The Samsung 983 ZET (Z-NAND) SSD Review: How Fast Can Flash Memory Get?
by Billy Tallis on February 19, 2019 8:00 AM ESTPeak Random Read Performance
For client/consumer SSDs we primarily focus on low queue depth performance for its relevance to interactive workloads. Server workloads are often intense enough to keep a pile of drives busy, so the maximum attainable throughput of enterprise SSDs is actually important. But it usually isn't a good idea to focus solely on throughput while ignoring latency, because somewhere down the line there's always an end user waiting for the server to respond.
In order to characterize the maximum throughput an SSD can reach, we need to test at a range of queue depths. Different drives will reach their full speed at different queue depths, and increasing the queue depth beyond that saturation point may be slightly detrimental to throughput, and will drastically and unnecessarily increase latency. SATA drives can only have 32 pending commands in their queue, and any attempt to benchmark at higher queue depths will just result in commands sitting in the operating system's queues before being issued to the drive. On the other hand, some high-end NVMe SSDs need queue depths well beyond 32 to reach full speed.
Because of the above, we are not going to compare drives at a single fixed queue depth. Instead, each drive was tested at a range of queue depths up to the excessively high QD 512. For each drive, the queue depth with the highest performance was identified. Rather than report that value, we're reporting the throughput, latency, and power efficiency for the lowest queue depth that provides at least 95% of the highest obtainable performance. This often yields much more reasonable latency numbers, and is representative of how a reasonable operating system's IO scheduler should behave. (Our tests have to be run with any such scheduler disabled, or we would not get the queue depths we ask for.)
One extra complication is the choice of how to generate a specified queue depth with software. A single thread can issue multiple I/O requests using asynchronous APIs, but this runs into at several problems: if each system call issues one read or write command, then context switch overhead becomes the bottleneck long before a high-end NVMe SSD's abilities are fully taxed. Alternatively, if many operations are batched together for each system call, then the real queue depth will vary significantly and it is harder to get an accurate picture of drive latency. Finally, the current Linux asynchronous IO APIs only work in a narrow range of scenarios.
There is work underway to provide a new general-purpose async IO interface that will enable drastically lower overhead, but until that work lands in stable kernel versions, we're sticking with testing through the synchronous IO system calls that almost all Linux software uses. This means that we test at higher queue depths by using multiple threads, each issuing one read or write request at a time.
Using multiple threads to perform IO gets around the limits of single-core software overhead, and brings an extra advantage for NVMe SSDs: the use of multiple queues per drive. The NVMe drives in this review all support 32 separate IO queues, so we can have 32 threads on separate cores independently issuing IO without any need for synchronization or locking between threads.
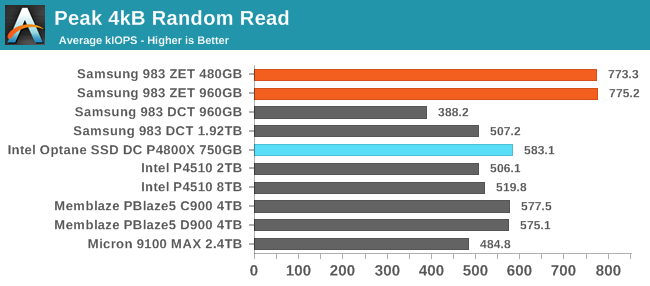
When performing random reads with a high thread count, the Samsung 983 ZET delivers significantly better throughput than any other drive we've tested: about 775k IOPS, which is over 3GB/s and about 33% faster than the Intel Optane SSD DC P4800X. The Optane SSD hits its peak throughput at QD8, while the 983 ZET requires a queue depth of at least 16 to match the Optane SSD's peak, and the peak for the 983 ZET is at QD64.
 |
|||||||||
| Power Efficiency in kIOPS/W | Average Power in W | ||||||||
At this point, it's no surprise to see the 983 turn in great efficiency scores. It's drawing almost 8W during this test, but that's not particularly high by the standards of enterprise NVMe drives. The TLC-based 983 DCT provides the next-best performance per Watt due to even lower power consumption than the Z-SSDs.
