The iPhone XS & XS Max Review: Unveiling the Silicon Secrets
by Andrei Frumusanu on October 5, 2018 8:00 AM EST- Posted in
- Mobile
- Apple
- Smartphones
- iPhone XS
- iPhone XS Max
System Performance
While synthetic test performance is one thing, and hopefully we’ve covered that well with SPEC, interactive performance in real use-cases behaves differently, and here software can play a major role in terms of the perceived performance.
I will openly admit that our iOS system performance suite looks extremely meager: we are only really left with our web browser tests, as iOS is quite lacking in meaningful alternatives such as to PCMark on the Android side.
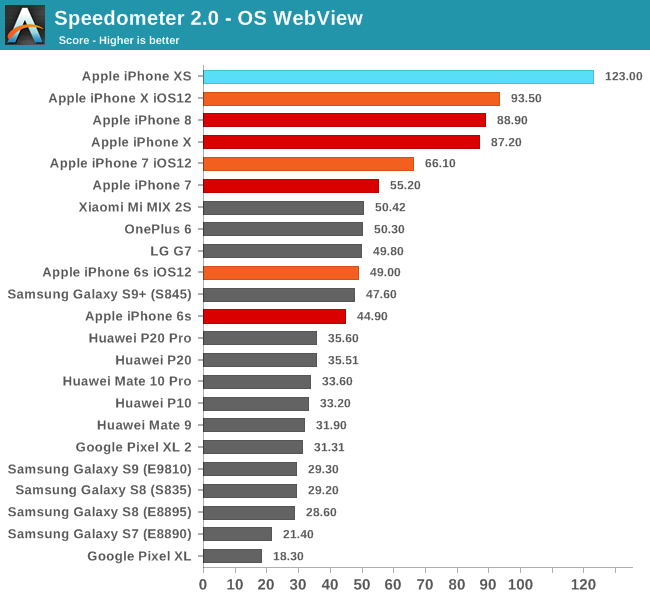
Speedometer 2.0 is the most up-to-date industry standard JavaScript benchmark which tests the most common and modern JS framework performance.
The A12 sports a massive jump of 31% over the A11, again pointing out that Apple’s advertised performance figures are quite underselling the new chipset.
We’re also seeing a small boost from iOS 12 on the previous generation devices. Here the boost comes not only thanks to an a change in how iOS’s scheduler handles load, but also thanks to further improvements in the ever evolving JS engine that Apple uses.
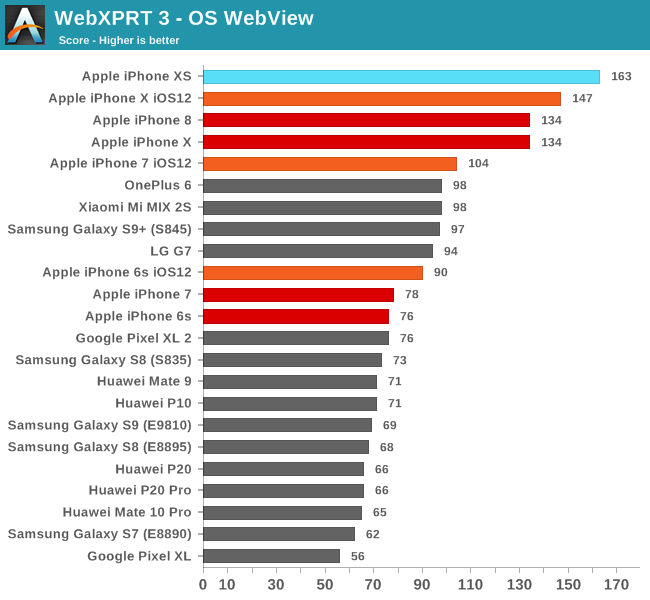
WebXPRT 3 is also a browser test, however its workloads are more wide-spread and varied, containing also a lot of processing tests. Here the iPhone XS showcases a smaller 11% advantage over the iPhone X.
Former devices here also see a healthy boost in performance, with the iPhone X ticking up from 134 to 147 points, or 10%. The iPhone 7’s A10 sees a larger boost of 33%, something we’ll get into more detail in a little bit.
iOS12 Scheduler Load Ramp Analyzed
Apple promised a significant performance improvement in iOS12, thanks to the way their new scheduler is accounting for the loads from individual tasks. The operating system’s kernel scheduler tracks execution time of threads, and aggregates this into an utilisation metric which is then used by for example the DVFS mechanism. The algorithm which decides on how this load is accounted over time is generally simple a software decision – and it can be tweaked and engineered to whatever a vendor sees fit.
