The Samsung Galaxy S10+ Snapdragon & Exynos Review: Almost Perfect, Yet So Flawed
by Andrei Frumusanu on March 29, 2019 9:00 AM ESTInference Performance: APIs, Where Art Thou?
Having covered the new CPU complexes of both new Exynos and Snapdragon SoCs, up next is the new generation neural processing engines in each chip.
The Snapdragon 855 brings big performance improvements to the table thanks to a doubling of the HVX units inside the Hexagon 690 DSP. The HVX units in the last two generations of Snapdragon chips were the IP blocks who took the brunt of new integer neural network inferencing work, an area the IP is specifically adept at.
The new tensor accelerator inside of the Hexagon 690 was shown off by Qualcomm at the preview event back in January. Unfortunately one of the issues with the new block is that currently it’s only accessible through Qualcomm’s own SDK tools, and currently doesn’t offer acceleration for NNAPI workloads until later in the year with Android Q.
Looking at a compatibility matrix between what kind of different workloads are able to be accelerated by various hardware block in NNAPI reveals are quite sad state of things:
| NNAPI SoC Block Usage Estimates | |||
| SoC \ Model Type | INT8 | FP16 | FP32 |
| Exynos 9820 | GPU | GPU | GPU |
| Exynos 9810 | GPU? | GPU | CPU |
| Snapdragon 855 | DSP | GPU | GPU |
| Snapdragon 845 | DSP | GPU | GPU |
| Kirin 980 | GPU? | NPU | CPU |
What stands out in particular is Samsung’s new Exynos 9820 chipset. Even though the SoC promises to come with an NPU that on paper is extremely powerful, the software side of things make it as if the block wouldn’t exist. Currently Samsung doesn’t publicly offer even a proprietary SDK for the new NPU, much less NNAPI drivers. I’ve been told that Samsung looks to address this later in the year, but how exactly the Galaxy S10 will profit from new functionality in the future is quite unclear.
For Qualcomm, as the HVX units are integer only, this means only quantised INT8 inference models are able to be accelerated by the block, with FP16 and FP32 acceleration falling back what should be GPU acceleration. It’s to be noted my matrix here could be wrong as we’re dealing with abstraction layers and depending on the model features required the drivers could run models on different IP blocks.
Finally, HiSilicon’s Kirin 980 currently only offers NNAPI acceleration for FP16 models for the NPU, with INT8 and FP32 models falling back to the CPU as the device are seemingly not using Arm’s NNAPI drivers for the Mali GPU, or at least not taking advantage of INT8 acceleration ine the same way Samsung's GPU drivers.
Before we even get to the benchmark figures, it’s clear that the results will be a mess with various SoCs performing quite differently depending on the workload.
For the benchmark, we’re using a brand-new version of Andrey Ignatov’s AI-Benchmark, namely the just released version 3.0. The new version tunes the models as well as introducing a new Pro-Mode that most interestingly now is able to measure sustained throughput inference performance. This latter point is important as we can have very different performance figures between one-shot inferences and back-to-back inferences. In the former case, software and DVFS can vastly overshadow the actual performance capability of the hardware as in many cases we’re dealing with timings in the 10’s or 100’s of milliseconds.
Going forward we’ll be taking advantage of the new benchmark’s flexibility and posting both instantaneous single inference times as well sequential throughput inference times; better showcasing and separating the impact of software and hardware capabilities.
