NVMe 1.4 Specification Published: Further Optimizing Performance and Reliability
by Billy Tallis on June 14, 2019 1:00 PM ESTNVM Sets and Endurance Groups
NVM Sets and Endurance Groups are two new high-level organizational constructs for managing pools of storage that are larger than an individual NVMe namespace. Since support for multiple namespaces is itself largely reserved for high-end enterprise SSDs, some of the features that depend on NVM Sets or Endurance Groups only make sense for multi-port drives, virtualized environments or NVMe over Fabrics arrays—situations where one NVMe controller is behaving like or providing access to multiple drives. However, some of these new features are still useful even on drives that only provide a single endurance group containing a single NVM set.
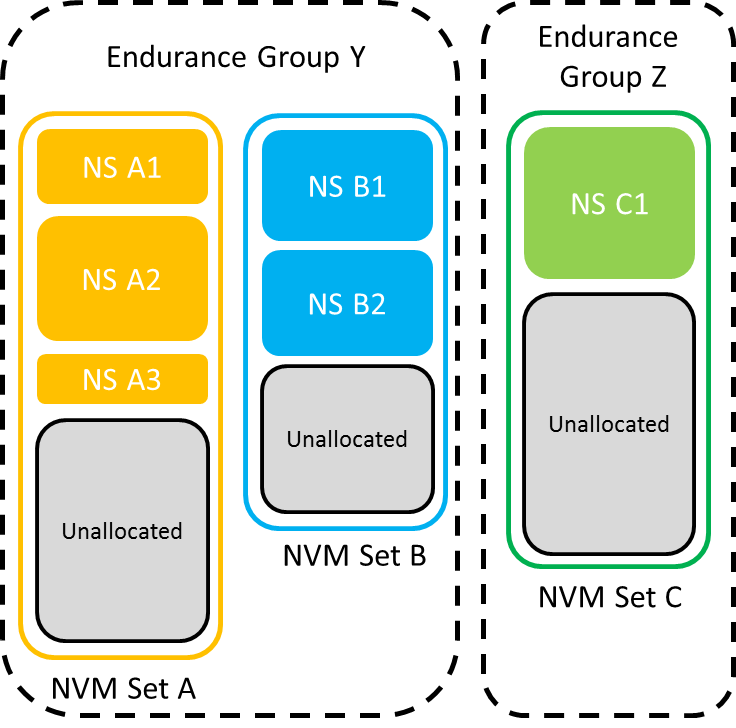
An Endurance Group is a collection of NVM Sets, which consist of namespaces and unallocated storage. Each endurance group is a separate pool of storage for wear leveling purposes. They have their own dedicated pool of spare blocks, and the drive reports separate wear statistics for each endurance group. On drives with more than one endurance group, it will be possible to completely wear out one endurance group and cause it to go read-only while other endurance groups remain usable.

Marvell's dual-chip NVMe controller architecture, a great candidate for multiple endurance groups
A drive can be designed to map specific NAND dies or channels to different NVM sets or endurance groups, essentially splitting it into multiple relatively independent drives. This can not only provide for separation of wearout, but also rigidly partitioning performance. Cloud hosting providers can put VMs from separate customers on different NVM sets or endurance groups to ensure that a busy workload from one customer doesn't hurt the latency experienced by another.
Predictable Latency Mode
The new Predictable Latency Mode feature allows the host to temporarily pause any background work the SSD controller is performing, ensuring that there is nothing to get in the way of immediately processing new IO commands arriving from the host system. This allows drives to offer their best-case and most consistent performance. SSDs cannot operate in this mode indefinitely, and will eventually need to leave deterministic mode to catch up on background work. The drive provides running estimates of how long it can remain in a deterministic window before it will have to switch itself back to non-deterministic performance, in terms of time and in terms of how many more 4kB random reads and optimal-sized writes it can handle deterministically.