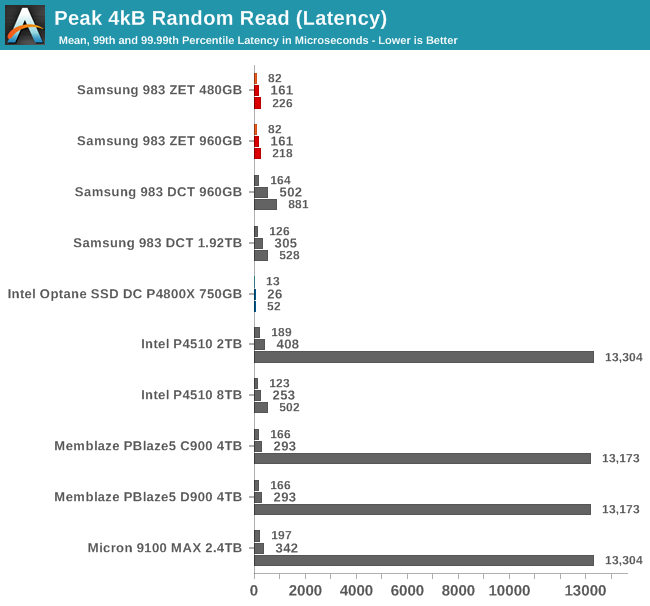
The Optane SSD still holds on to a clear advantage in the random read latency scores, with 99.99th percentile latency that is lower than the average read latency of even the Z-SSDs. The two Z-SSDs do provide lower tail latencies than the other flash-based SSDs, several of which require very high thread counts to reach full throughput and thus end up with horrible 99.99th percentile latencies due to contention for CPU cores.
Peak Sequential Read Performance
Since this test consists of many threads each performing IO sequentially but without coordination between threads, there's more work for the SSD controller and less opportunity for pre-fetching than there would be with a single thread reading sequentially across the whole drive. The workload as tested bears closer resemblance to a file server streaming to several simultaneous users, rather than resembling a full-disk backup image creation.

The Memblaze PBlaze5 C900 has the highest peak sequential read speed thanks to its PCIe 3.0 x8 interface. Among the drives with the more common four lane connection, the Samsung 983 ZETs are tied for first place, but they reach that ~3.1GB/s with a slightly lower queue depth than the 983 DCT or PBlaze5 D900. The Optane SSD DC P4800X comes in last place, being limited to just 2.5GB/s for multi-stream sequential reads.
 |
|||||||||
| Power Efficiency in MB/s/W | Average Power in W | ||||||||
The Samsung 983s clearly have the best power efficiency on this sequential read test, but the TLC-based 983 DCT continues once again uses slightly less power than the 983 ZET, so the Z-SSDs don't quite take first place. The Optane SSD doesn't have the worst efficiency rating, because despite its low performance, it only uses 2W more than the Samsung drives, far less than the Memblaze or Micron drives.
Steady-State Random Write Performance
The hardest task for most enterprise SSDs is to cope with an unending stream of writes. Once all the spare area granted by the high overprovisioning ratios has been used up, the drive has to perform garbage collection while simultaneously continuing to service new write requests, and all while maintaining consistent performance. The next two tests show how the drives hold up after hours of non-stop writes to an already full drive.
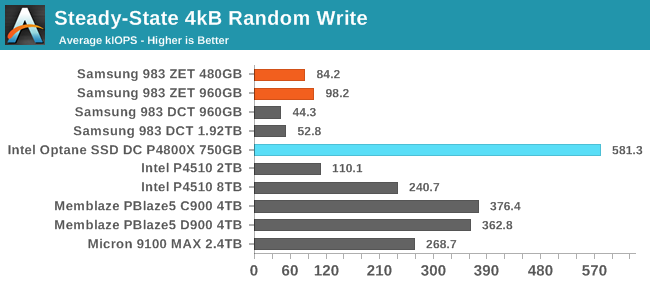
The Samsung 983 ZETs outperform the TLC-based 983 DCTs for steady-state random writes, but otherwise are outclassed by the larger flash-based SSDs and the Optane SSD, which is almost six times faster than the 960GB 983 ZET. Using Z-NAND clearly helps some with steady-state write performance, but the sheer capacity of the bigger TLC drives helps even more.
 |
|||||||||
| Power Efficiency in kIOPS/W | Average Power in W | ||||||||
The 983 ZET uses more power than the 983 DCT, but not enough to overcome the performance advantage; the 983 ZET has the best power efficiency among the smaller flash-based SSDs. The 4TB and larger drives outperform the 983 ZET so much that they have significantly better efficiency scores even drawing 2.6x the power. The Intel Optane SSD consumes almost twice the power of the 983 ZET but still offers better power efficiency than any of the flash-based SSDs.
