Arm Announces Mali-G76 GPU: Scaling up Bifrost
by Ryan Smith & Andrei Frumusanu on May 31, 2018 3:00 PM ESTThe Mali G76 - Scaling It Up
Section by Ryan Smith
Mali-G76 is an interesting change for Arm’s GPU designs, both because it changes some fundamental aspects of the Bifrost architecture, and yet it doesn’t.
At a very high level, there are no feature changes with respect to graphics, and only some small changes when it comes to compute (more on that in a moment). So there is little to talk about with regards here in terms of end-user functionality or flashy features. Bifrost was already a modern graphics architecture, and the state of 3D graphics technology hasn’t significantly changed in the last two years to invalidate that.
Instead, like Mali-G72 before it, G76 is another optimization pass on the underpinnings of the architecture. And compared to G72, G76 is a much greater pass that as a result makes some significant changes in how Arm’s GPUs work. It’s still very much the Bifrost architecture, but it’s actually one of the biggest changes we’ve ever seen within a single graphics architecture from one revision to the next, and that goes for both mobile and PC.
The big change here is that in an effort to further boost the performance and area efficiency of the architecture, Arm is doubling the width of their fundamental compute block, the “quad” execution engine. In both the Mali-G71 and G72, a quad is just that: a 4-wide SIMD unit, with each lane possessing separate FMA and ADD/SF pipes. Fittingly, the width of a wavefront at the ISA-level for these parts has also been just 4 instructions, meaning all of the threads within a wavefront are issued in a single cycle. Overall, Bifrost’s use of a 4-wide design was a notably narrow choice relative to most other graphics architectures.
But the quad is a quad no longer. For Mali-G76, Arm is going big. The eponymous quad is now an 8-wide SIMD. In other words, a Mali-G76 quad – and for that matter an entire core – now has twice as many ALUs as before. All of the features are the same, as is the execution model within a quad, but now Arm can weave together and execute 8 threads per clock per quad versus 4 on past Bifrost parts.

