The iPhone XS & XS Max Review: Unveiling the Silicon Secrets
by Andrei Frumusanu on October 5, 2018 8:00 AM EST- Posted in
- Mobile
- Apple
- Smartphones
- iPhone XS
- iPhone XS Max
SPEC2006 Performance: Reaching Desktop Levels
It’s been a while now since we attempted SPEC on an iOS device – for various reasons we weren’t able to continue with that over the last few years. I know a lot of people were looking forward to us picking back up from where we left, and I’m happy to share that I’ve spent some time getting a full SPEC2006 harness back to work.
SPEC2006 is an important industry standard benchmark and differentiates itself from other workloads in that the datasets that it works on are significantly larger and more complex. While GeekBench 4 has established itself as a popular benchmark in the industry – and I do praise on the efforts on having a full cross-platform benchmark – one does have to take into account that it’s still relatively on the light side in terms of program sizes and the data sizes of its workloads. As such, SPEC2006 is much better as a representative benchmark that fully exhibits more details of a given microarchitecture, especially in regards to the memory subsystem performance.
The following SPEC figures are declared as estimates, as they were not submitted and officially validated by SPEC. The benchmark libraries were compiled with the following settings:
- Android: Toolchain: NDK r16 LLVM compiler, Flags: -Ofast, -mcpu=cortex-A53
- iOS: Toolchain: Xcode 10, Flags: -Ofast
On iOS, 429.mcf was a problem case as the kernel memory allocator generally refuses to allocate the single large 1.8GB chunk that the program requires (even on the new 4GB iPhones). I’ve modified the benchmark to use only half the amount of arcs, thus roughly reducing the memory footprint to ~1GB. The reduction in runtime has been measured on several platforms and I’ve applied a similar scaling factor to the iOS score – which I estimate to being +-5% accurate. The remaining workloads were manually verified and validated for correct execution.
The performance measurement was run in a synthetic environment (read: bench fan cooling the phones) where we assured thermals wouldn’t be an issue for the 1-2 hours it takes to complete a full suite run.
In terms of data presentation, I’m following of earlier articles this year such as the Snapdragon 845 and Exynos 9810 evaluation in our Galaxy S9 review.
When measuring performance and efficiency, it’s important to take three metrics into account: Evidently, the performance and runtime of a benchmark, which in the graphs below is represented on the right axis, growing from the right. Here the bigger the figures, the more performant a SoC/CPU has benchmarked. The labels represent the SPECspeed scores.
On the left axis, the bars are representing the energy usage for the given workload. The bars grow from the left, and a longer bar means more energy used by the platform. A platform is more energy efficient when the bars are shorter, meaning less energy used. The labels showcase the average power used in Watts, which is still an important secondary metric to take into account in thermally constrained devices, as well as the total energy used in Joules, which is the primary efficiency metric.
The data is ordered as in the legend, and colour coded by different SoC vendor as well as shaded by the different generations. I’ve kept the data to the Apple A12, A11, Exynos 9810 (at 2.7 and 2.3GHz), Exynos 8895, Snapdragon 845 and Snapdragon 835. This gives us an overview of all relevant CPU microarchitectures over the last two years.
