to rock and roll."And that is why we love AnandTech. :)
justaviking - Thursday, August 1, 2019 - link
And QUOTE: "It was clear that some of the press in attendance only needed a day (or half a day), but for what we do at AT, then two days would be better."Thank you for the article, and for doing the best you could in the time available.
ManDaddio - Thursday, August 1, 2019 - link
Well I'm glad that we got a little bit more looking to this part of Intel's 10nm. I'm looking forward to the next iteration to be honest.Actually I was more interested in the features of these new Intel laptops.
The benchmarks as you stated are just surface stuff until you can actually truly spend a while testing these things when they come out.
All the rave right now in some circles is AMD but I always liked Intel laptops for their features as well as performance.
And I have owned a couple AMD laptops. They were good and did the job but my Intel laptops were always much better. That's my experience.
I understand the challenges of putting an article like this out to the public who complains a lot or just wants to troll. Thanks for sharing.
Bulat Ziganshin - Thursday, August 1, 2019 - link
>AMD for Zen 2 decided to halve the L1-D, double increase the L1-D associativityit was L1-I cache
Drumsticks - Thursday, August 1, 2019 - link
In terms of pure performance, Icelake is definitely let down by it's available frequency. It's in bad need of a 10nm++ process or a backport to 14nm.It was a good idea to release it for laptops though, I think. Laptops definitely are about more than just the CPU, and the overall experience the Icelake featureset enables might actually be a good selling point.
I'd love to see an Icelake based microarchitecture released on Intel 14+++ though. Even though 14+++ has been around forever, I think it's still a good node. It's still completely untouched by any other node in frequency, power consumption isn't as important to desktop users, and the node must be so optimized by now that costs are good even with bigger dies.