This is a very interesting change because, simply put, the size of a wavefront is typically a defining feature of an architecture. For long-lived architectures, especially in the PC space, wavefront sizes haven’t changed for years. NVIDIA has used a 32-wide wavefront(warp) going all the way back in G80 in 2006, and AMD’s 64-wide wavefront goes back to the pre-GCN days. As a result this is the first time we have seen a vendor change the size of their wavefron in the middle of an architectural generation.
Now there are several ramifications of this, both for efficiency purposes and coding purposes. But before going too far, I want to quickly recap part of our Mali-G71 article from 2016, discussing the rationale for Arm’s original 4-wide wavefront design.
Moving on, within the Bifrost architecture, ARM’s wavefronts are called Quads. True to the name, these are natively 4 threads wide, and a row of instructions from a full quad is executed per clock cycle. Bifrost’s wavefront size is particularly interesting here, as quads are much smaller than competing architectures, which are typically in the 16-32 thread range. Wavefront design in general reflects the need to find a balance between resource/area density and performance. Wide wavefronts require less control logic (ex: 32 threads with 1 unit of control logic, versus 4x8 threads with 8 units of control logic), but at the same time the wider the wavefront, the harder it is to fill.ARM’s GPU philosophy in general has been concerned with trying to avoid execution stalls, and their choice in wavefront size reflects this. By going with a narrower wavefront, a group of threads is less likely to diverge – that is, take different paths, typically as a result of a conditional statement – than a wider wavefront. Divergences are easy enough to handle (just follow both paths), but the split hurts performance.
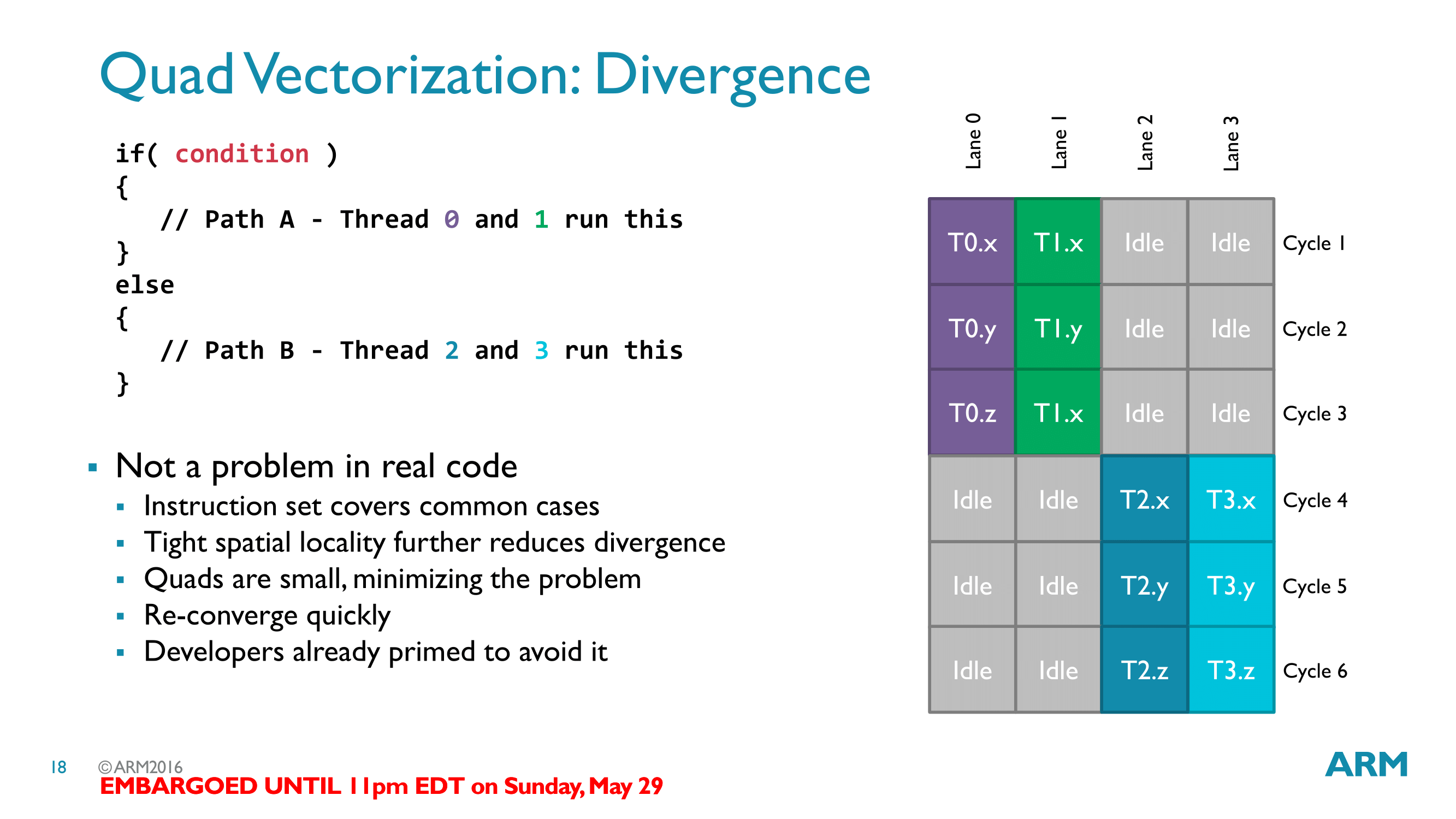
At the time, Arm said that they went with a 4-wide wavefront in order to minimize the occurrence of idle ALUs from thread divergence. On paper this is a sound strategy, as if you’re expecting a lot of branching code, then those ALUs are doing nothing of value for you if they’re idle due to thread divergence. A great deal of effort goes into balancing an architecture design around this choice, and particularly in the PC space, once you choose a size you’re essentially stuck with it as developers will optimize against this.
However the trade-off for a narrow wavefront and the resulting SIMDs is that the ratio of control logic to ALUs is quite a bit higher. Every SIMD is supported by a mix of cache, dispatch control hardware, internal datapaths, and other hardware. The size of this logic is somewhat fixed due to its functionality, so a wider SIMD doesn’t require much of an increase in the size of the supporting hardware. And it’s this trade-off that Arm is targeting for Mali-G76.
The net result of switching to an 8-wide SIMD design here is that Arm is decreasing the control logic to ALU ratio – or perhaps it’s better said that they’re increasing the ratio of ALUs to control logic. In the case of G76, for example, despite doubling the lanes and theoretical throughput of an execution engine, the resulting block is only about 28% larger than one of Mali-G72’s engines. Scale this up over an entire GPU, and you can easily see how this can be a more area-efficient option.

Though not explicitly said by Arm in their briefings, our interpretation of this change is that it’s a bit of an admittance that the 4-wide design of the original Bifrost architecture was overzealous; that thread divergence in real-world code isn’t high enough to justify the need for such a narrow SIMD. For their part, Arm did confirm that they see the granularity requirements of GPU code (games and compute alike) being different than what they were when G71 launched. And in the meantime this also helps Arm’s scalability efforts, as the more area-dense quad design means that Arm can pack more of them in the same die space, getting a larger number of ALUs per mm2 overall.
This change also brings the Mali-G7x GPUs in-line with the Mali-G52, which uses the same 8-wide SIMD design and was launched by Arm in a more low-key manner back in March of this year. So while G76 is technically the second Arm GPU design announced with this change, it’s been our first real chance to sit down with Arm and see what they’re thinking.
It goes without saying then that we’re curious to see what the real-world performance impacts of this change are like. Given just how uncommonly narrow Arm’s quads were, it should be pretty easy to similarly fill an 8-wide SIMD design, and in that respect, I suspect Arm is right about wider being a better choice. However wider designs do require some smarter compiler programming in order to ensure you can keep the wider SIMDs similarly filled, so Arm’s driver team has a part to play in all of this as well.
Thankfully for Arm, the mobile market is not nearly as bound to wavefront size as the PC market is, which allows for Arm to get away with a mid-generation change like this. Developers aren’t writing customized code specifically for Arm’s GPUs in the way they are in the PC space, rather everything is significantly abstracted (and overall left rather generic) through OpenGL ES, Vulkan, and other graphics/compute APIs. So for mobile developers and for existing game/application binaries, this underlying change should be completely hidden by the combination of APIs and Arm’s drivers.
As an aside, doubling the number of SIMD lanes within a quad has also led Arm to double the relevant supporting cache and pathways as well. While Arm doesn’t officially disclose the size of a quad’s register file, they have confirmed that there are 64 registers per lane for G76’s register file, just like there was for Mali-G72. So on a relative basis, register file pressure is unchanged.

