Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM ESTNVIDIA’s Answer: RAPIDS Bring GPUs to More Than CNNs
NVIDIA’s has proven more than once that it can outmaneuver the competition with excellent vision and strategy. NVIDIA understands that getting all neural networks to scale as CNNs is not going to be easy, and that there are a lot of applications out there that are either running on other methods than neural networks, or which are memory intensive rather than compute intensive.
At GTC Europe, NVIDIA launched a new data science platform for enterprise use, built on NVIDIA’s new “RAPIDS” framework. The basic idea is that the GPU acceleration of the data pipeline should not be limited to deep learning.
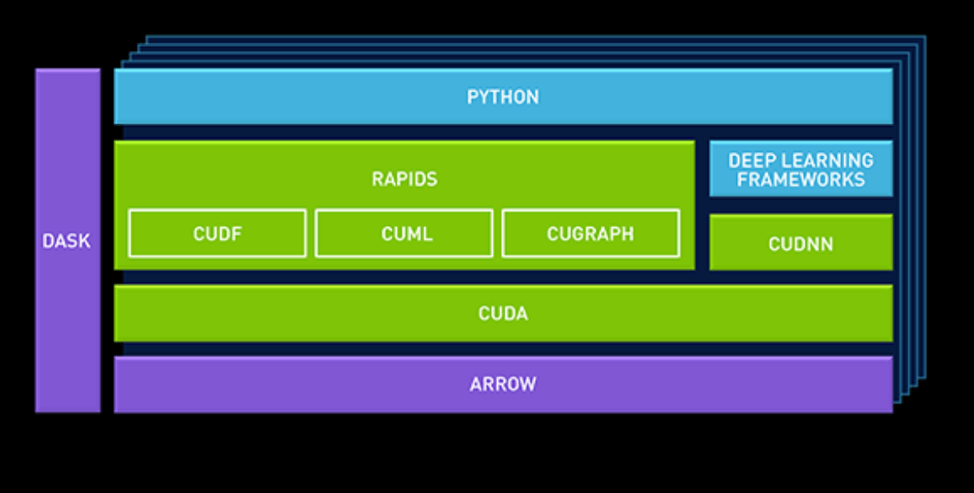
CuDF, for example, allows data scientists to load data into GPU memory and batch process it, similar to Pandas (the python library for manipulating data). cuML is a currently limited collection of GPU-accelerated machine learning libraries. Eventually most (all?) machine learning algorithms available in Scikit-Learn toolkit should be GPU accelerated and available in cuML.
NVIDIA also added Apache Arrow, a columnar in-memory database. This is because GPUs operate on vectors, and as a result favor a columnar layout in memory.
By leveraging Apache arrow as a “central database”, NVIDIA avoids a lot of overhead.
Making sure that there are GPU accelerated versions of the typical Python libraries such as Sci-Kit and Pandas is one step in right direction. But Pandas is only suited for the lighter “data science exploration” tasks. By working with Databricks to make sure that RAPIDS is also used in the heavy duty, distributed “data processing” framework Spark, NVIDIA is taking the next step, breaking out of the "Deep learning mostly" role and towards "NVIDIA in the rest of the data pipeline".
However, the devil is in the details. Adding GPUs to a framework that has been optimized for years to make optimal use of CPU cores and the massive amounts of RAM available in servers is not easy. Spark is built to run on a few tens of powerful server cores, not thousands of wimpy GPU cores. Spark has been optimized to run on clusters of server nodes, making it seem like one big lump of RAM memory and cores. Mixing two kinds of memory – RAM and GPU VRAM – and keeping the distributed compute nature of Spark intact will not be easy.
Secondly, cherry picking the most GPU-friendly machine learning algorithms is one thing, but making sure most of them run fine in GPU-based machine is another thing. Lastly, GPUs will still have less memory than CPUs for the foreseeable future; and even coherent platforms won’t solve the problem that system RAM is a fraction of the speed of local VRAM








56 Comments
View All Comments
ballsystemlord - Saturday, August 3, 2019 - link
Spelling and grammar errors:"But it will have a impact on total energy consumption, which we will discuss."
"An" not "a":
"But it will have an impact on total energy consumption, which we will discuss."
"We our newest servers into virtual clusters to make better use of all those core."
Missing "s" and missing word. I guessed "combine".
"We combine our newest servers into virtual clusters to make better use of all those cores."
"For reasons unknown to us, we could get our 2.7 GHz 8280 to perform much better than the 2.1 GHz Xeon 8176."
The 8280 is only slightly faster in the table than the 8176. It is the 8180 that is missing from the table.
"However, since my group is mostly using TensorFlow as a deep learning framework, we tend to with stick with it."
Excess "with":
"However, since my group is mostly using TensorFlow as a deep learning framework, we tend to stick with it."
"It has been observed that using a larger batch can causes significant degradation in the quality of the model,..."
Remove plural form:
"It has been observed that using a larger batch can cause significant degradation in the quality of the model,..."
"...but in many applications a loss of even a few percent is a significant."
Excess "a":
"...but in many applications a loss of even a few percent is significant."
"LSTM however come with the disadvantage that they are a lot more bandwidth intensive."
Add an "s":
"LSTMs however come with the disadvantage that they are a lot more bandwidth intensive."
"LSTMs exhibit quite inefficient memory access pattern when executed on mobile GPUs due to the redundant data movements and limited off-chip bandwidth."
"pattern" should be plural because "LSTMs" is plural, I choose an "s":
"LSTMs exhibit quite inefficient memory access patterns when executed on mobile GPUs due to the redundant data movements and limited off-chip bandwidth."
"Of course, you have the make the most of the available AVX/AVX2/AVX512 SIMD power."
"to" not "the":
"Of course, you have to make the most of the available AVX/AVX2/AVX512 SIMD power."
"Also, this another data point that proves that CNNs might be one of the best use cases for GPUs."
Missing "is":
"Also, this is another data point that proves that CNNs might be one of the best use cases for GPUs."
"From a high-level workflow perfspective,..."
A joke, or a misspelling?
"... it's not enough if the new chips have to go head-to-head with a GPU in a task the latter doesn't completely suck at."
Traditionally, AT has had no language.
"... it's not enough if the new chips have to go head-to-head with a GPU in a task the latter is good at."
"It is been going on for a while,..."
"has" not "is":
"It has been going on for a while,..."
ballsystemlord - Saturday, August 3, 2019 - link
Thanks for the cool article!tmnvnbl - Tuesday, August 6, 2019 - link
Great read, especially liked the background and perspective next to the benchmark detailsdusk007 - Tuesday, August 6, 2019 - link
Great Article.I wouldn't call Apache Arrow a database though. It is a data format more akin to a file format like csv or parquet. It is not something that stores data for you and gives it to you. It is the how to store data in memory. Like CSV or Parquet are a "how to" store data in Files. More efficient less redundancy less overhead when access from different runtimes (Tensorflow, Spark, Pandas,..).
Love the article, I hope we get more of those. Also that huge performance optimizations are possible in this field just in software. Often renting compute in the cloud is cheaper than the man hours required to optimize though.
Emrickjack - Thursday, August 8, 2019 - link
Johan's new piece in 14 months! Looking forward to your Rome reviewEmrickjack - Thursday, August 8, 2019 - link
It More Information http://americanexpressconfirmcard.club/