The Mate 20 & Mate 20 Pro Review: Kirin 980 Powering Two Contrasting Devices
by Andrei Frumusanu on November 16, 2018 8:10 AM EST- Posted in
- Smartphones
- Huawei
- Mobile
- Kirin 980
- Mate 20
- Mate 20 Pro
Kirin 980 Second Generation NPU - NNAPI Tested
We’ve tested the first generation Kirin NPU back in January in our Kirin 970 review – Back then, we were quite limited in terms of benchmarking tests we were able to run, and I mostly relied on Master Lu’s AI test. This is still around, and we’ve also used it in performance testing Apple’s new A12 neural engine. Unfortunately or the Mate 20’s, the benchmark isn’t compatible yet as it seemingly doesn’t use HiSilicon’s HiAI API on the phones, and falls back to a CPU implementation for processing.
Google had finalised the NNAPI back in Android 8.1, and how most of the time these things go, we first need an API to come out before we can see applications be able to make use of exotic new features such as dedicated neural inferencing engines.
“AI-Benchmark” is a new tool developed by Andrey Ignatov from the Computer Vision Lab at ETH Zürich in Switzerland. The new benchmark application, is as far as I’m aware, one of the first to make extensive use of Android’s new NNAPI, rather than relying on each SoC vendor’s own SDK tools and APIs. This is an important distinction to AIMark, as AI-Benchmark should be better able to accurately represent the resulting NN performance as expected from an application which uses the NNAPI.
Andrey extensive documents the workloads such as the NN models used as well as what their function is, and has also published a paper on his methods and findings.
One thing to keep in mind, is that the NNAPI isn’t just some universal translation layer that is able to magically run a neural network model on an NPU, but the API as well as the SoC vendor’s underlying driver must be able to support the exposed functions and be able to run this on the IP block. The distinction here lies between models which use features that are to date not yet supported by the NNAPI, and thus have to fall back to a CPU implementation, and models which can be hardware accelerated and operate on quantized INT8 or FP16 data. There’s also models relying on FP32 data, and here again depending on the underlying driver this can be either run on the CPU or for example on the GPU.
For the time being, I’m withholding from using the app’s scores and will simply rely on individual comparisons between each test’s inference time. Another presentational difference is that we’ll go through the test results based on the targeted model acceleration type.
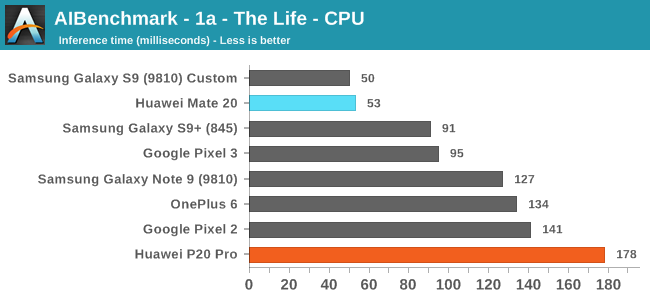

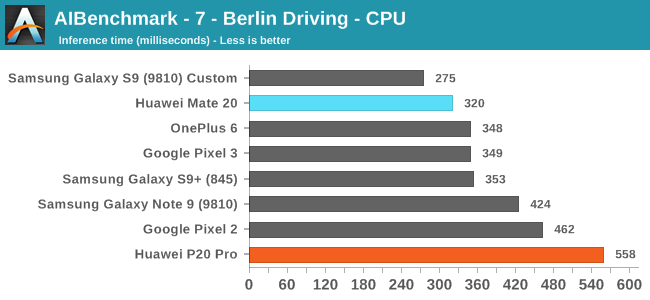
The first three CPU tests rely on models which have functions that are not yet supported by the NNAPI. Here what matters for the performance is just the CPU performance as well as the performance response time. The latter I mention, because the workload is transactional in its nature and we are just testing a single image inference. This means that mechanisms such as DVFS and scheduler responsiveness can have a huge impact on the results. This is best demonstrated by the fact that my custom kernel of the Exynos 9810 in the Galaxy S9 performs significantly better than the stock kernel of the same chip of the Note9 in the same above results.
Still, comparing the Huawei P20 Pro (most up to date software stack with Kirin 970) to the new Mate 20, we see some really impressive results of the latter. This both showcases the performance of the A76 cores, as well as possibly improvements in HiSilicon’s DVFS/scheduler.
