Arm Announces Neoverse N1 & E1 Platforms & CPUs: Enabling A Huge Jump In Infrastructure Performance
by Andrei Frumusanu on February 20, 2019 9:00 AM ESTEnd Remarks: Strengthening the Infrastructure Ecosystem
If there’s one thing that readers should take away from today’s presentations, it’s the fact that Arm is taking the infrastructure and server push extremely seriously. The last year in particular has been transformative for the Arm ecosystem as we’ve for the first time seen Arm vendor platforms be competitive with the major incumbents such as Intel and AMD.
The elephant in the room is Amazon, and last year’s reveal of a new AWS instance based on their own-in house ARMv8 Graviton processors marked a significant moment showcasing that Arm is now irrefutably becoming mainstream in the industry.
While Arm did not divulge any information on who will be employing the new Neoverse N1 platforms first – I would not be surprised if the next generation Graviton processor will based on the N1 CPU.
The N1 CPU looks to be an excellent CPU that targets a sweet-spot point between peak compute performance, overall throughput. And most importantly it maintains the leading power efficiency that is already found in Arm's mobile products. Arm has high hopes for N1 and its eventual successors, and for good reason: they're looking to steal market share away from the likes of Intel (and x86 servers in general), which has proven to be an entrenched market full of very high performance processors. For that reason Arm is bringing their best to the table, and while N1 isn't going to be a core-for-core competitor with flagship x86, it stands to pose a significant threat, especially in workloads that can easily scale up to a larger number of cores.
Meanwhile the new E1 CPU targets the expanding market for high throughput processors, which with the upcoming shift to 5G will require more throughput performance at low power levels. Here Arm seems to have custom-tailored a CPU specifically to serve such use-cases. This is a move that's arguably less about stealing market share from any one player, and more about being in the right place at the right time to secure their place in what should be a rapidly growing market. In that sense the E1 is a very traditional Arm move – focus on cost and simpler processors – and this has been a move that's continued to serve Arm well over the years.
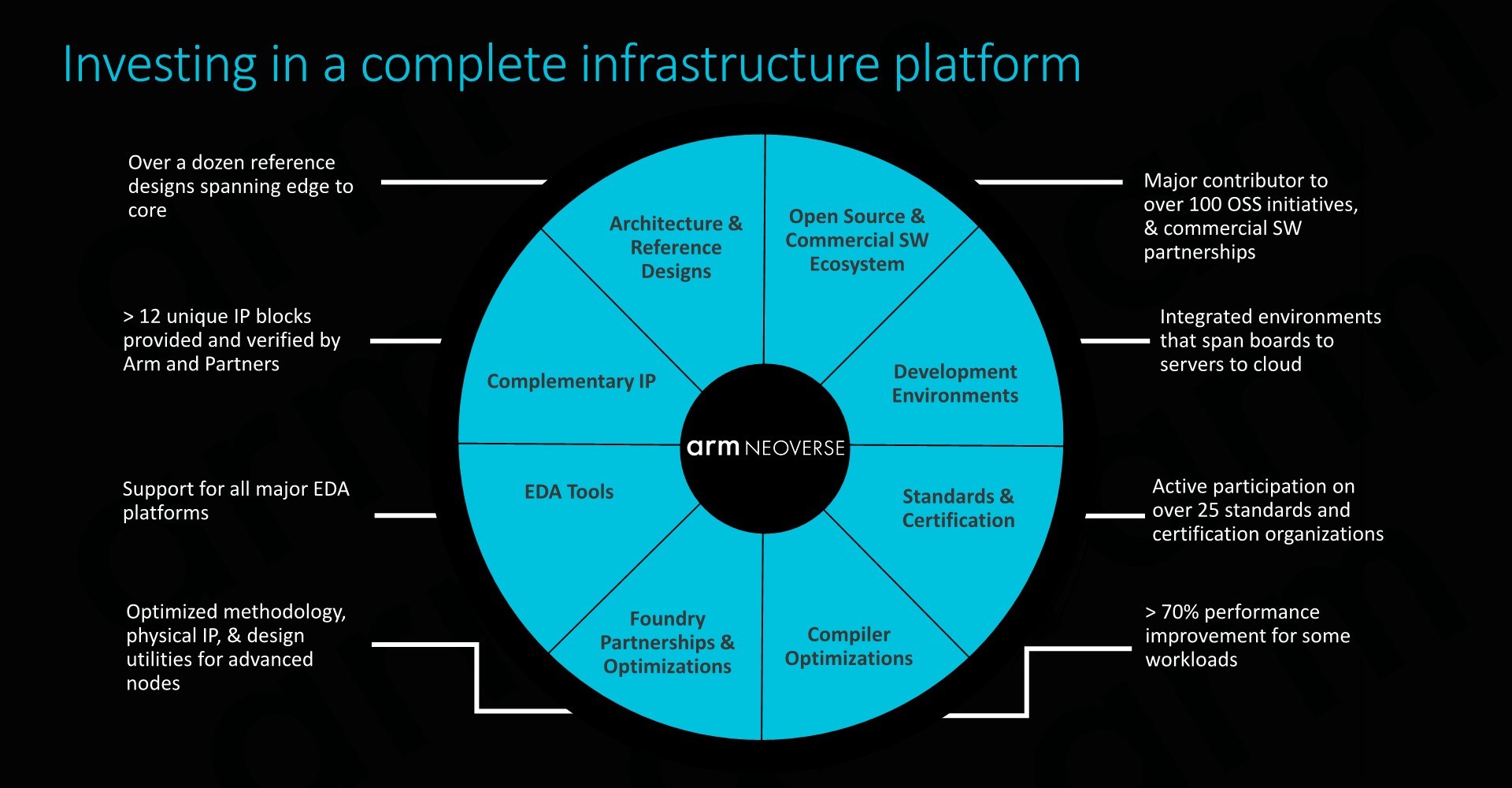
Although the new hardware IP is impressive, what also matters greatly is Arm’s efforts into strengthening the Arm software ecosystem. Working with various industry hardware and software partners in trying to facilitate the software stack and interoperability with Arm not only benefits vendors using Arm’s own hardware IP, but also vendors who chose the route of employing their own custom CPU and SoC designs. Similarly, those vendors who are trying to improve and strengthen their own products will inevitably feed back into strengthening the Arm ecosystem as well – creating essentially what is a group effort between many companies that in the future will continue to gain momentum.