There’s a lot of data here, so for the sake of brevity I’ll simply put up all the results up and we’ll go over the general analysis at the end:
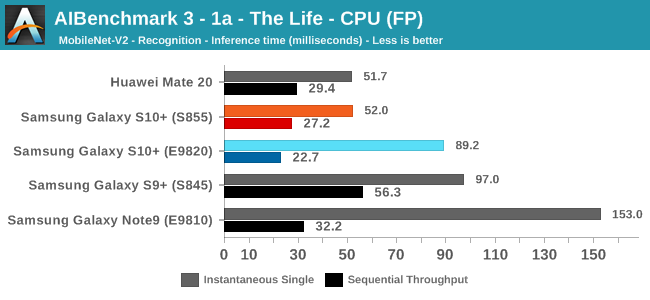
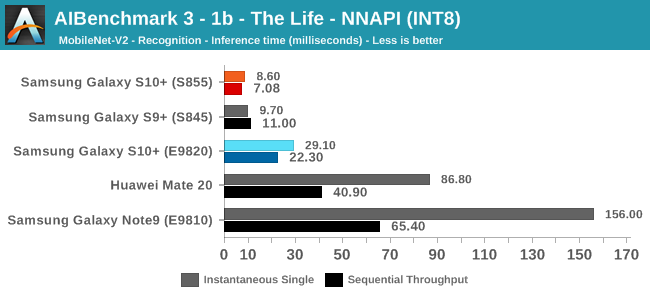
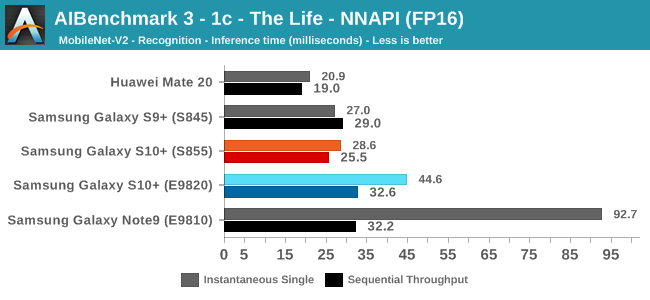
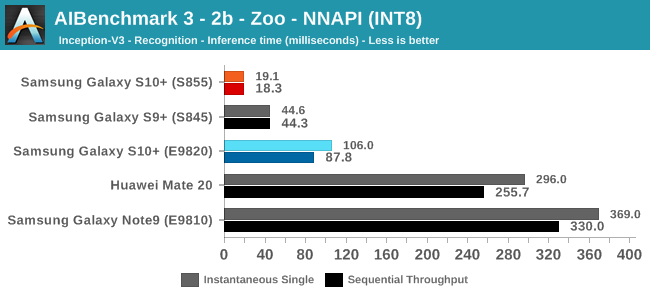
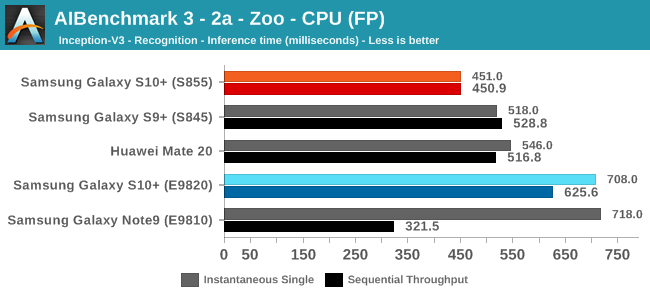
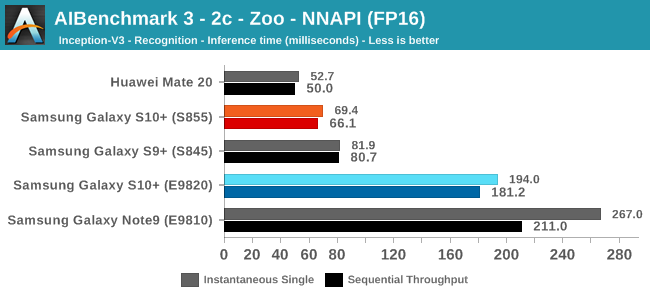
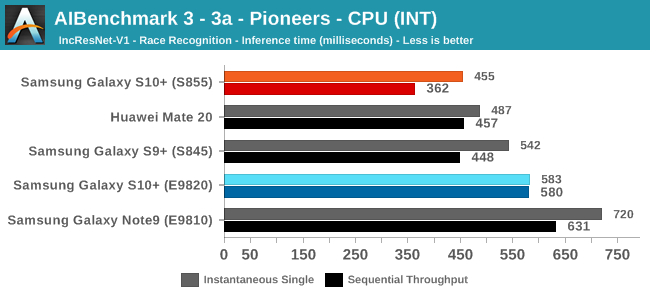
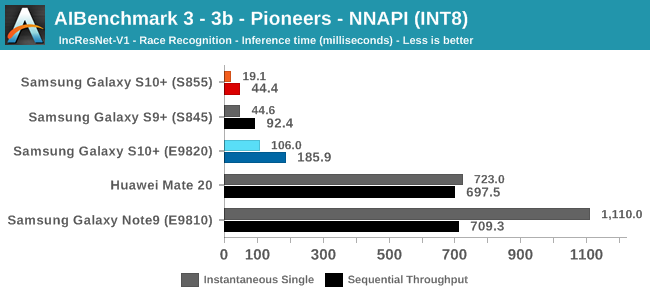
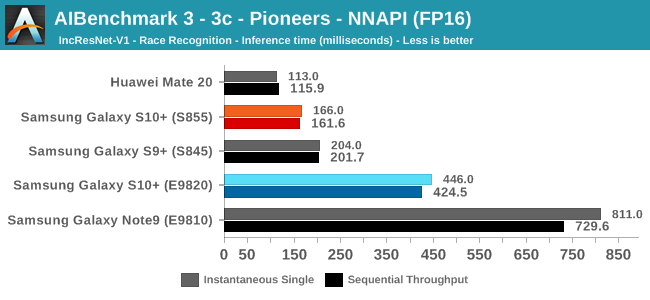
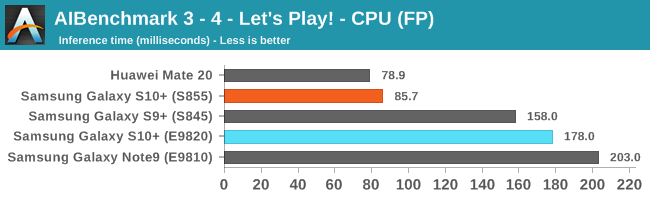
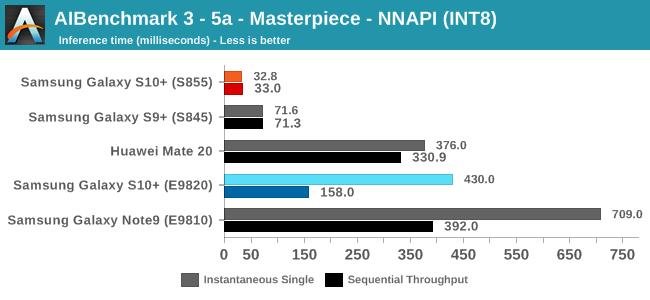