Because iOS’s kernel is closed source, we’re can’t really see what the changes are, however we can measure their effects. A relatively simple way to do this is to track frequency over time in a workload from idle, to full performance. I did this on a set of iPhones ranging from the 6 to the X (and XS), before and after the iOS12 system update.
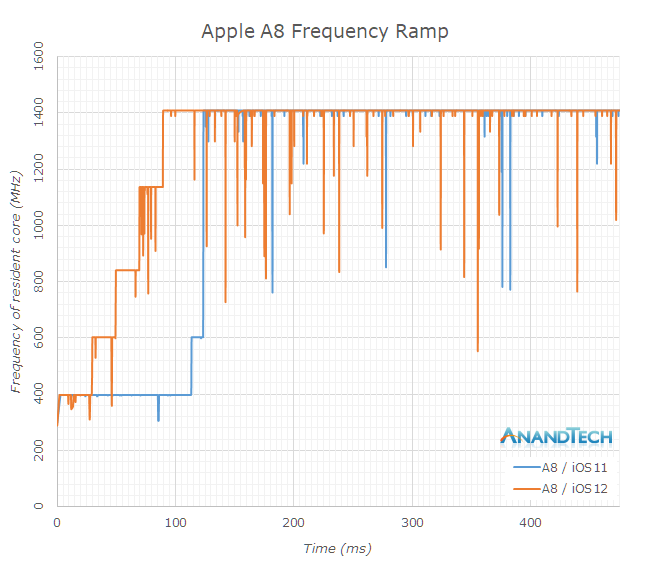
Starting off with the iPhone 6 with the A8 chipset, I had some odd results on iOS11 as the scaling behaviour from idle to full performance was quite unusual. I repeated this a few times yet it still came up with the same results. The A8’s CPU’s idled at 400MHz, and remained here for 110ms until it jumped to 600MHz and then again 10ms later went on to the full 1400MHz of the cores.
iOS12 showcased a more step-wise behaviour, scaling up earlier and also reaching full performance after 90ms.
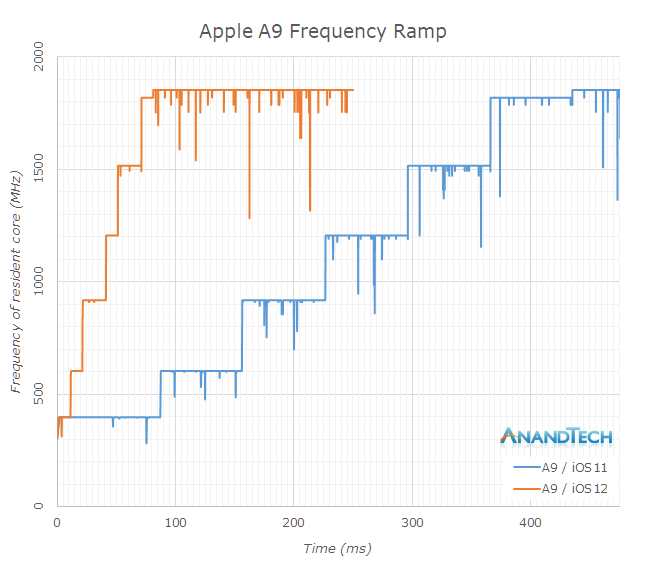
The iPhone 6S had a significantly different scaling behaviour on iOS11, and the A9 chip’s DVFS was insanely slow. Here it took a total of 435ms for the CPU to reach its maximum frequency. With the iOS12 update, this time has been massively slashed down to 80ms, giving a great boost to performance in shorter interactive workloads.
I was quite astonished to see just how slow the scheduler was before – this is currently the very same issue that is handicapping Samsung’s Exynos chipsets and maybe other Android SoCs who don’t optimise their schedulers. While the hardware performance might be there, it just doesn’t manifest itself in short interactive workloads because the scheduler load tracking algorithm is just too slow.
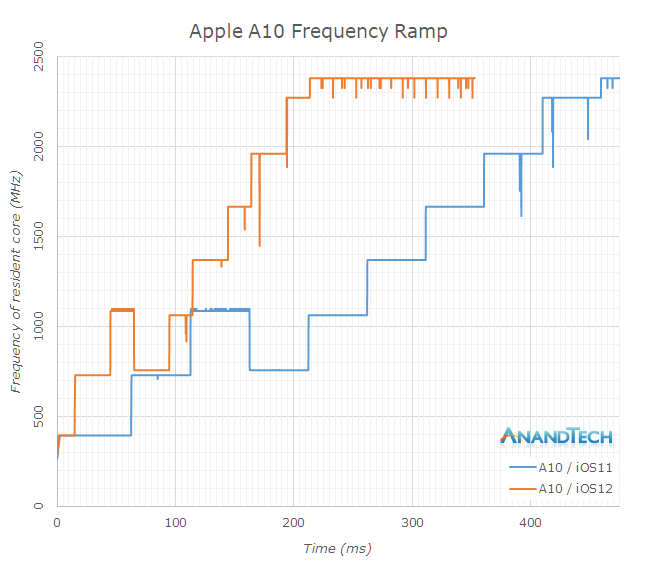
The A10 had similar bad characteristics as the A9, with time to full performance well exceeding 400ms. In iOS12, the iPhone 7 slashes this roughly in half, to around 210ms. It’s odd to see the A10 being more conservative in this regard compared to the A9 – but this might have something to do with the little cores.