Predictable Latency Mode will typically be used in environments where the host software can load-balance across multiple drives. High-priority IO can be directed to drives that are currently in a deterministic window, and drives that are in a non-deterministic window can either be left alone to catch up on background work, or used to handle low-priority IO. Each individual drive in the pool will alternate between deterministic and non-deterministic operation, and the timing of these windows will depend on the workload. If the load balancer is working well, it will stop issuing latency-sensitive IO to a drive and manually take it out of deterministic mode before the drive reaches its limit. Drives can be configured to provide a warning at a customizable threshold before the limits are reached, so host systems won't need to constantly check the status indicators to see whether the drive is close to leaving its deterministic window. Predictable Latency Mode is configured on a per-NVM Set basis, so drives that provide multiple sets can have some in each mode at any given time and perform load balancing between NVM Sets.

This isn't the first NVMe feature for controlling when the drive performs background work: NVMe 1.3 added the Non-Operational Power State Permissive Mode feature so that host systems could ask drives not do background work when in a low-power idle state. The intent here is to defer background work while running on battery power or with the system's fans off, and this feature does not affect background work while the drive is in an active power state.
Submission Queue Associations
NVMe SSDs typically support multiple command submission and completion queues. Currently, the main use case for this is to give each CPU core its own queues so that no core-to-core synchronization is necessary at the driver level to perform ordinary IO. There's also been recent work on the Linux NVMe driver to add support for using queues for specialized purposes, such as having dedicated queues for high-priority commands that will be polled for completion instead of waiting for an interrupt, or having separate queues per core for read and write commands. NVMe 1.4 and Predictable Latency Mode add another potential use case for multiple queues: associating a queue with a specific NVM Set. NVMe 1.4 allows the host system to inform the SSD of which NVM Set it plans to use each queue with, which can give the SSD controller the opportunity to further reduce latency or improve QoS when using Predictable Latency Mode. This feature is optional even for drives that support Predictable Latency Mode.
Namespace Write Protection
The new Namespace Write Protection feature is pretty self-explanatory. An NVMe namespace can be put into one of three read-only modes: read-only until the next power cycle, read-only until the first power cycle after the write protect feature is disabled, or permanently read-only for the lifetime of the drive. This provides a range of options for protecting critical data in embedded or high-security systems.
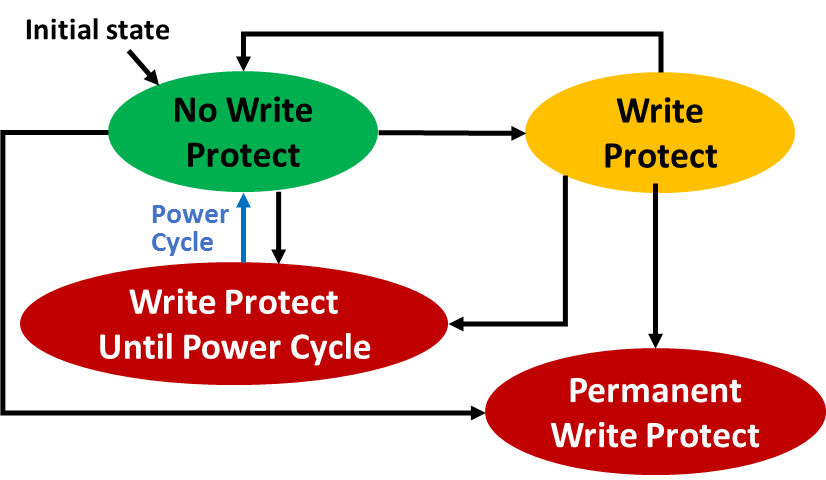
A typical use case will be to put the OS or a minimal recovery system on a write-protected namespace, and keep user data and apps on a regular read+write namespace. This is one of the first NVMe features to start providing a compelling case for client SSDs to support multiple namespaces, since protected operating systems or recovery partitions are already commonplace for both mobile and desktop operating systems. Write-protected namespaces can get the drive itself involved in helping protect the OS against accidental or malicious tampering, and this feature is much simpler than the existing Replay Protected Memory Block feature.