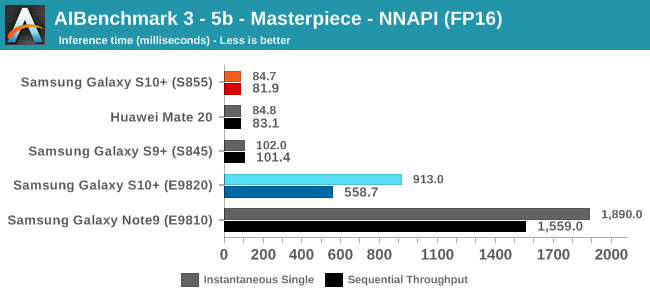
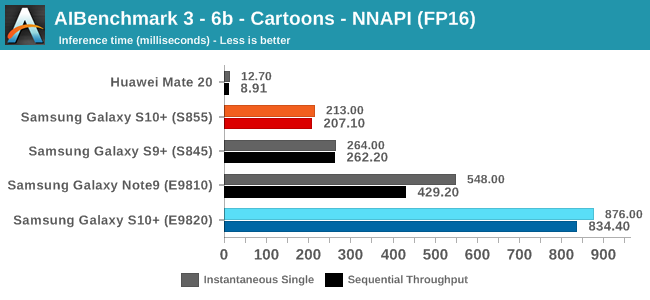
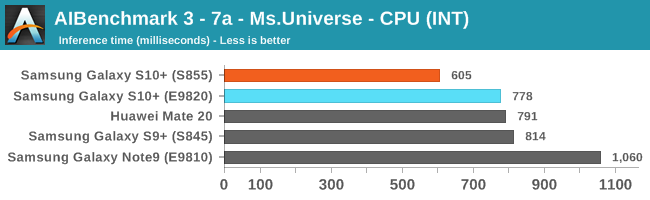
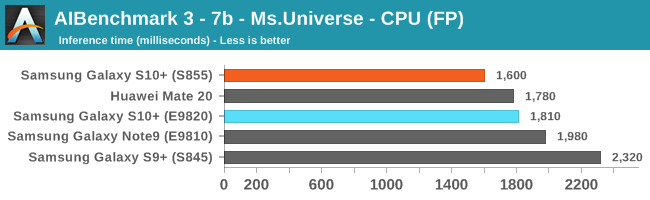
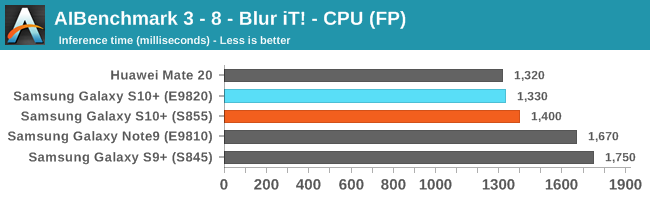
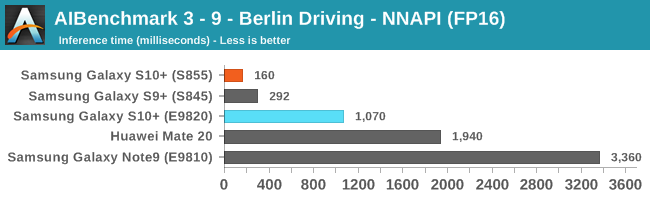
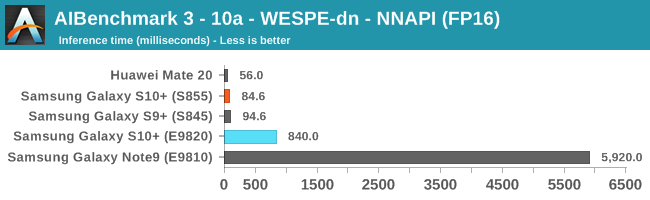
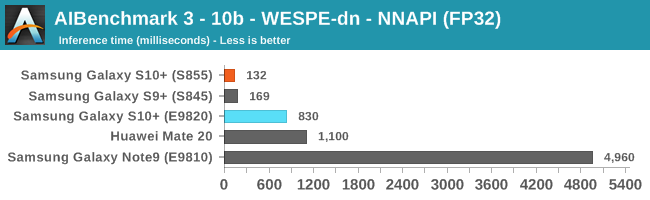
As initially predicted, the results are extremely spread across all the SoCs.
The new tests also include workloads that are solely using TensorFlow libraries on the CPU, so the results not only showcase NNAPI accelerator offloading but can also serve as a CPU benchmark.
In the CPU-only tests, we see the Snapdragon 855 and Exynos 9820 being in the lead, however there’s a notable difference between the two when it comes to their instantaneous vs sequential performance. The Snapdragon 855 is able to post significantly better single inference figures than the Exynos, although the latter catches up in longer duration workloads. Inherently this is a software characteristic difference between the two chips as although Samsung has improved scheduler responsiveness in the new chip, it still lags behind the Qualcomm variant.
