Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM ESTNVIDIA’s Answer: RAPIDS Bring GPUs to More Than CNNs
NVIDIA’s has proven more than once that it can outmaneuver the competition with excellent vision and strategy. NVIDIA understands that getting all neural networks to scale as CNNs is not going to be easy, and that there are a lot of applications out there that are either running on other methods than neural networks, or which are memory intensive rather than compute intensive.
At GTC Europe, NVIDIA launched a new data science platform for enterprise use, built on NVIDIA’s new “RAPIDS” framework. The basic idea is that the GPU acceleration of the data pipeline should not be limited to deep learning.
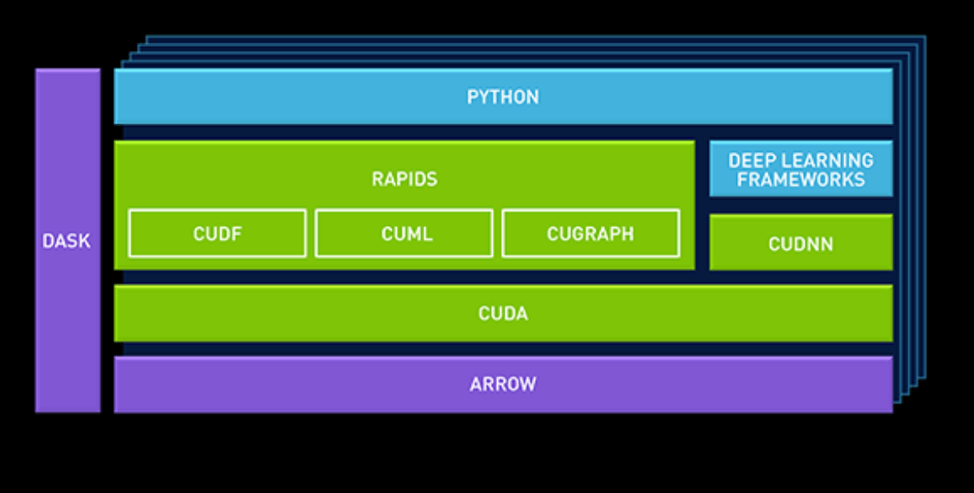
CuDF, for example, allows data scientists to load data into GPU memory and batch process it, similar to Pandas (the python library for manipulating data). cuML is a currently limited collection of GPU-accelerated machine learning libraries. Eventually most (all?) machine learning algorithms available in Scikit-Learn toolkit should be GPU accelerated and available in cuML.
NVIDIA also added Apache Arrow, a columnar in-memory database. This is because GPUs operate on vectors, and as a result favor a columnar layout in memory.
By leveraging Apache arrow as a “central database”, NVIDIA avoids a lot of overhead.
Making sure that there are GPU accelerated versions of the typical Python libraries such as Sci-Kit and Pandas is one step in right direction. But Pandas is only suited for the lighter “data science exploration” tasks. By working with Databricks to make sure that RAPIDS is also used in the heavy duty, distributed “data processing” framework Spark, NVIDIA is taking the next step, breaking out of the "Deep learning mostly" role and towards "NVIDIA in the rest of the data pipeline".
However, the devil is in the details. Adding GPUs to a framework that has been optimized for years to make optimal use of CPU cores and the massive amounts of RAM available in servers is not easy. Spark is built to run on a few tens of powerful server cores, not thousands of wimpy GPU cores. Spark has been optimized to run on clusters of server nodes, making it seem like one big lump of RAM memory and cores. Mixing two kinds of memory – RAM and GPU VRAM – and keeping the distributed compute nature of Spark intact will not be easy.
Secondly, cherry picking the most GPU-friendly machine learning algorithms is one thing, but making sure most of them run fine in GPU-based machine is another thing. Lastly, GPUs will still have less memory than CPUs for the foreseeable future; and even coherent platforms won’t solve the problem that system RAM is a fraction of the speed of local VRAM








56 Comments
View All Comments
Bp_968 - Tuesday, July 30, 2019 - link
Oh no, not 8 million, 8 *billion* (for the 8180 xeon), and 19.2 *billion* for the last gen AMD 32 core epyc! I don't think they have released much info on the new epyc yet buy its safe to assume its going to be 36-40 billion! (I dont know how many transistors are used in the I/O controller).And like you said, the connections are crazy! The xeon has a 5903 BGA connection so it doesn't even socket, its soldered to the board.
ozzuneoj86 - Sunday, August 4, 2019 - link
Doh! Thanks for correcting the typo!Yes, 8 BILLION... it's incredible! It's even more difficult to fathom that these things, with billions of "things" in such a small area are nowhere near as complex or versatile as a similarly sized living organism.
s.yu - Sunday, August 4, 2019 - link
Well the current magnetic storage is far from the storage density of DNA, in this sense.FunBunny2 - Monday, July 29, 2019 - link
"As a single SQL query is nowhere near as parallel as Neural Networks – in many cases they are 100% sequential "hogwash. SQL, or rather the RM which it purports to implement, is embarrassingly parallel; these are set operations which care not a fig for order. the folks who write SQL engines, OTOH, are still stuck in C land. with SSD seq processing so much faster than HDD, app developers are reverting to 60s tape processing methods. good for them.
bobhumplick - Tuesday, July 30, 2019 - link
so cpus will become more gpu like and gpus will become more cpu like. you got your avx in my cuda core. no, you got your cuda core in my avx......mmmmmmbobhumplick - Tuesday, July 30, 2019 - link
intel need to get those gpus out quickAmiba Gelos - Tuesday, July 30, 2019 - link
LSTM in 2019?At least try GRU or transformer instead.
LSTM is notorious for its non-parallelizablity, skewing the result toward cpu.
Rudde - Tuesday, July 30, 2019 - link
I believe that's why they benchmarked LSTM. They benchmarked gpu stronghold CNNs to show great gpu performance and benchmarked LSTM to show great cpu performance.Amiba Gelos - Tuesday, July 30, 2019 - link
Recommendation pipeline already demonstrates the necessity of good cpus for ML.Imho benching LSTM to showcase cpu perf is misleading. It is slow, performing equally or worse than alts, and got replaced by transformer and cnn in NMT and NLP.
Heck why not wavenet? That's real world app.
I bet cpu would perform even "better" lol.
facetimeforpcappp - Tuesday, July 30, 2019 - link
A welcome will show up on their screen which they have to acknowledge to make a call.So there you go; Mac to PC, PC to iPhone, iPad to PC or PC to iPod, the alternatives are various, you need to pick one that suits your needs. Facetime has magnificent video calling quality than other best video calling applications.
https://facetimeforpcapp.com/