Starting off with the SPECint2006 workloads:
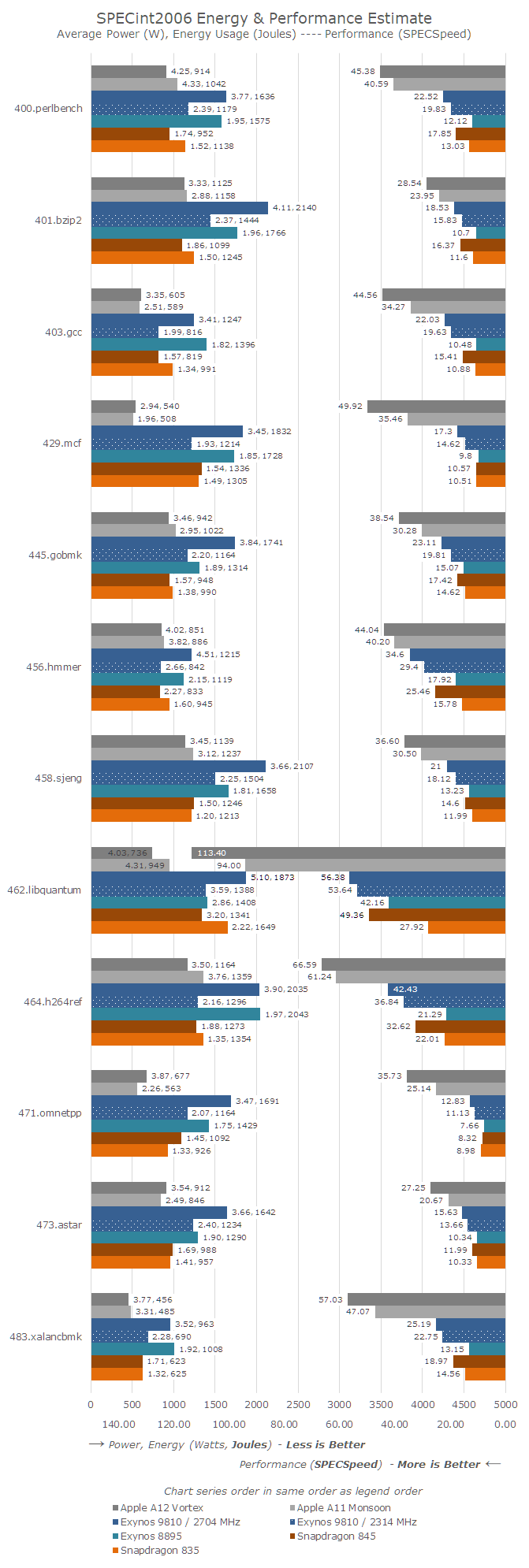
The A12 clocks in at 5% higher than the A11 in most workloads, however we have to keep in mind we can’t really lock the frequencies on iOS devices, so this is just an assumption of the runtime clocks during the benchmarks. In SPECint2006, the A12 performed an average of 24% better than the A11.
The smallest increases are seen in 456.hmmer and 464.h264ref – both of these tests are the two most execution bottlenecked tests in the suite. As the A12 seemingly did not really have any major changes in this regard, the small increase can be mainly attributed to the higher frequency as well as the improvements in the cache hierarchy.
The improvements in 445.gobmk are quite large at 27% - the characteristics of the workload here are bottlenecks in the store address events as well as branch mispredictions. I did measure that the A12 had some major change in the way stores across cache lines were handled, as I’m not seeing significant changes in the branch predictor accuracy.
403.gcc partly, and most valid for 429.mcf, 471.omnetpp, 473.Astar and 483.xalancbmk are sensible to the memory subsystem and this is where the A12 just has astounding performance gains from 30 to 42%. It’s clear that the new cache hierarchy and memory subsystem has greatly paid off here as Apple was able to pull off one of the most major performance jumps in recent generations.
When looking at power efficiency – overall the A12 has improved by 12% - but we have to remember that we’re talking about 12% less energy at peak performance. The A12 showcasing 24% better performance means were comparing two very different points at the performance/power curve of the two SoCs.
In the benchmarks where the performance gains were the largest – the aforementioned memory limited workloads – we saw power consumption rise quite significantly. So even though 7nm promised power gains, Apple's opted to spend more energy than what the new process node has saved, so average power across the totality of SPECint2006 did go up from ~3.36W on the A11 to 3.64W on the A12.