In INT8 workloads there is no contest as Qualcomm is far ahead of the competition in NNAPI benchmarks simply due to the fact that they’re the only vendor being able to offload this to an actual accelerator. Samsung’s Exynos 9820 performance here actually has also drastically improved thanks to the new Mali G76’s new INT8 dot-product instructions. It’s odd that the same GPU in the Kirin 980 doesn’t show the same improvements, which could be due to not up-to-date Arm GPU NNAPI drives on the Mate 20.
The FP16 performance crown many times goes to the Kirin 980 NPU, but in some workloads it seems as if they fall back to the GPU, and in those cases Qualcomm’s GPU clearly has the lead.
Finally for FP32 workloads it’s again the Qualcomm GPU which takes an undisputed lead in performance.
Overall, machine inferencing performance today is an absolute mess. In all the chaos though Qualcomm seems to be the only SoC supplier that is able to deliver consistently good performance, and its software stack is clearly the best. Things will evolve over the coming months, and it will be interesting to see what Samsung will be able to achieve in regards to their custom SDK and NNAPI for the Exynos NPU, but much like Huawei’s Kirin NPU it’s all just marketing until we actually see the software deliver on the hardware capabilities, something which may take longer than the actual first year active lifespan of the new hardware.








229 Comments
View All Comments
melgross - Saturday, March 30, 2019 - link
Nope. Not even close.Irish910 - Saturday, March 30, 2019 - link
Oh right.You must have watched a YouTube video or two where the note loads one or two web based apps quicker. But fails to keep the same apps open in memory after the start up test.
I’ll trust the spec benchmarks. Hell even geekbench scores and Antutu are much higher on the A12. You have no argument.
Tropicocity - Sunday, March 31, 2019 - link
All this is irrelevant when you take into account that to get the A12, you have ONE brand to go with, and an entirely different OS, with a very "You better buy EVERYTHING Apple or you're fucked" mentality. They literally lock you into their ecosystem and take away vast amounts of consumer freedom in terms of customization, and iTunes is still the worst piece of software on any phonecha0z_ - Tuesday, April 9, 2019 - link
I wish A12 was a SOC sold to other companies... ;(Thraxen - Sunday, March 31, 2019 - link
LOL... it’s funny you mention dumping apps from memory when that’s what iOS is notorious for doing since all Apple devices are crippled by anemic RAM.cha0z_ - Tuesday, April 9, 2019 - link
You saw apple approach of fluidity and "user experience" above all. They aim towards animations, smoothness instead of choppy or no animation app loading. I suspect also that their loading is mainly after the animation finished and yes - the A12 is so fast that it can pull it off. In raw spec and speed the A12 is better in CPU/GPU vs sd855, simple as that. How it's utilised is different story. Some prefer the faster apps opening, others smooth and consistently doing so - UI. It's really nice to see how my iphone 6s is far smoother and "joyful" to use vs my exynos note 9 packed with features.hansmuff - Friday, March 29, 2019 - link
I do like the direction Samsung is going regarding battery and camera. I'm much looking forward to the S11, the S10 isn't worth upgrading to from a S9+ IMO.Thraxen - Friday, March 29, 2019 - link
I’d argue it rarely makes sense to upgrade between single generations for virtually any phone.StevoLincolnite - Friday, March 29, 2019 - link
Yeah. I have always waited a couple generations before I upgraded.I had to regress to my old trusty Note 5 for the time being though, broketh my Note 8... And figure I will just wait it out for the Note 10 and buy it outright in a few months.
Hate how phones are made from fragile glass and can't even survive a half foot drop. I really do.
catavalon21 - Thursday, August 22, 2019 - link
THAT. My son's S10, in an Otter Box case, fell and hit screen-first on something. The screen cracked. The built-in screen cover, which essentially prevents installing a good, effective, strong screen cover, is awful.