What's Next
Open Channel SSDs have been around in some form or another for several years. These expose more of the inner workings of the SSD and move all or part of the flash translation layer out of the drive and onto the host CPU. Several NVMe features have already been inspired in part by open channel SSDs, including the above hints about optimal block sizes and data alignment and the NVM Sets and Endurance Groups features. Last year Microsoft formed Project Denali to explore what is the best balance between the low-level control afforded by open channel SSDs and the easy to use abstraction of traditional block storage, with the ultimate goal of producing new standards that can be more broadly adopted than existing open channel efforts. That and related work is likely to continue influencing NVMe, but the general approach for NVMe has been to prefer exchanging hints rather than imposing hard restrictions on IO patterns.
(source: Western Digital presentation at USENIX Vault 2019)
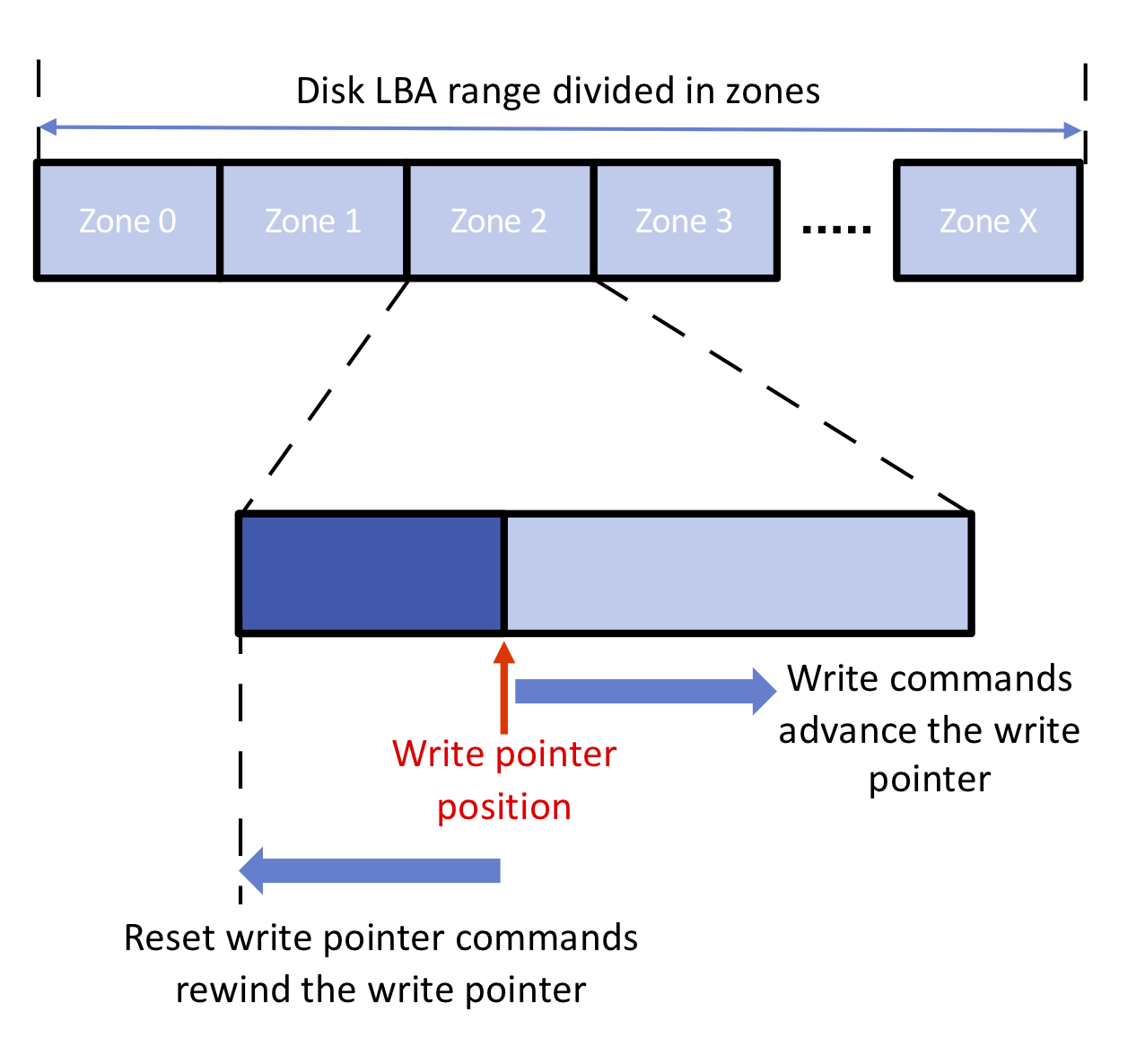
In a similar vein, there is a Technical Proposal in the NVMe working group to implement a Zoned Namespace feature that borrows ideas from how Shingled Magnetic Recording hard drives are handled. Host-managed SMR hard drives have similar constraints to NAND flash in that they have large regions that can support random reads but not overwriting of existing data; for NAND flash these regions are the erase blocks. Software and filesystems that have already been modified to support host-managed SMR drives can easily support zoned SSDs. It's not at all trivial to modify software to work without random write support, but a lot of that work has already been done. Making use of it on SSDs can reduce write amplification, improve latency and cut down on how much DRAM an SSD needs.