In this graph, it’s also notable to see the frequency of the small cores Zephyr cores – they start at 400MHz and peak at 1100MHz. The frequency in the graph goes down back to 758MHz because at this point there was a core switch over to the big cores, which continue their frequency ramp up until maximum performance.
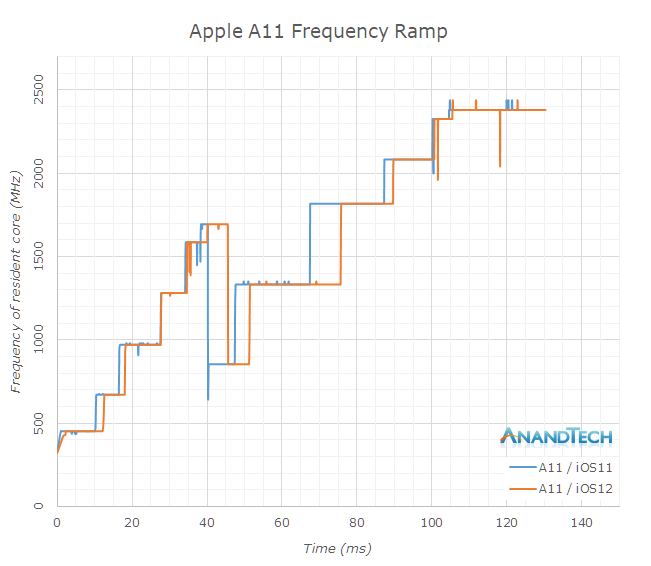
On the Apple A11 – I didn’t see any major changes, and indeed any differences could just be random noise between measuring on the different firmwares. Both in iOS11 and iOS12, the A11 scales to full frequency in about 105ms. Please note the x-axis in this graph is a lot shorter than previous graphs.
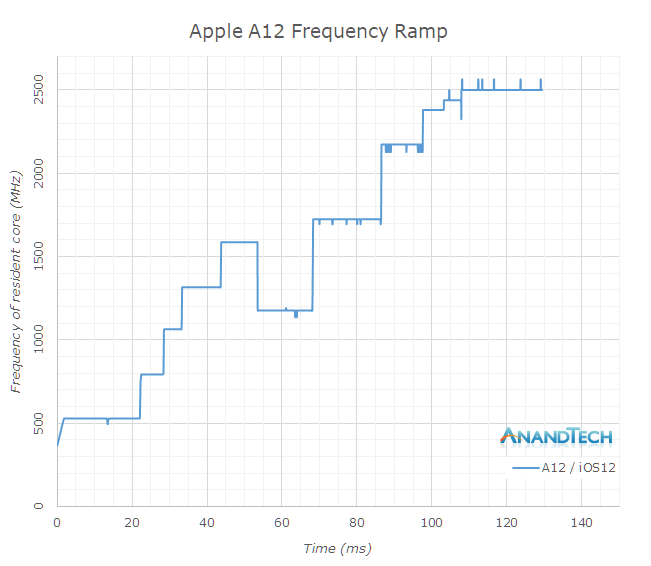
Finally on the iPhone XS’s A12 chipset, we can’t measure any pre- and post- update as the phone comes with iOS12 out of the box. Here again we see that it reaches full performance after 108ms, and we see the transition of the tread from the Tempest cores over to the Vortex cores.
Overall, I hope this is the best and clear visual representation of the performance differences that iOS12 brings to older devices.
In terms of the iPhone XS – I haven’t had any issues at all with performance of the phone and it was fast. I have to admit I’m still a daily Android user, and I use my phones with animations completely turned off as I find they get in the way of the speed of a device. There’s no way to completely turn animation off in iOS, and while this is just my subjective personal opinion, I found they are quite hampering the true performance of the phone. In workloads that are not interactive, the iPhone XS just blazed through them without any issue or concern.