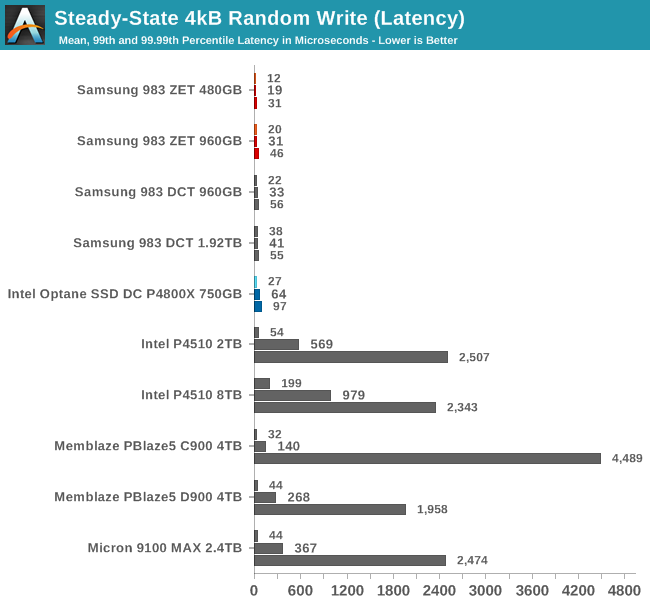
The Samsung drives and the Intel Optane SSD all have excellent latency stats for the steady-state random write test. The Intel P4510, Memblaze PBlaze5 and Micron 9100 all have decent average latencies but much worse QoS, with 99.99th percentile latencies of multiple milliseconds. These drives don't require particularly high queue depths to saturate their random write speed, so these QoS issues aren't due to any host-side software overhead.
Steady-State Sequential Write Performance

As with random writes, the steady-state sequential write performance of the Samsung 983 ZET is not much better than its TLC-based sibling. The only way for a flash-based SSD to handle sustained writes as well as the Optane SSD is to have very high capacity and overprovisioning.
 |
|||||||||
| Power Efficiency in MB/s/W | Average Power in W | ||||||||
The Samsung 983 ZET provides about half the performance per Watt of the Optane SSD during sequential writes. That's still decent compared to many other flash-based NVMe SSDs, but the 983 DCT and Memblaze PBlaze5 are slightly more efficient.








44 Comments
View All Comments
WithoutWeakness - Tuesday, February 19, 2019 - link
Hahaha I was hoping someone else would remember the absurdity of that comment thread. I thought of it as soon as I read that this drive was running SLC. Shame ddriver hasn't shown up here to provide his valuable insight and tell us what the engineers at Samsung did wrong and what they should have changed in order to beat Optane in mixed workloads.PaoDeTech - Tuesday, February 19, 2019 - link
Ovonic is the word.Fujikoma - Tuesday, February 19, 2019 - link
"The tradeoff is that they offer less density per cell – one-half or one-third".Should be one-quarter, not one-third... power of 2.
Billy Tallis - Tuesday, February 19, 2019 - link
TLC is three bits per cell, which is three times the density of SLC. The powers of two show up when you count the number of possible voltage levels that a cell may be programmed to, but that doesn't directly affect density, just endurance and the required amount of error correction.FunBunny2 - Wednesday, February 20, 2019 - link
"TLC is three bits per cell, which is three times the density of SLC. "but... is it still true that T and Q cells are being constructed on much larger nodes (layered) of 40 to 50 nm? or is there a move afoot to exploit nearer to current nodes in order to make more moolah?
and so far as density measures: how to do an apples to apples comparison SLC planar at 1x nm (could be done, but it isn't, right?) to 50 nm TLC layered? what about SLC 1x nm *layered*? might that not approach T and Q 50 nm layered? or is layered only possible are very large nodes with current machines? and so on.
ianken - Tuesday, February 19, 2019 - link
It's not for overclokerz gaemrz d00dz.ITT: overcloxoring gam3r d00dz bitching about the cost.
haukionkannel - Wednesday, February 20, 2019 - link
It seems that if you want to get speed, you just go for optane, or this should be much cheaper...cm2187 - Wednesday, February 20, 2019 - link
I can understand super fast SSDs for database cache and other industrial applications. But who would need such high performances in the retail space? Like what for?ballsystemlord - Wednesday, February 20, 2019 - link
Spelling and grammar corrections:Performance at such light loads is absolutely not what most of these drives are made for, but they have to make through the easy tests before we move on to the more realistic challenges.
Missing it:
Performance at such light loads is absolutely not what most of these drives are made for, but they have to make it through the easy tests before we move on to the more realistic challenges.
...incrementally reduce the rate until the test can run for a full hour, and the decrease the rate further if necessary to get the drive under the latency limits.
Should be "then" not "the":
...incrementally reduce the rate until the test can run for a full hour, and then decrease the rate further if necessary to get the drive under the latency limits.
I read the whole thing and found only 2 mistakes, good work!
MDD1963 - Friday, February 22, 2019 - link
I was expecting some numbers that looked at least impressive compared to a 970 EVO; seeing as the only significat number difference is the price at nearly triple EVOs price,.... I'll pass....(Someone wake me up when we start seeing 4,000 MB/sec reads....)