It's said that the Neoverse N1 will be commercially deployed by partners in the next 12-18 months, and I think this will be a crucial moment for Arm and the company’s server endeavours. If the major breakthrough in mind-share hasn’t already happened, if all goes well and Arm and partners deliver on the promised improvements, the next 1-2 years will certainly represent a major shift in the industry.








101 Comments
View All Comments
blu42 - Thursday, February 21, 2019 - link
Yep. While ISA may not matter as an aggregate over the set of all tasks, ISAs matter very much when it comes to the performance of any individual task, just the same way as ASICs matter versus gen-purpose CPUs for any given task. One can think of ASICs as an extreme-case specialization of gen-purpose ISAs.Meteor2 - Wednesday, February 20, 2019 - link
Indeed, and reality is that all architectures are converging in terms of performance. It’s just a question of how much money any given manufacturer wants to invest. Intel cut R&D and the results are plain. AMD invested wisely. What Apple has achieved with the ARM ISA is phenomenal. Goodness knows what they could do if they turned their attention away from mobile but goodness knows how much it cost, too.Vitor - Wednesday, February 20, 2019 - link
Although the article is about servers and such, I can't help thinking that in less than a decade RISC CPUs can overtake the deskop/notebook market.And, corretct if I'm wrong, RISC is inherently more efficient than X86 derivates.
SarahKerrigan - Wednesday, February 20, 2019 - link
The evidence for "inherently more efficient" is pretty shaky, although I'd venture that validation of ARM cores is considerably simpler than validation of x86.That being said, ARM has been delivering rapidly and consistently on uarch, and Intel has not.
hMunster - Wednesday, February 20, 2019 - link
ARM is playing catch-up to Intel which got to the point of "no more low hanging fruit" much earlier.Wilco1 - Wednesday, February 20, 2019 - link
Well as an example Intel was unable to design competitive SoCs for the mobile market despite having a process advantage, investing $10+ Billion and even paying various companies to use their chips - "contra-revenue". There is no doubt the complexity of x86 translates into a significant overhead in design and verification, area, power and (at the low end) performance.hMunster - Wednesday, February 20, 2019 - link
The RISC vs. CISC debate does not really matter much anymore.HStewart - Wednesday, February 20, 2019 - link
A lot of this is because CISC process can now handle multiple microinstructions per clock cycle taking advantage of RISC smaller instruction away.But software compatibility is the major concern with this and Microsoft has many failed attempts to try to change this dependency.
FunBunny2 - Wednesday, February 20, 2019 - link
"A lot of this is because CISC process can now handle multiple microinstructions per clock cycle taking advantage of RISC smaller instruction away."that's a testable assertion. not by me, however. the execution of multiple microinstructions by CISC ISA machines doesn't mean, ceteris paribus, that the overlying CISC instruction runs as efficiently as a native RISC instruction; it just must run through the microinstructions. to the extent that CISC ISAs are really executed as some RISC machine on the silicon, that doesn't mean, apples to apples, that said CISC machine executes as efficiently as a native RISC machine. (native RISC does make headaches for the compiler writer, no doubt.) I'd wager that the real reason for RISC microarch was the desire to continue with X86 object code with a bit more performance back when the transistor budget began expanding, but not enough to build the entire ISA in silicon. and to keep the compiler writer from having to continually update as the real ISA (RISC) keeps changing. die shots of current cpu show that the 'core' is a diminishing percent of the real estate.
the still unanswered question: why did Intel/AMD not use the exploding transistor budget to execute the entire instruction set in hardware, but to create these behind-the-scenes RISC machines?
wumpus - Wednesday, February 20, 2019 - link
From memory, Dec was able to make VAX four times faster by pipelining the microcode from VAX instructions compared to "executing the VAX instruction all at once faster". VAX was about the CISCisest CISC that ever CISCed (and sold successfully. I think Intel's BiiN was worse).Dec also made Alpha, which even the first iteration was another 4 times faster than the "pipelined microcode" VAX.
And this was all single issue. Don't even think of trying to issue multiple "full CISC" instructions at once.