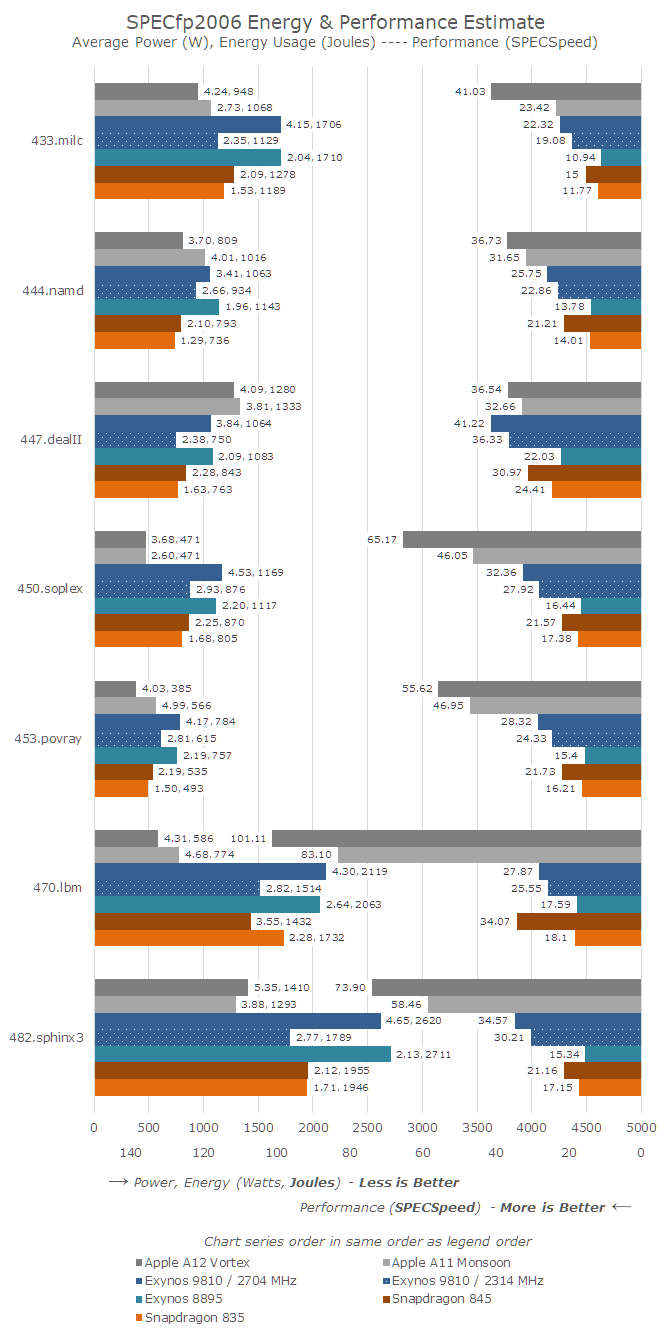
Moving on to SPECfp2006, we are looking at the C and C++ benchmarks, as we have no Fortran compiler in XCode, and it is incredibly complicated to get one working for Android as it’s not part of the NDK, which has a deprecated version of GCC.
SPECfp2006 has a lot more tests that are very memory intensive – out of the 7 tests, only 444.namd, 447.dealII, and 453.povray don’t see major performance regressions if the memory subsystem isn’t up to par.
Of course this majorly favours the A12, as the average gain for SPECfp is 28%. 433.milc here absolutely stands out with a massive 75% gain in performance. The benchmark is characterised by being instruction store limited – again part of the Vortex µarch that I saw a great improvement in. The same analysis applies to 450.soplex – a combination of the superior cache hierarchy and memory store performance greatly improves the perf by 42%.
470.lbm is an interesting workload for the Apple CPUs as they showcase multi-factor performance advantages over competing Arm and Samsung cores. Qualcomm’s Snapdragon 820 Kryo CPU oddly enough still outperforms the recent Android SoCs. 470.lbm is characterised by extremely large loops in the hottest piece of code. Microarchitectures can optimise such workloads by having (larger) instruction loop buffers, where on a loop iteration the core would bypass the decode stages and fetch the instructions from the buffer. It seems that Apple’s microarchitecture has some kind of such a mechanism. The other explanation is also the vector execution performance of the Apple cores – lbm’s hot loop makes heavy use of SIMD, and Apple’s 3x execution throughput advantage is also likely a heavy contributor to the performance.
Similar to SPECint, the SPECfp workload which saw the biggest performance jumps also saw an increase in their power consumption. 433.milc saw an increase from 2.7W to 4.2W, again with a 75% performance increase.
Overall the power consumption has seen a jump from 3.65W up to 4.27W. The overall energy efficiency has increased in all tests but 482.sphinx3, where the power increase hit the maximum across all SPEC workloads for the A12 at 5.35W. The total energy used for SPECfp2006 for the A12 is 10% lower than the A11.