(source: Samsung Key-Value SSD product brief)
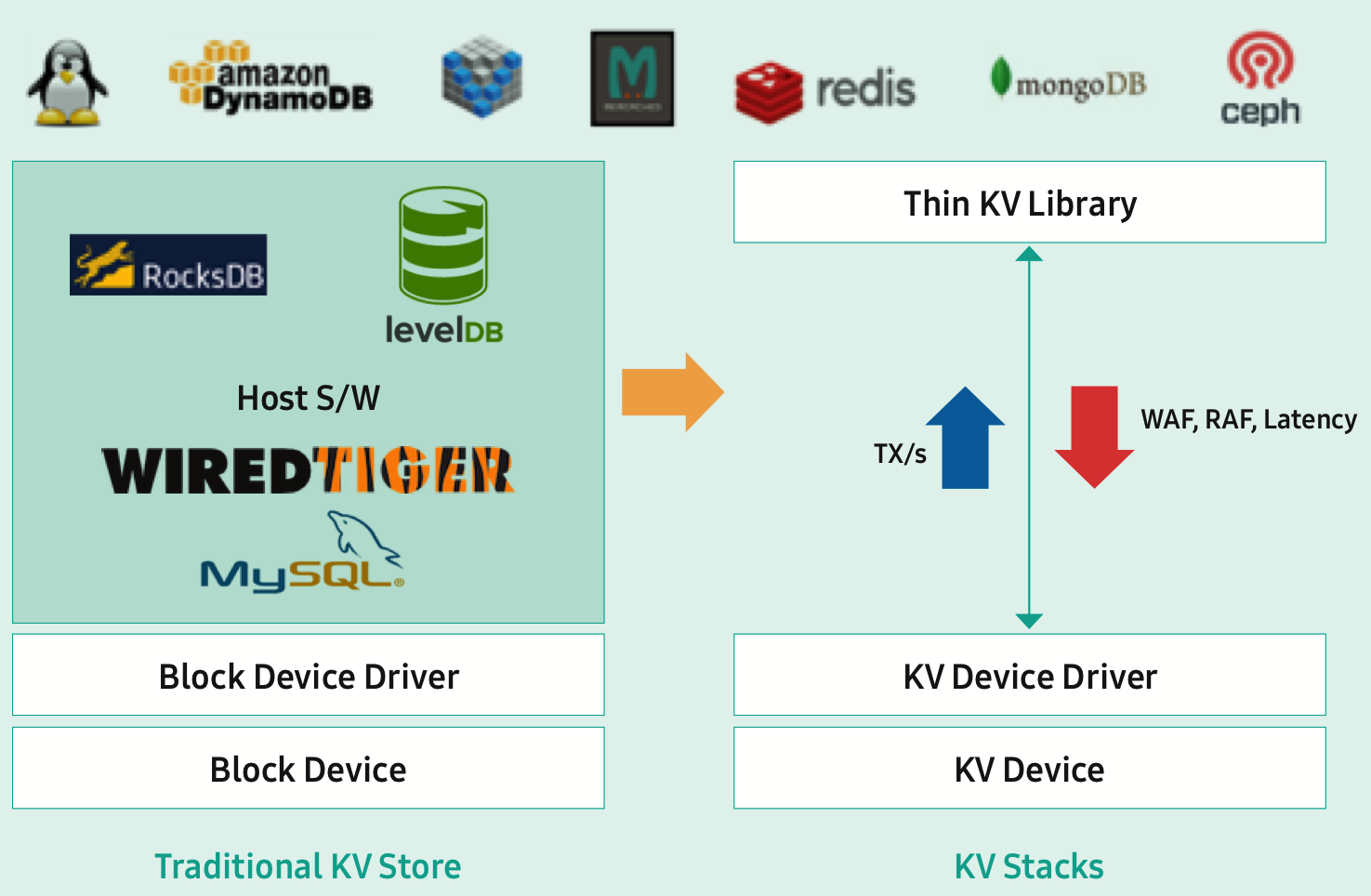
Several vendors have been developing SSDs that present a key-value database interface instead of a traditional block device. Supporting this only adds a little bit of complexity to the SSD's flash translation layer but it cuts out a lot of redundant abstractions on the host software side, so performance can be surprisingly high compared to running a key-value database application on top of a filesystem on a traditional SSD. We will probably see a standard for key-value namespaces added to NVMe sooner rather than later.
Further down the road, there are hopes of producing standards for computational storage devices and accelerators/coprocessors that can build atop NVMe infrastructure. There are a lot of companies working on or already shipping devices to offload tasks like compression, encryption, searching and AI inferencing from CPUs and instead performing these computational tasks closer to where the data is stored. Work to standardize the interfaces to such devices is still in its infancy, but in two or three years when it's time for NVMe 1.5, some of these ideas may have matured enough to start yielding standards for the basic infrastructure around computational storage.
Source: NVM Express








14 Comments
View All Comments
mode_13h - Monday, June 17, 2019 - link