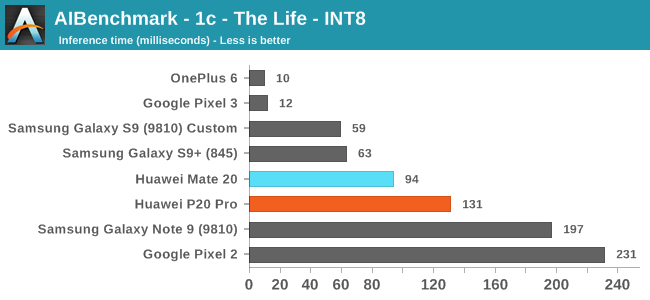
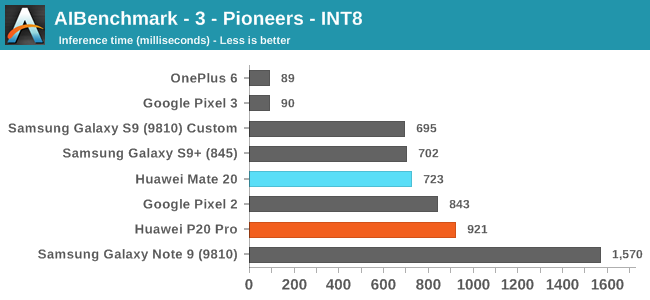
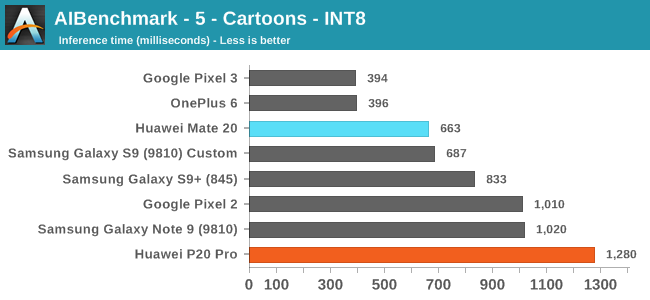
Moving onto the next set of tests, these are based on 8-bit integer quantized NN models. Unfortunately for the Huawei phones, HiSilicons NNAPI drivers still doesn’t seem to expose acceleration to the hardware. Andrey had shared with me that in communications with Huawei, is that they plan to rectify this in a future version of the driver.
Effectively, these tests also don’t use the NPU on the Kirins, and it’s again a showcase of the CPU performance.
On the Qualcomm devices, we see the OnePlus 6 and Pixel 3 far ahead in performance, even compared to the same chipset Galaxy S9+. The reason for this is that both of these phones are running a new updated NNAPI driver from Qualcomm which came along with the Android 9/P BSP update. Here acceleration if facilitated through the HVX DSPs.
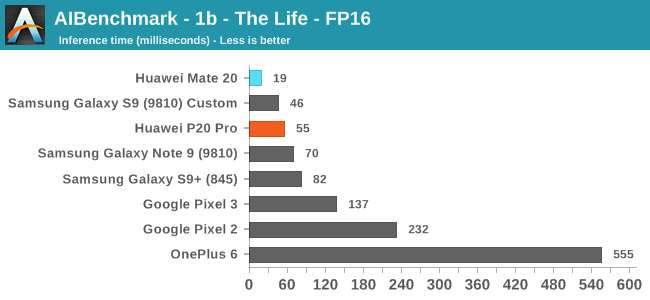
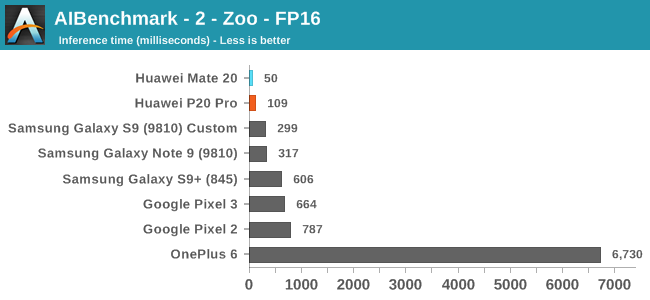

Moving on to the FP16 tests, here we finally see the Huawei devices make use of the NPU, and post some leading scores both on the old and new generation SoCs. Here the Kirin 980’s >2x NPU improvement finally materialises, with the Mate 20 showcasing a big lead.
I’m not sure if the other devices are running the workloads on the CPU or on the GPU, and the OnePlus 6 seems to suffer from some very odd regression in its NNAPI drivers that makes it perform an order of magnitude worse than other platforms.
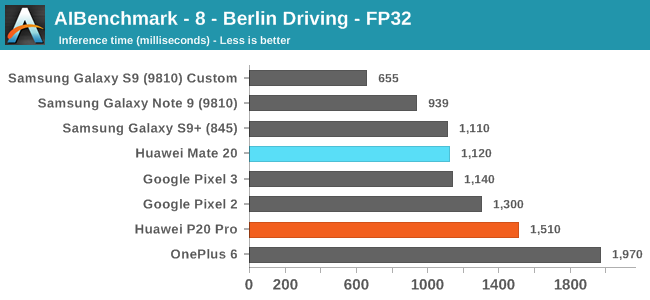
Finally on the last FP32 model test, most phones should be running the workload on the CPU again. There’s a more limited improvement on the part of the Mate 20.
Overall, AI-Benchmark was at least able to validate some of Huawei’s NPU performance claims, even though that the real conclusion we should be drawing from these results is that most devices with NNAPI drivers are currently just inherently immature and still very limited in their functionality, which sadly enough again is a sad contrast compared where Apple’s CoreML ecosystem is at today.