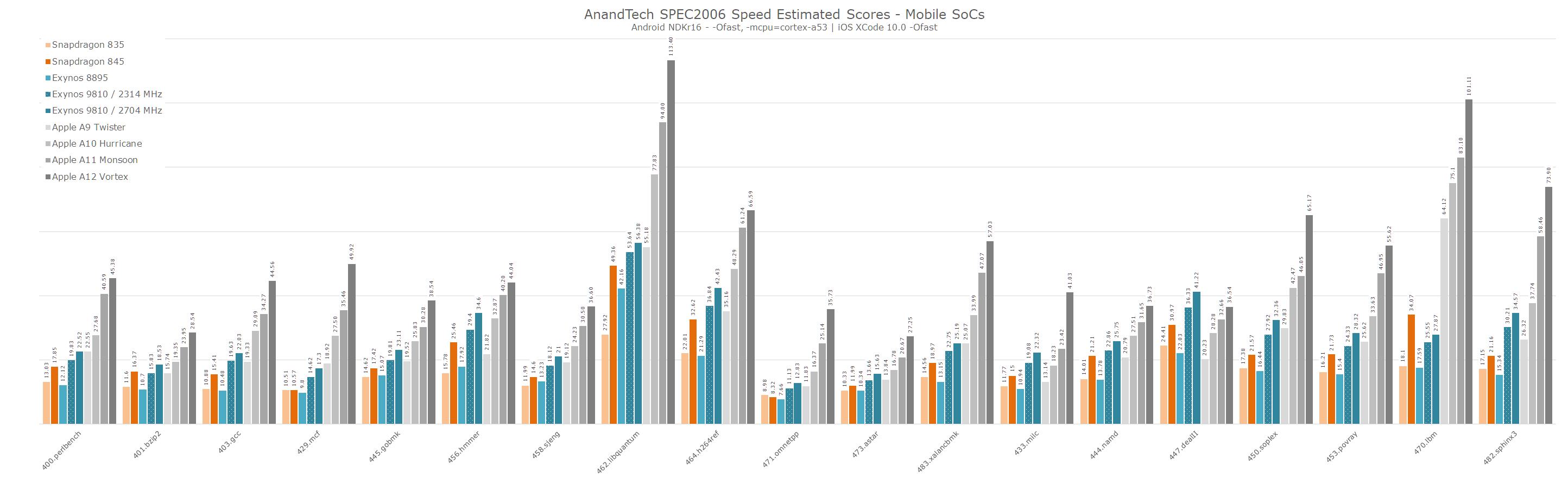
I didn’t have time to go back and measure the power for the A10 and A9, but generally they’re in line around 3W for SPEC. I did run the performance benchmarks, and here’s an aggregate performance overview of the A9 through to the A12 along with the most recent Android SoCs, for those who are looking into comparing past Apple generations.
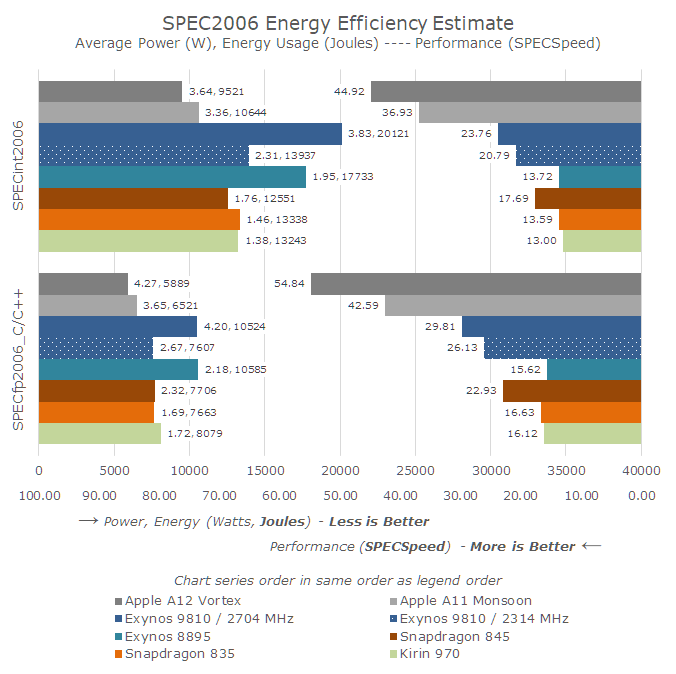
Overall the new A12 Vortex cores and the architectural improvements on the SoC’s memory subsystem give Apple’s new piece of silicon a much higher performance advantage than Apple’s marketing materials promote. The contrast to the best Android SoCs have to offer is extremely stark – both in terms of performance as well as in power efficiency. Apple’s SoCs have better energy efficiency than all recent Android SoCs while having a nearly 2x performance advantage. I wouldn’t be surprised that if we were to normalise for energy used, Apple would have a 3x performance lead.
This also gives us a great piece of context for Samsung’s M3 core, which was released this year: the argument that higher power consumption brings higher performance only makes sense when the total energy is kept within check. Here the Exynos 9810 uses twice the energy over last year’s A11 – at a 55% performance deficit.
