Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM ESTApache Spark 2.1 Benchmarking
Apache Spark is the poster child of Big Data processing. Speeding up Big Data applications is the top priority project at the university lab I work for (Sizing Servers Lab of the University College of West-Flanders), so we produced a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large number of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library "BoilerPipe". Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities ("words that mean something") out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
We our newest servers into virtual clusters to make better use of all those core. We run with 8 executors. Researcher Esli Heyvaert also upgraded our Spark benchmark so it could run on Apache Spark 2.1.1.
Here are the results:
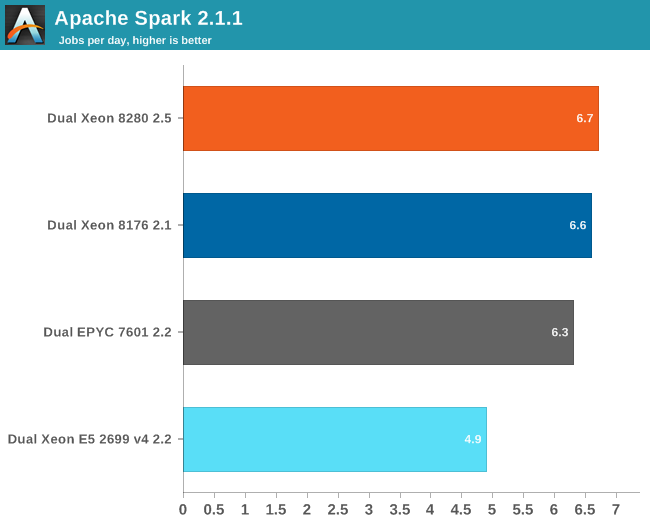
Our Spark benchmark needs about 120 GB of RAM to run. The time spent on storage I/O is negligible. Data processing is very parallel, but the shuffle phases require a lot of memory interaction. The ALS phase does not scale well over many threads, but it is less than 4% of the total testing time.
For reasons unknown to us, we could get our 2.7 GHz 8280 to perform much better than the 2.1 GHz Xeon 8176. We suspect that the fact that we used the new Xeon chips with an older (Skylake-SP) server could be the reason, as trying different Spark configurations (executors, JVM settings) did not help. A BIOS update did not help us either.
Ok, this was big data processing combined with mostly "traditional" Machine learning: NER and ALS. How about some "deep learning"?








56 Comments
View All Comments
Bp_968 - Tuesday, July 30, 2019 - link
Oh no, not 8 million, 8 *billion* (for the 8180 xeon), and 19.2 *billion* for the last gen AMD 32 core epyc! I don't think they have released much info on the new epyc yet buy its safe to assume its going to be 36-40 billion! (I dont know how many transistors are used in the I/O controller).And like you said, the connections are crazy! The xeon has a 5903 BGA connection so it doesn't even socket, its soldered to the board.
ozzuneoj86 - Sunday, August 4, 2019 - link
Doh! Thanks for correcting the typo!Yes, 8 BILLION... it's incredible! It's even more difficult to fathom that these things, with billions of "things" in such a small area are nowhere near as complex or versatile as a similarly sized living organism.
s.yu - Sunday, August 4, 2019 - link
Well the current magnetic storage is far from the storage density of DNA, in this sense.FunBunny2 - Monday, July 29, 2019 - link
"As a single SQL query is nowhere near as parallel as Neural Networks – in many cases they are 100% sequential "hogwash. SQL, or rather the RM which it purports to implement, is embarrassingly parallel; these are set operations which care not a fig for order. the folks who write SQL engines, OTOH, are still stuck in C land. with SSD seq processing so much faster than HDD, app developers are reverting to 60s tape processing methods. good for them.
bobhumplick - Tuesday, July 30, 2019 - link
so cpus will become more gpu like and gpus will become more cpu like. you got your avx in my cuda core. no, you got your cuda core in my avx......mmmmmmbobhumplick - Tuesday, July 30, 2019 - link
intel need to get those gpus out quickAmiba Gelos - Tuesday, July 30, 2019 - link
LSTM in 2019?At least try GRU or transformer instead.
LSTM is notorious for its non-parallelizablity, skewing the result toward cpu.
Rudde - Tuesday, July 30, 2019 - link
I believe that's why they benchmarked LSTM. They benchmarked gpu stronghold CNNs to show great gpu performance and benchmarked LSTM to show great cpu performance.Amiba Gelos - Tuesday, July 30, 2019 - link
Recommendation pipeline already demonstrates the necessity of good cpus for ML.Imho benching LSTM to showcase cpu perf is misleading. It is slow, performing equally or worse than alts, and got replaced by transformer and cnn in NMT and NLP.
Heck why not wavenet? That's real world app.
I bet cpu would perform even "better" lol.
facetimeforpcappp - Tuesday, July 30, 2019 - link
A welcome will show up on their screen which they have to acknowledge to make a call.So there you go; Mac to PC, PC to iPhone, iPad to PC or PC to iPod, the alternatives are various, you need to pick one that suits your needs. Facetime has magnificent video calling quality than other best video calling applications.
https://facetimeforpcapp.com/