253 Comments
View All Comments
Andrei Frumusanu - Friday, October 5, 2018 - link
Pixels and Mate 20 are next in line.name99 - Friday, October 5, 2018 - link
Hi Andrei,A few comments/questions.
- the detailed Vortex and GPU die shots seem to bear no resemblance to the full SoC die shot. I cannot figure out the relationship no matter how I try to twist and reflect...
Because I can't place them, I can't see the physical relationship of the "new A10 cache" to the rest of the SoC. If it's TIGHTLY coupled to one core, one possibility is value prediction? Another suggested idea that requires a fair bit of storage is instruction criticality tracking.
If it's loosely coupled to both cores, one possibility is it's a central repository for prefetch? Some sort of total prefetching engine that knows the usage history of the L1s AND L2s and is performing not just fancy prefetch (at both L1s and L2s) but additional related services like dead block prediction or drowsiness prediction?
Andrei Frumusanu - Friday, October 5, 2018 - link
The Vortex and GPU are just crops of the die shot at the top of the page. The Vortex shot is the bottom core rotated 90° counter-clockwise, and the GPU core is either top left or bottom right core, again rotated 90° ccw so that I could have them laid out horizontally.The "A10 cache" has no relationship with the SoC, it's part of the front-end.
name99 - Friday, October 5, 2018 - link
OK, I got ya. Thanks for the clarification. I agree, no obvious connection to L2 and the rest of the SoC. So value prediction or instruction criticality? VP mostly makes sense for loads, so we'd expect it near LS, but criticality makes sense near the front end. It's certainly something I'm partial to, though it's been mostly ignored in the literature compared to other topics. I agree it's a long shot, but, like you said, what else is that block for?name99 - Friday, October 5, 2018 - link
"The benchmark is characterised by being instruction store limited – again part of the Vortex µarch that I saw a great improvement in."Can you clarify this? There are multiple possible improvements.
- You state that A12 supports 2-wide store. The impression I got was that as of A11, Apple supported the fairly tradition 2-wide load/1-wide store per cycle. Is your contention that even as of A11, 2 stores/cycle were possible? Is there perhaps an improvement here along the lines of: previously the CPU could sustain 3 LS ops/cycle (pick a combination from up to 2 loads and up to 2 stores) and now it can sustain 4 LS ops/cycle?
- Alternatively, are the stores (and loads) wider? As of A11, the width of one path to the L1 cache was 128 bits wide. It was for this reason that bulk loads and stores could run as fast using pair load-store integer as using vector load stores (and there was no improvement in using the multi-vector load-stores). When I spoke to some Apple folks about this, the impression I got was that they were doing fancy gathering in the load store buffers before the cache, and so there was no "instruction" advantage to using vector load/stores, whatever instruction sequence you ran, it would as aggressively and as wide as possible gather before hitting the cache. So if the LS queue is now gathering to 256 bits wide, that's going to give you double the LS bandwidth (of course for appropriately written, very dense back to back load/stores).
- alternatively do you simply mean that non-aligned load/stores are handled better (eg LS that crossed cache lines were formerly expensive and now are not)? You'd hope that code doesn't do much of these, but nothing about C-code horrors surprises me any more...
BTW, it's hard to find exactly comparable numbers, but
https://www.anandtech.com/show/11544/intel-skylake...
shows the performance of a range of different server class CPUs on SPEC2006 INT, compiled under much the same conditions. A12 is, ballpark, about at the level of Skylake-SP at 3.8 to 4GHz...
(Presumably Skylake would do a lot better in *some* FP bcs of AVX512, but FP results aren't available.) This gives insight across a wider range of x86 servers than the link Andrei provided.
The ideal would be to have SPEC2006 compiled using XCode for say the newest iMac and iMac Pro, and (for mobile space) MacBook Pro...
Andrei Frumusanu - Friday, October 5, 2018 - link
> Is your contention that even as of A11, 2 stores/cycle were possible?Yes.
> - Alternatively, are the stores (and loads) wider?
Didn't verify, and very unlikely.
> - alternatively do you simply mean that non-aligned load/stores are handled better
Yes.
remedo - Friday, October 5, 2018 - link
Can you please review the massive NPU? It seems like NPU deserves a lot more attention given the industry trend.Andrei Frumusanu - Friday, October 5, 2018 - link
I don't have any good way to test it at the moment.Ansamor - Friday, October 5, 2018 - link
Aren't these (https://itunes.apple.com/es/app/aimark/id137796825... tests cross-platform or comparable with the ones of Master Lu? I remember that you used it to compare the Kirin 970 against the Qualcomm DSP.Andrei Frumusanu - Friday, October 5, 2018 - link
Wasn't aware it was available on iOS, I'll look into it.