Meanwhile Arm’s Cortex A76 is scheduled to arrive inside the Kirin 980 as part of the Huawei Mate 20 in just a couple of weeks – and I’ll be making sure we’re giving the new flagship a proper examination and placing among current SoCs in our performance and efficiency graph.
What is quite astonishing, is just how close Apple’s A11 and A12 are to current desktop CPUs. I haven’t had the opportunity to run things in a more comparable manner, but taking our server editor, Johan De Gelas’ recent figures from earlier this summer, we see that the A12 outperforms a moderately-clocked Skylake CPU in single-threaded performance. Of course there’s compiler considerations and various frequency concerns to take into account, but still we’re now talking about very small margins until Apple’s mobile SoCs outperform the fastest desktop CPUs in terms of ST performance. It will be interesting to get more accurate figures on this topic later on in the coming months.








253 Comments
View All Comments
Constructor - Monday, October 8, 2018 - link
Sure you can – just go to airplane mode and re-enable WiFi.s.yu - Monday, October 8, 2018 - link
In the third and fifth low light sample I think it's pretty clear that the XS beat the P20P, again P20P's retention of texture is horrible and only in extreme low light (second and last sample) and scenes with many man-made objects which lack obvious texture (third sample) does its excessive sharpening and NR have a advantage. The first sample is a surprise, there either the scene is actually darker than I'm lead to believe or there's something else I've not taken into account.daiquiri - Monday, October 8, 2018 - link
Isn't this a too bold affirmation that A12 is on par with current desktop CPUs? So why didn't we stack them in order to have 5x the processing power of a common laptop/workstation for 1/2 of the power? What am I missing here? Because this doesn't make much sense to me.If I have 2 or 3 of these SoC chips and photoshop running on them will I have my filters running faster? Chrome loading webpages faster? Creating zip archives or converting flac files 3x times faster than an Intel I7?
resiroth - Monday, October 8, 2018 - link
There is widespread speculation (and at this point, it is considered more likely than not) that apple will transition to their own chips exclusively for their Mac products in the near future (within 2 years).What exactly doesn’t make sense to you?
Ps: will be very interesting to see results of new iPad Pro this year too.
daiquiri - Monday, October 8, 2018 - link
What is strange to me is why aren't we already stacking this SoCs. I suppose I can fit 6 or 8 of these processors on the same die size. This means I would have a lot faster PC for less power? It they are that great why aren't on desktops already?Does this mean if I manage to install Windows 10 ARM edition on my PC photoshop will run faster and Chrome will load pages two or three times faster since I have 8 of these SoCs on my desktop pc?
Constructor - Wednesday, October 10, 2018 - link
Because just increasing the core count is not quite enough.As I have explained above, a platform transition is a massive undertaking which among many other things needs actually superior performance to afford the initially still necessary legacy code emulation.
This will almost certainly start at a WWDC (next year or the year after that, most likely) with an announcement about not just coming hardware but also about those new mechanisms in macOS itself, and actual Axx-powered Macs may take months after that to emerge while developers start porting their code to the new platform.
It's not as if this was the first time for Apple – they've done it twice already!
varase - Tuesday, October 23, 2018 - link
Yeah, but they always went to a *much* faster CPU to do the emulation.Constructor - Wednesday, October 24, 2018 - link
Even just the iPhone cores right now are already at about a desktop i5 level according to GeekBench.There should be quite some room for upscaling with more power and better cooling.
tipoo - Wednesday, October 24, 2018 - link
These cores are 30% larger than Intels, let that sink in.I'm sure 8 of them would perform marvellously, for the cost. And it may be coming.
Zoolook - Tuesday, October 9, 2018 - link
I just pulled an old test of a i3-6320, a 3 year old dual-core, and the A12 does good on some of the tests, but in many tests it's quite a bit behind, so it's not ready for server-duty yet.I know that the i3 has higher frequencies but it's also only two cores, compared to 2+4.
There is no question that the big cores are very efficient, but they are optimized for their current job.
If Apple would build a 6- or 8-core processor based on their large cores and throw away most of the other SoC and add other parts (stronger SIMD etc), yes then we might have a good desktop/serverchip, but the A12 is not that chip.
Also remember that we are comparing 14nm Intel chips with the newest "7nm" process, if Intel ever gets their 10nm process up and running for real, then we could do a better comparison.