Fittingly, Arm has also doubled the throughput of their pixel and texel hardware to keep up with the wider quads. A single core can now spit out 2 texels and 2 pixels per clock, maintaining the same ALU/texture and ALU/pixel ratios as before. To signify this on the Mali-G76, Arm now calls this their “Dual Texture Unit”, as opposed to the single “Texture Unit” on G72 and G71.

The end result of all of this, as Andrei once put it, is that in a sense Arm has smashed together two Mali-G72 cores together to make a single G76 core. At equal clockspeeds compute, texture, and pixel throughput have all been doubled, and on paper will result in virtually identical performance. However the benefit to Arm is that this design takes up a lot less space than two whole cores; Arm essentially gets the same per-clock performance in about 66% of the die area of an equivalent G72 design, greatly boosting their area efficiency, an always important metric for the silicon integrators who bring Arm’s GPU designs to life.








25 Comments
View All Comments
ET - Monday, June 4, 2018 - link
How 'significantly cheaper' would you expect such a card to be compared to a $70 discrete GPU?Based on the expected GFXBench score and further extrapolation, the G76MP20 could perform about the same as the 1030, and it's possible that it could work with slower RAM and save there, but still, I don't see how it could be a really successful or high margin product. There would be need for a complete product line reaching significantly higher performance to make this more than a curiosity.
eastcoast_pete - Monday, June 4, 2018 - link
I would really appreciate if you could provide a link to a vendor's site that lists a 1030 card for $ 70. The cheapest I have seen them was for ~ $ 120. If I can get one for $ 70 - we have a deal, even if it is the even further throttled DDR4 version. $ 70 is about what that card is really worth.Unrelated to this: My question arose from a situation I believe a number of us have: a HTPC that's otherwise Ok (in my case, around a Haswell i5), but cannot for the life of it decode 2160p HEVC at 30 fps or faster. If nothing else, a 1030 class card does at least have HDMI 2.0 out. For a new build, I would probably give the Ryzen 2400G a spin.
ET - Wednesday, June 6, 2018 - link
I think I can post again. Spam filter blocked me yesterday from posting anything at all. I'll try the part without dollar signs first.If you just want video, why would you need a GeForce 1030 level GPU? Video is a different ARM IP anyway, not part of the G76.
I do see a small market for a very low power USB GPU that's simply a mobile CPU with some low power RAM. All that basically needs is drivers, and preferably BIOS support. That would allow for example creating Ryzen based PCs without having to stick a GPU in the case, and would work for people like you with old hardware who want support for newer standards, including for laptop owners who want video out and for whom a GPU upgrade is impractical.
ET - Wednesday, June 6, 2018 - link
Okay, now for the tricky part.I indeed see that the 1030 has gone up in price. I can find it for $ 90 at Amazon and Newegg, so it's not as bad as you say, and there's a DDR4 version for $ 77, which may be okay if what you're looking for is video playback and not 3D performance. However, I don't think a G76 part would solve the GPU market prices problem. If it's good enough, its price will go up like the rest of them. If it's not, its market share will be rather small. I think (as I posted in the other part) that a low power USB card would have a larger market. It would be a more convenient add-on, which could be applied to more configurations.
darkich - Friday, June 1, 2018 - link
16.9fps/W vs 11.9fps/W (Snapdragon 845), and you "don't think it will catch up with the competition".vladx - Friday, June 1, 2018 - link
Indeed the author/s seem quite biased.Andrei Frumusanu - Saturday, June 2, 2018 - link
There's a process node difference between that comparison. An eventual Snapdragon 855 will surpass it.vladx - Saturday, June 2, 2018 - link
Jumping to such conclusions doesn't sit well with being an impartial party.jospoortvliet - Monday, June 4, 2018 - link
Oh come on you think they should assume the next snapdragon is not improved to be seen as impartial?They point out that the projection is that this MALI will be 15% faster than the current snapdragon. But it comes out next year and this will have to compete with the next snapdragon, not the 845. Totally sane to point out that given their history it seems a stretch to same that Qualcomm will only improve their new high end SOC by 15% or less...
jospoortvliet - Monday, June 4, 2018 - link
Same -> assume