Yeah, it's like he didn't read the article.> it's a general-purpose chunk of memory that is made persistent thanks to the same power loss protection capacitors that allow a typical enterprise SSD's internal caches to be safely flushed in the event of an unexpected loss of host power. The contents of the PMR will automatically be written out to flash, and when the host system comes back up it can ask the SSD to reload the contents of the PMR.
...would've taken less time to (re)read that part than to post two messages about it.
GreenReaper - Saturday, June 15, 2019 - link
Once it is sent, it can be considered "stored" and so a database can return success for a transaction. Basically the same thing that's done already with "hardware" RAID controllers that have flash-backed or battery/capacitor-supported RAM, just faster.If the power is kept on, it theoretically doesn't ever have to store it - it can delay indefinitely until power's withdrawn, at which point it has to be stored to maintain its guarantee.
mode_13h - Saturday, June 15, 2019 - link
It's pretty shocking that preferred alignment and granularity have taken so long to get exposed. Even SATA SSDs should've had that.Can anyone explain why alignment and granularity should differ? I understand there are better and worse alignments, even among those that are non-optimal. Is that what it's about?
cygnus1 - Monday, June 17, 2019 - link
Basically reads and writes aren't the same size for an SSD. So it's possible to have an alignment that's faster for small reads, but is terrible for writes. Increase the size of that granularity and write performance goes up (and write amplification goes down), but at the cost of read performance.