I refer back to my conclusion from early in the year regarding the Kirin 970: I still don’t see the NPU as something that obviously beneficial to users, simply because we just don’t have the software applications available to make use of the hardware. I’m not sure to what extent Huawei uses the NPU for camera processing, but other than such first-party use-cases, NPUs currently still seems something mostly inconsequential to device experience








141 Comments
View All Comments
Javert89 - Friday, November 16, 2018 - link
Perhaps the most interesting part is missing :( how is working (performance and power) the middle cluster at 1.92 ghz? Same performance of 2.8ghz A75 at half power usage?Andrei Frumusanu - Friday, November 16, 2018 - link
I couldn't test it without root.ternnence - Friday, November 16, 2018 - link
try syscall(__NR_sched_setaffinity, pid, sizeof(mask), &mask)ternnence - Friday, November 16, 2018 - link
FYI,https://stackoverflow.com/questions/7467848/is-it-...pjcamp - Friday, November 16, 2018 - link
If it weren't for Huawei's aggressively belligerent stance against unlocked bootloaders . . . .name99 - Friday, November 16, 2018 - link
Andrei, can you please explain something that I just do not understand in any of these phone reviews (Apple or Android).The die shots always show 4x 16-wide LPDDR4 PHYs. OK, so 64-bit wide channel to DRAM, seems reasonable.
Now the fastest normal LPDDR4 is LPDDr4-2133, which in any normal naming scheme would imply 2,133MT/s. So one transaction, 8 bytes wide, gives us guaranteed-not-to-exceed of 17GB/s.
But of course Huawei's Geekbench4 memory bandwidth is ~22GB/s. Maybe Huawei are using slightly faster LPDDr4-2166 or whatever, but the details don't change --- the only way the numbers work out is if the "maximum bandwidth" of the DRAM is actually around 34 GB/s.
Which implies that EITHER
- LPDDR4-2133 does NOT mean 2133MT/sec. (But that's what common sense would suggest, and this recent AnandTech article on DDR5
https://www.anandtech.com/show/13605/sk-hynix-deve... )
OR
- somehow there is 128-bits of width between all the high-end phone SoCs (either 2 independent 64-bit channels [more likely IMHO] or a single 128-bit wide channel).
Can you clarify?
anonomouse - Friday, November 16, 2018 - link
It’s 2133MHz IO and it’s DDR, so 4266MT/s. Each LPDDR4 channel is 16 bits. Hence the common listing of LPDDR4X-4266.Usually these are advertised/listed at the MT/s rate so DDR4-2666 has an IO clock of 1333MHz. Main difference being that DDR4 has a 64 bit channel width.
name99 - Friday, November 16, 2018 - link
But then look at the article I gave, for DDR5https://www.anandtech.com/show/13605/sk-hynix-deve...
This includes sentences like "The new DDR5 chip from SK Hynix supports a 5200 MT/sec/pin data transfer rate, which is 60% faster than the 3200 MT/s rate officially supported by DDR4."
which strongly implies that a DDR4-3200 is NOT running at 6400 MT/s.
WTF is going on here? Micron lists their LPDDR4, for example, as LPDDR4-2133, NOT as LPDDR4-4266?
N Zaljov - Sunday, November 18, 2018 - link
I fail to see any issues with the current naming convention, apart from being confusing asf."Micron lists their LPDDR4, for example, as LPDDR4-2133, NOT as LPDDR4-4266" - of course they are: https://www.micron.com/parts/dram/mobile-ddr4-sdra...
Although there seems to be a typo in the specs of their partlists, which can be confusing, but they are clearly listing their LPDDR4(x) as LPDDR4-4266 (or, typoed, LPDDR4-4166), with an I/O clk of 2133 MHz and an actual memory clockspeed of around 533,3 MHz (on-demand modulation will keep the clock of the memory arrays somewhere between 533,25 and 533,35, depending on the load).
Andrei Frumusanu - Friday, November 16, 2018 - link
The DSU's interface is limited at 2x 128bit per ACE interface to the memory subsystem/interconnect (32B/cycle in each direction) times the frequency of the DSU/L3 of which we aren't certain in the Kirin 980, but let's take the S845 which runs at 1478MHz IIRC: ~47GB/s. Plenty enough. We don't know the interconnect bandwidth from the DSU to the memory controller. The memory controllers themselves internally run at a different frequency (usually half) but what matters is talking about the DRAM speed. The Kirin 980/Mate 20's run on LPDDR4X at 2133MHz, or actually 4266MT/s because it's DDR. That's a peak of 4*16*4266/8=34.12GB/s.The actual answer is a lot simpler and more stupid. Geekbench 4's multi-threaded memory test just caps out at 2 threads, so in reality there's only ever two CPUs stressing the memory controller. Beyond this I've been told by some vendors that it doesn't scale in the test itself.
My conclusion: Ignore all the GB4 memory tests.